vits2专题
AIGC:语音克隆模型Bert-VITS2-2.3部署与实战
1 VITS2模型 1.1 摘要 单阶段文本到语音模型最近被积极研究,其结果优于两阶段管道系统。以往的单阶段模型虽然取得了较大的进展,但在间歇性非自然性、计算效率、对音素转换依赖性强等方面仍有改进的空间。本文提出VITS2,一种单阶段的文本到语音模型,通过改进之前工作的几个方面,有效地合成了更自然的语音。本文提出了改进的结构和训练机制,所提出的方法在提高多说话人模型中语音特征的自然度、相似性
bert-vits2本地部署报错疑难问题汇总
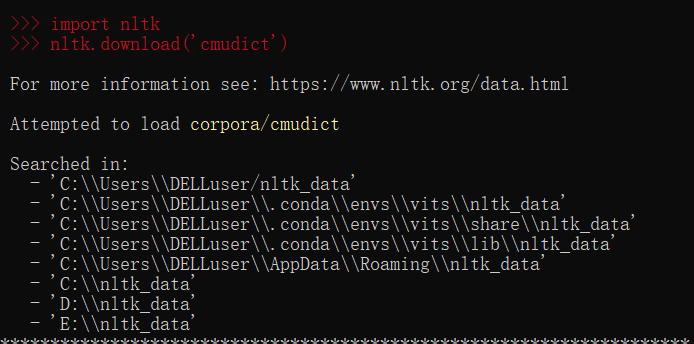
环境: bert-vits2.3 win 和wsl 问题描述: bert-vits2本地部署报错疑难问题汇总 解决方案: 问题1: Conda安装requirements里面依赖出现ERROR: No matching distribution found for opencc==1.1.6 解决方法 需要在 Python 3.11 上使用 OpenCC打开requirement
云端开炉,线上训练,Bert-vits2-v2.2云端线上训练和推理实践(基于GoogleColab)
假如我们一定要说深度学习入门会有一定的门槛,那么设备成本是一个无法避开的话题。深度学习模型通常需要大量的计算资源来进行训练和推理。较大规模的深度学习模型和复杂的数据集需要更高的计算能力才能进行有效的训练。因此,训练深度学习模型可能需要使用高性能的计算设备,如图形处理器(GPU)或专用的深度学习处理器(如TPU),这让很多本地没有N卡的同学望而却步。 GoogleColab是由Google提供
Bert-VITS2本地部署遇到的错误
关于Bert-VITS2本地部署遇到的错误 1、在下载python中相关依赖时报错 building ‘hdbscan._hdbscan_tree’ extension error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: https://visuals
AIGC:使用bert_vits2实现栩栩如生的个性化语音克隆
1 VITS2模型 1.1 摘要 单阶段文本到语音模型最近被积极研究,其结果优于两阶段管道系统。以往的单阶段模型虽然取得了较大的进展,但在间歇性非自然性、计算效率、对音素转换依赖性强等方面仍有改进的空间。本文提出VITS2,一种单阶段的文本到语音模型,通过改进之前工作的几个方面,有效地合成了更自然的语音。本文提出了改进的结构和训练机制,所提出的方法在提高多说话人模型中语音特征的自然度、相似性以

栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全可以接受。 BERT的核心思想是通过在大规模文本语料上进行无监督预训练,学习到通用的语言表示,然后将这些表示用于下游任务的微调。相比传统的基于词嵌入的模型,BERT引
栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全可以接受。 BERT的核心思想是通过在大规模文本语料上进行无监督预训练,学习到通用的语言表示,然后将这些表示用于下游任务的微调。相比传统的基于词嵌入的模型,BERT引