volcano专题

科研绘图系列:R语言富集火山图和通路图(volcano plot pathway)
介绍 火山图是一种用于可视化基因表达差异的分析工具,它通过二维坐标系展示基因的表达量变化和统计显著性。该图谱的x轴表示基因表达的对数变化,而y轴表示其统计显著性。利用火山图,研究者能够快速识别出在不同条件下显著差异表达的基因。 随后,通过KEGG数据库提供的通路图,研究者可以进一步分析这些差异表达基因在生物学通路中的富集情况。KEGG数据库是一个包含丰富基因和蛋白质信息的资源,涵盖了代谢、
k8s volcano + deepspeed多机训练 + RDMA ROCE+ 用户权限安全方案【建议收藏】
前提:nvidia、cuda、nvidia-fabricmanager等相关的组件已经在宿主机正确安装,如果没有安装可以参考我之前发的文章GPU A800 A100系列NVIDIA环境和PyTorch2.0基础环境配置【建议收藏】_a800多卡运行环境配置-CSDN博客文章浏览阅读1.1k次,点赞8次,收藏16次。Ant系列GPU支持 NvLink & NvSwitch,若您使用多GPU卡的机型,

Flink SQL 之 Calcite Volcano优化器(源码解析)
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析 同时想要深入研究Flink sql源码的话calcite也是必备技能之一,非常值得学习 我们内部也通过它在做自研的sql引擎,通过一套sql支持关联查询任意多个异构数据源(eg : mysql表join上 hbase表在做一个聚合计算) 因为calcite功能比

智算AI平台介绍:初识volcano
提到智算AI平台,肯定离不了Volcano,Volcano与Kubernetes天然兼容,并为高性能计算而生。 一.volcano是什么 Volcano是CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。 它提供了Kubernetes目前缺少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种高性能工作负载所需的。 作为一个通用

智算AI平台介绍:Volcano的Queue
上一篇提到,Volcano涉及了三个重要的功能--Queue,Podgroup, VCjob; 今天主要介绍的的Queue! Queue属于资源级别的对象,可声明资源配额,多个namespace共享。一般一个算法部门对应一个volcano queue Queue是容纳一组podgroup的队列,podgroup里面都是pod。 Queue 用于管理和优先级排序任务。 这有助于更好地控制资
Volcano 资源预留特性
文章目录 简介场景分析特性设计目标作业识别资源预留算法 最佳实践 Volcano是一个基于Kubernetes的云原生批量计算平台,也是CNCF的首个批量计算项目。 Volcano 主要用于AI、大数据、基因、渲染等诸多高性能计算场景,对主流通用计算框架均有很好的支持。它提供高性能计算任务调度,异构设备管理,任务运行时管理等能力。本篇文章将深度剖析Volcano重要特
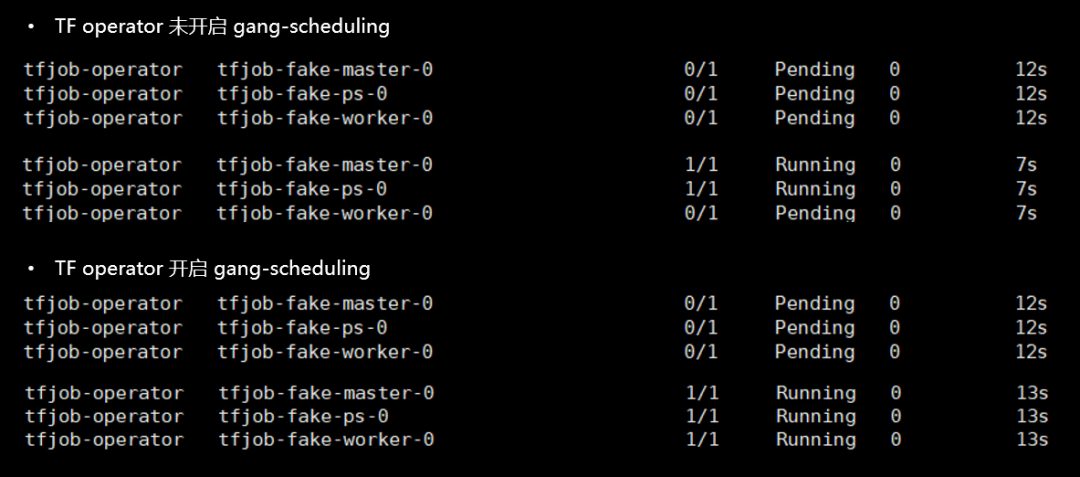
6-机器学习场景下Volcano集成调度能力实践
6-机器学习场景下Volcano集成调度能力实践 今天主要给大家分享如何使用Volcano调度器运行一个TF Job。 今天的分享主要包括3个部分的内容: Kubeflow简介Kubeflow on Volcano演示(运行一个简单的机器学习作业) 01 Kubeflow简介 • Kubeflow是Kubernetes的机器学习工具包,是运行在K8s之上的一套技术栈,包括很多个组件,这些

