tidyverse专题

tidyverse提取MergedGenes列包含“sss“字符的行
要使用tidyverse包在R中提取包含特定字符串“sss”字符的MergedGenes列的行,可以使用dplyr包中的filter()函数和str_detect()函数来实现。这里的str_detect()函数来自stringr包,它是tidyverse的一部分,用于检测字符串是否符合给定的模式。以下是一个示例代码: # 加载tidyverse包library(tidyverse)# 假设你

tidyverse去除表格中含有NA的行
在tidyverse中,特别是使用dplyr包,去除含有NA的行可以通过filter()函数结合is.na()和any()或all()函数来实现。dplyr是tidyverse的一部分,提供了一系列用于数据操作的函数,使数据处理变得更加简单和直观。 以下是一个简单的例子,展示了如何使用这些函数从数据框中移除任何包含NA的行: library(dplyr)# 假设df是你的数据框df <- d
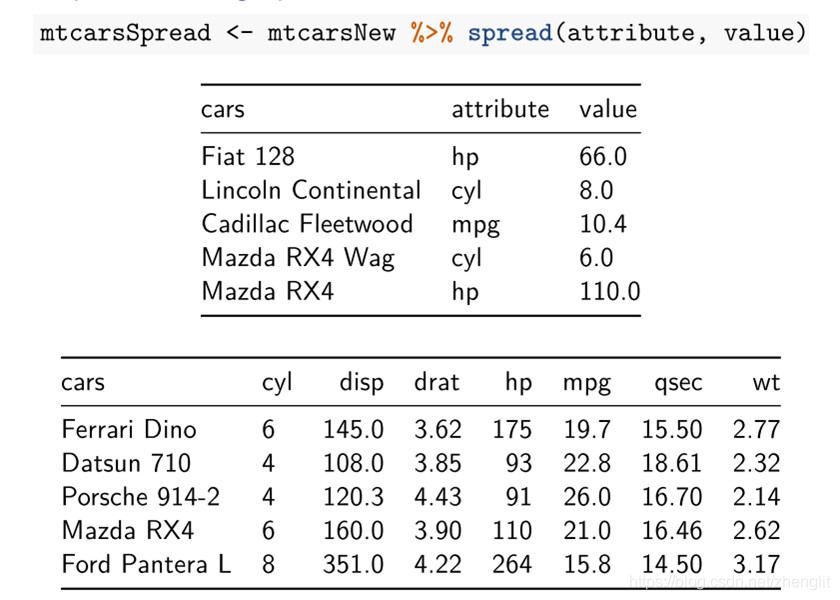
tidyverse数据处理
tidyverse出自于R大神Hadley Wickham之手,他是Rstudio首席科学家,也是ggplot2的作者。tidyverse就是他将自己所写的包整理成了一整套数据处理的方法,包括ggplot2,dplyr,tidyr,readr,purrr,tibble,stringr, forcats。tidyverse主要的经常用的函数工具: 1.管道符%>% > iris %>% head
R语言生物群落(生态)数据统计分析与绘图丨R语言基础、tidyverse数据清洗、多元统计分析、随机森林模型、回归及混合效应模型、结构方程模型、统计结果作图
R 语言的开源、自由、免费等特点使其广泛应用于生物群落数据统计分析。生物群落数据多样而复杂,涉及众多统计分析方法。本教程以生物群落数据分析中的最常用的统计方法回归和混合效应模型、多元统计分析技术及结构方程等数量分析方法为主线,通过多个来自经典研究中的实例,详细讲述各方法的R语言实现途径(详见教学内容)。主要特点为聚焦生态学研究领域,从R语言基础操作和作图、数据准备整理,到各种数量分析方法的应用情景

透视、逆透视:R语言(reshape2、tidyverse),Excel,Python
总结(Python的pandas,R语言的reshape2、tidyr) R语言(reshape2、tidyverse) 数据来源:R语言实战第二版P106 library(tidyverse)library(reshape2)# 透视、逆透视# R语言实战第二版P106# https://r4ds.had.co.nz/# https://bookdown.org/Ma