tez专题

Apache Tez基本知识
官方blog: http://hortonworks.com/blog/author/arun_murthy/ svn源码: http://hortonworks.com/blog/introducing-tez-faster-hadoop-processing/ 看到一篇很不错的文章: http://dongxicheng.org/mapreduce-nextgen/apache-te

Apache Tez最新进展
为了更高效地运行存在依赖关系的作业(比如Pig和Hive产生的MapReduce作业),减少磁盘和网络IO,Hortonworks开发了DAG计算框架Tez。Tez是从MapReduce计算框架演化而来的通用DAG计算框架,可作为MapReduceR/Pig/Hive等系统的底层数据处理引擎,它天生融入Hadoop 2.0中的资源管理平台YARN,且由Hadoop 2.0核心人员精心打造,势必将会

Hive On Tez小文件合并的技术调研
Hive On Tez小文件合并的技术调研 背景 在升级到CDP7.1.5之后,默认的运算引擎变成了Tez,之前这篇有讲过: https://lizhiyong.blog.csdn.net/article/details/126688391 具体参考Cloudera的官方文档:https://docs.cloudera.com/cdp-private-cloud-base/7.1.3/hi
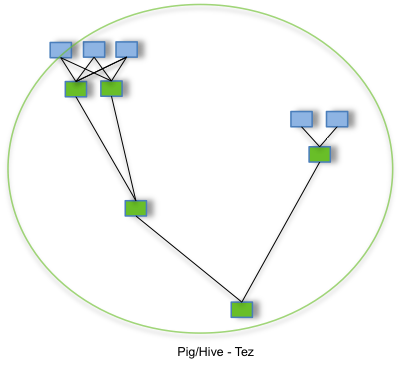
Hive 运行在 Tez 上
Tez 介绍 Tez 是一种基于内存的计算框架,速度比 MapReduce 要快 解释: 浅蓝色方块表示 Map 任务,绿色方块表示 Reduce 任务,蓝色边框的云朵表示中间结果落地磁盘。 Tez 下载 Tez 官网 Tez 在 Hive 上的运用 前提要有 Hadoop 集群 上传 Tez 压缩包到 Hive 节点上 tar -zxvf apache-t

Hive切换引擎(MR、Tez、Spark)
Hive切换引擎(MR、Tez、Spark) 1. MapReduce计算引擎(默认) set hive.execution.engine=mr; 2. Tez引擎 set hive.execution.engine=tez; 1. Spark计算引擎 set hive.execution.engine=spark;
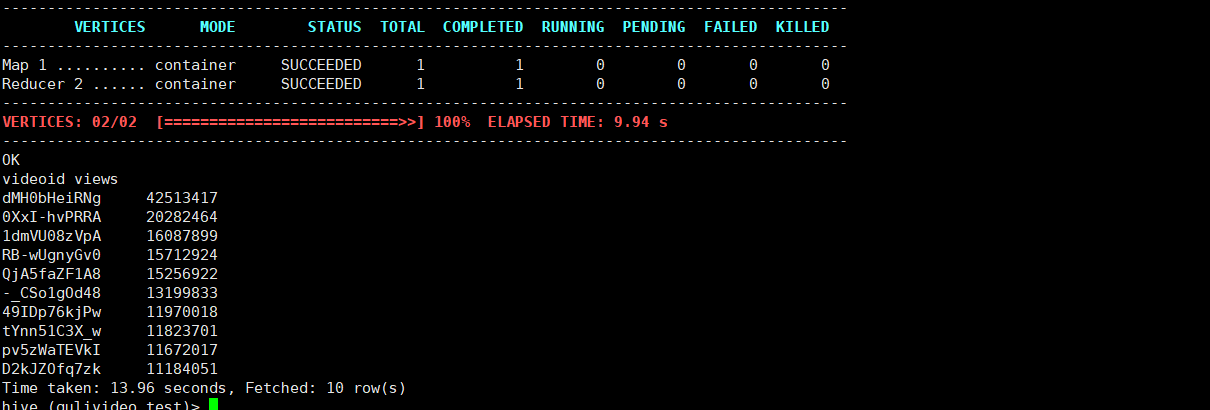
在添加tez引擎之后,2.6 GB of 2.1 GB virtual memory used. Killing container
在添加tez引擎之后,2.6 GB of 2.1 GB virtual memory used. Killing containe Application application_1642949186322_0005 failed 2 times due to AM Container for appattempt_1642949186322_0005_000002 exited with
Hive on Tez map阶段task划分源码分析(map task个数)
Hive on Tez中map和reduce阶段task的划分在SQL调优和跑批中比较重要,在调优时我们会遇到maptask分配个数不合理(太少或太多),map 各task运行时间存在倾斜等相关问题。 难点在于说Tez引擎有自己的map Task划分逻辑,这一点与MR引擎或者spark引擎等直接按照文件split划分策略存在不同,所以在实际生产环境中有时候map

hive tez调优(3)
根据。方案最右侧一栏是一个8G VM的分配方案,方案预留1-2G的内存给操作系统,分配4G给Yarn/MapReduce,当然也包括了HIVE,剩余的2-3G是在需要使用HBase时预留给HBase的。 内存调优 一、AM、Container大小设置1、tez.am.resource.memory.mb #设置 tez AM容器内存 默认值:1024 配置文件:tez-site.xm

Hive2安装Tez计算引擎
一、Tez介绍 ApacheTEZ®项目旨在构建一个应用程序框架,该框架允许使用复杂的有向无环图来处理数据。 它当前构建在Apache Hadoop YARN之上。 Tez的2个主要设计主题是: 通过以下方式增强最终用户的能力: 富有表现力的数据流定义API 灵活的输入-处理器-输出运行时模型 不可知数据类型 简化部署 执行性能 与Map Reduce相比性能提升 最佳资源管理 在运行时计划重新
Hive引擎MR、Tez、Spark
Hive引擎包括:默认MR、Tez、Spark 不更换引擎hive默认的就是MR。 MapReduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算。 Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。 Spark on Hive 就是通过sparksql,加载hive的配置文