Volcano Scheduler组件
文章目录 简介工作流Actionsenqueueallocatepreemptreclaimbackfill PluginsgangconformanceDRFnodeorderpredicatespriority 配置如何查看Volcano scheduler的配置 简介 官网链接:https://volcano.sh/zh/docs/actions/ Volcano S
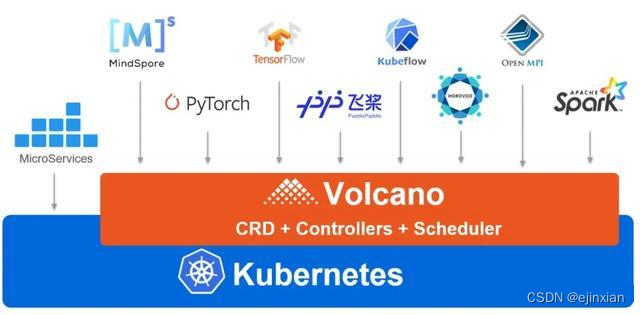
Kubernetes的容器批量调度引擎 Volcano
一个用于高性能工作负载场景下基于Kubernetes的容器批量调度引擎 Volcano是在Kubernetes上运行高性能工作负载的容器批量计算引擎。 它提供了Kubernetes目前缺少的一套机制,这些机制通常是许多高性能 工作负载所必需的,包括: - 机器学习/深度学习 - 生物学计算/基因计算 - 大数据应用。 Talks Intro: Kubernetes Batch Schedu

volcano学习之旅(1)--基础介绍
volcano学习之旅(1)–基础介绍 学习资源 官网: https://volcano.sh/zh/ git: https://github.com/volcano-sh/volcano/tree/v1.0.1 gitee码云: https://gitee.com/ascend/ascend-for-volcano 社区(Mind X DL): https://bbs.huaw
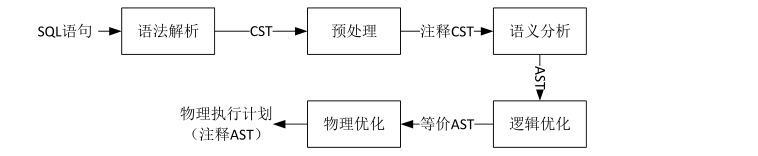
SQL 物理逻辑优化,Volcano Optimizer
SQL 查询优化的目的 优化器在整个数据库系统中占据着至高无上的地位,它是数据库性能的决定因素,是所有数据库引擎中最重要的组件。 ⑴使用的角度 因为SQL 是一种声明式(Declarative)的编程语言, 相比一般的编程语言描述的是程序执行的过程,这类编程语言则是描述问题或者需要的结果本身,具体的执行步骤则交由程序自己决定。SQL是一种可以被快速入手的编程语言, 主要优点就在于即使用户因并
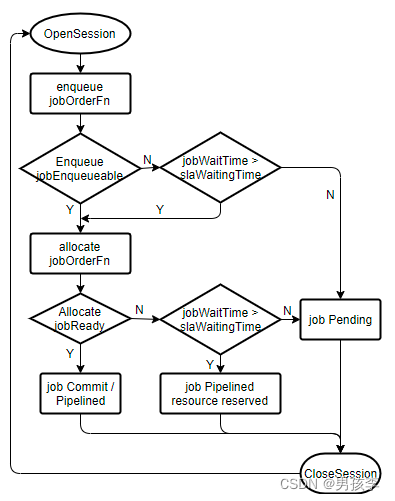
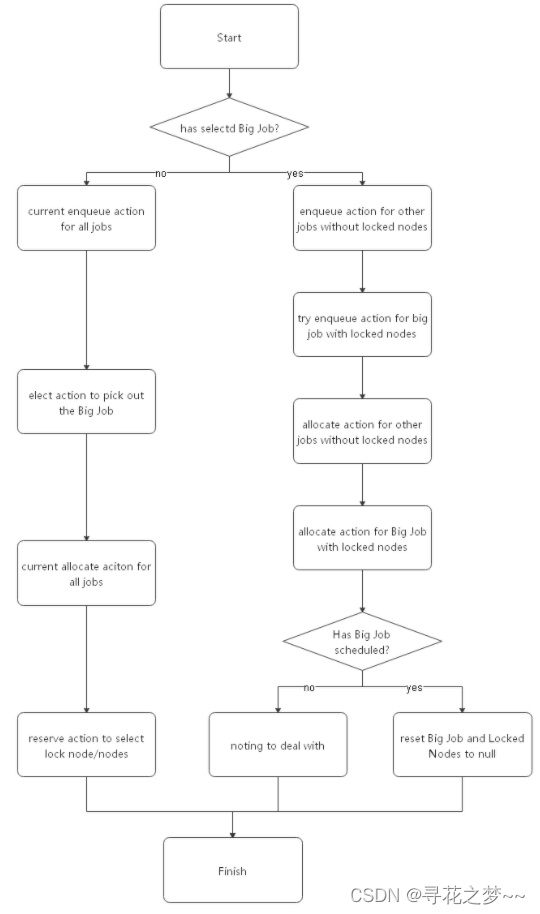
Volcano v1.2版本后的资源预留实现原理
1.背景介绍 在Volcano v1.2版本之前,资源预留是通过Reserve action实现的。具体实现可以参考: Volcano作业资源预留设计原理解读-云社区-华为云 Reserve action完成资源预留。将选中的目标作业与节点进行绑定。Reserve action、elect action 以及Reservation plugin组成了资源预留

