tough专题

CodeForces 914D :Bash and a Tough Math Puzzle 线段树
传送门 题目描述 分析 我们去维护每个区间内不能整除 x x x的个数 c n t cnt cnt x = = 0 x == 0 x==0 把这个区间内任意一个数修改为 x x x即可 x = = 1 x == 1 x==1 将不能整除 x x x的数修改为 x x x x > 1 x > 1 x>1 无法达到要求 代码 #pragma GCC optimize(3)#incl

读论文有感:A Sample But Tough-To-Beat Baseline For Sentence Embedding
该算法有着一定的意义,即通过分析,对Word Embeddings进行加权平均,得到比单纯平均或以TF-IDF为权值的平均向量更好的结果,因计算简单,如作者所述,作为一个更好的Baseline是很好的选择 不过该论文的一些说法有点言过其实,甚至进行了一点小tricks,比如说比supervised 的LSTM有着更好的效果这一说法,有着一定的争议,因为Sentence Embedding实则也是
TOUGH系列软件应用丨TOUGH2、TOUGHIO、水合物开采及Hydrate模块、流固耦合模型及TOUGH-CSM、EGS模块、EOS1模块、EOS3模块、EOS9模块、TMVOC模块等
目录 一、入门篇 多相流流体基本特征及TOUGH系列软件讲解 二、基础篇 TOUGH系列软件建模步骤、文本输入输出与可视化练习 三、进阶篇 TOUGH2第三方软件讲解与练习、功能拓展与高阶应用 四、专题篇 TOUGH2常用模块讲解与实例应用练习与分析 五、建模经验分享与学习交流 更多应用 TOUGH系列软件是由美国劳伦斯伯克利实验室开发的,旨在解决非饱和带中地下水、热运移的通用模
Love 6的Tough Experience(准备面试、找实习、以及面试经历、经验分享)
文章目录 前引1、实习offer状态2、目前写这篇博客的状态3、对于后续的博客更新说明 Tough Experience(2022/5 - 2022/12)1、准备面试1、基础背景2、项目背景3、刷题背景 2、准备面试的过程1、初期准备状态(2022/5/12 - 2022/7/1)2、暑假准备状态(2022/7/2 - 2022/8/27)3、回校准备状态(2022/8/28 - 2022

论文A simple but tough-to-beat baseline for sentence embedding
转载自https://blog.csdn.net/sinat_31188625/article/details/72677088 论文原文:A simple but tough-to-beat baseline for sentence embedding 引言 在神经网络泛滥的时候,这篇文章像一股清流,提出了一个无监督的句子建模方法,并且给出了该方法的一些理论解释。通过该方法得到的句子向量

Codecraft-18 and Codeforces Round #458 D. Bash and a Tough Math Puzzle(线段树)
Bash likes playing with arrays. He has an array a1, a2, ... an of n integers. He likes to guess the greatest common divisor (gcd) of different segments of the array. Of course, sometimes the guess
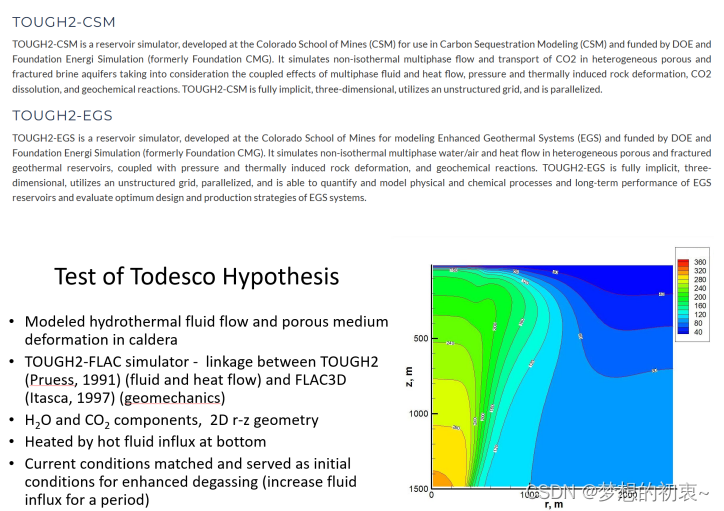
TOUGH系列软件实践技术应用
TOUGH系列软件是由美国劳伦斯伯克利实验室开发的,旨在解决非饱和带中地下水、热运移的通用模拟软件。和传统地下水模拟软件Feflow和Modflow不同,TOUGH系列软件采用模块化设计和有限积分差网格剖分方法,通过配合不同状态方程(EOS模块),软件可以处理各种复杂地质条件下,诸如地热能开发,非饱和带水气运移、油气运移,深部碳存储,天然气水合物开发以及多种环境修复等问题。 例如:TOUGHRE

全流程TOUGH系列软件实践技术应用
TOUGH系列软件是由美国劳伦斯伯克利实验室开发的,旨在解决非饱和带中地下水、热运移的通用模拟软件。和传统地下水模拟软件Feflow和Modflow不同,TOUGH系列软件采用模块化设计和有限积分差网格剖分方法,通过配合不同状态方程(EOS模块),软件可以处理各种复杂地质条件下,诸如地热能开发,非饱和带水气运移、油气运移,深部碳存储,天然气水合物开发以及多种环境修复等问题。 点击查看原文http

论文解读-SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS
1.论文摘要 该论文是在 ICLR 2017提出的一个无监督的句子嵌入的方法:使用维基百科等无标签的语料训练得到词向量,然后通过词向量加权平均获得句子表征向量。然后使用PCA/SVD再对句向量进行一次修正得到最终得句向量。 2. 计算句子表征的算法 先来看下论文中提出的句子表征的算法: 上面的算法过程中有两个重点: • 为什么可以通过句子中的单词向量加权平均来获得句子初始的向量的表征?(公