transnext专题

论文泛读: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
文章目录 TransNeXt: Robust Foveal Visual Perception for Vision Transformers论文中的知识补充非QKV注意力变体仿生视觉建模 动机现状问题 贡献方法 TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文链接: https://o

【ViT系列】TransNeXt: Robust Foveal Visual Perception for Vision Transformers
论文链接:https://arxiv.org/pdf/2311.17132.pdf 代码链接:https://github.com/DaiShiResearch/TransNeXt 一、摘要 1、引入了Pixel-focused Attention(PFA),它采用双路径设计。在一个路径中,每个查询对其最近邻特征具有细粒度的注意力,而在另一个路径中,每个查询对空间下采样特征具有粗粒度的注

TransNeXt实战:使用TransNeXt实现图像分类任务(一)
文章目录 摘要安装包安装timm 数据增强Cutout和MixupEMA项目结构计算mean和std生成数据集 摘要 https://arxiv.org/pdf/2311.17132.pdf TransNeXt是一种视觉骨干网络,它集成了聚合注意力作为令牌混合器和卷积GLU作为通道混合器。通过图像分类、目标检测和分割任务的综合评估,证明了这些混合组件的有效性。TransNeXt

TransNeXt:ViT的鲁棒Foveal视觉感知
文章目录 摘要1、引言2、相关工作3、方法3.1、聚合像素焦点注意力3.1.1、像素焦点注意力3.1.2、在单个混合器中聚合不同的注意力3.1.3、克服多尺度图像输入3.1.4、特征分析 3.2、卷积门控单元(Convolutional GLU)3.2.1、动机3.2.2、重新思考通道混合器设计 3.3、TransNeXt的架构设计 4、实验

【RT-DETR有效改进】2023.12月份最新成果TransNeXt像素聚焦注意力主干(全网首发)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PPHGNet版本,其中ResNet为RT-DETR官方版本1:1移植过来的,参数量基本保持一致(误差
YOLOv5改进 | 主干篇 | 12月份最新成果TransNeXt特征提取网络(全网首发)
一、本文介绍 本文给大家带来的改进机制是TransNeXt特征提取网络,其发表于2023年的12月份是一个最新最前沿的网络模型,将其应用在我们的特征提取网络来提取特征,同时本文给大家解决其自带的一个报错,通过结合聚合的像素聚焦注意力和卷积GLU,模拟生物视觉系统,特别是对于中心凹的视觉感知。这种方法使得每个像素都能实现全局感知,并强化了模型的信息混合和自然视觉感知能力。TransNeXt在各种
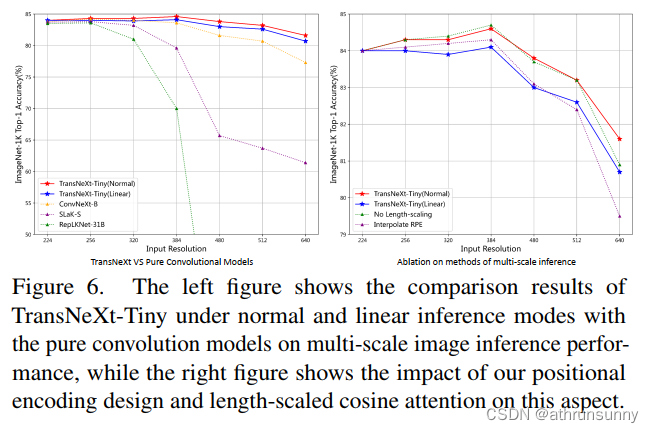
TransNeXt:稳健的注视感知ViT学习笔记
论文地址:https://arxiv.org/pdf/2311.17132.pdf 代码地址: GitHub - DaiShiResearch/TransNeXt: Code release for TransNeXt model 可以直接在ImageNet上训练的分类代码:GitHub - athrunsunny/TransNext-classify 代码中读取数据的部分修改一下就