cube开源一站式云原生机器学习平台--volcano 多机分布式计算
全栈工程师开发手册 (作者:栾鹏) 一站式云原生机器学习平台 volcano的基本原理和架构 Volcano是一个基于Kubernetes的云原生批量计算平台,也是CNCF的首个批量计算项目。 volcano是华为开源出的分布式训练架构,github官方网址:https://github.com/volcano-sh/volcano volcano 多机分布式 有时候单台

Volcano iterator model
Vectorized and Compiled Queries — Part 1 Imagine a volcano it is like a cone or at least it is drawn like that by most kids including me 😃. The below one is definitely not drawn by a kid. As the sha
ING国际银行基于Volcano的大数据分析平台应用实践
摘要:ING集团发表了《Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano - Krzysztof Adamski & Tinco Boekestijn, ING》主题演讲。 在KubeCon + CloudNativeCon North America,
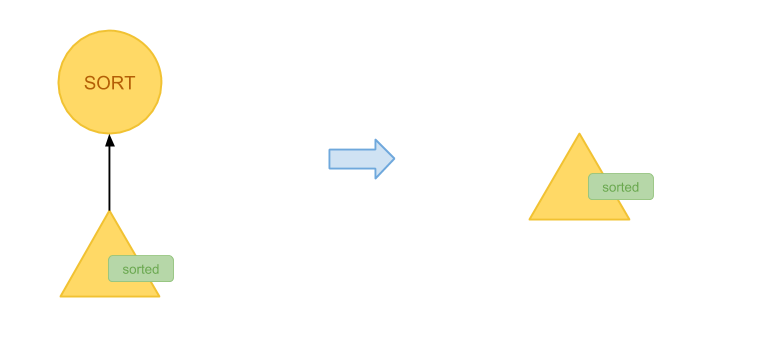
SQL 查询优化原理与 Volcano Optimizer 介绍
目录 SQL 查询优化的目的 SQL 查询优化的基本原理 SQL 查询优化的基础算法 基于规则的优化算法 基于成本的优化算法 Volcano Optimizer 成本最优假设 动态规划算法与等价集合 自底向上 vs. 自顶向下 广度优先搜索与启发式算法 Trait/Physical properties vector 其他 总结 随着大数据相关技术的发展,SQL 作