standardization专题

归一化(Normalization)与标准化(Standardization)
在机器学习和数据挖掘中,经常会听到两个名词:归一化(Normalization)与标准化(Standardization)。它们具体是什么?带来什么益处?具体怎么用?本文来具体讨论这些问题。 一、是什么 1. 归一化 常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换函数为: x′=x−minmax−min x′=x−minmax−min 其中 min
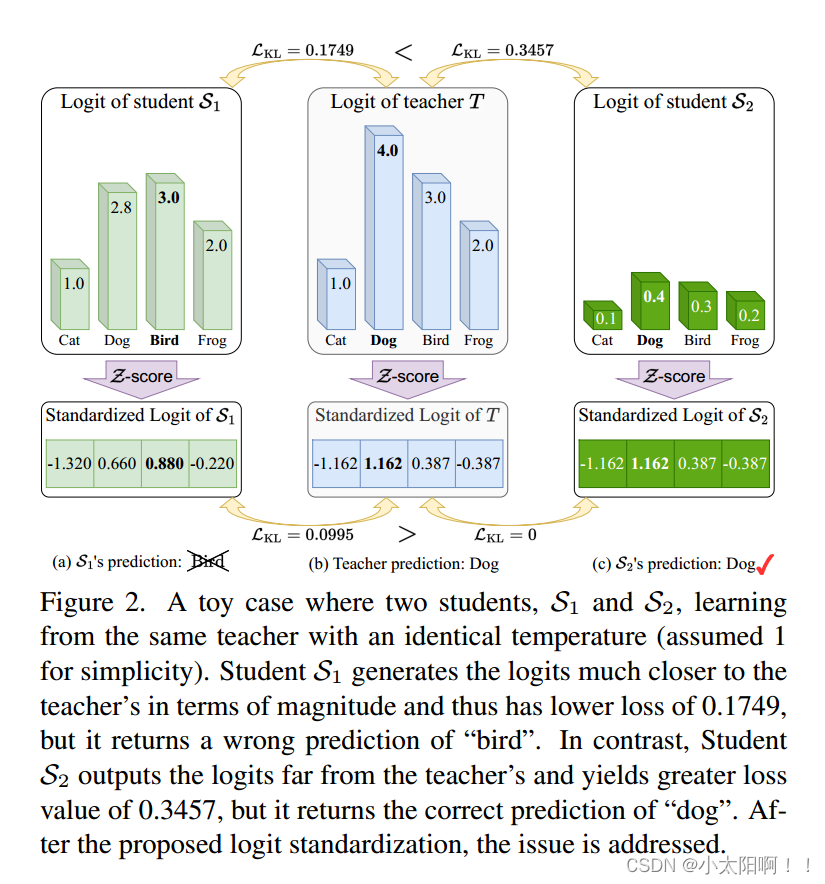
Logit Standardization in Knowledge Distillation 知识蒸馏中的logit标准化
摘要 知识蒸馏涉及使用基于共享温度的softmax函数将软标签从教师转移到学生。然而,教师和学生之间共享温度的假设意味着他们的logits在logit范围和方差方面必须精确匹配。这种副作用限制了学生的表现,考虑到他们之间的能力差异,以及教师天生的logit关系足以让学生学习。为了解决这个问题,我们建议将温度设置为logit的加权标准差,并在应用softmax和KL散度之前进行logit标准化的即

sklearn实现数据标准化(Standardization)和归一化(Normalization)
标准化(Standardization) sklearn的标准化过程,即包括Z-Score标准化,也包括0-1标准化,并且即可以通过实用函数来进行标准化处理,同时也可以利用评估器来执行标准化过程。接下来我们分不同功能以的不同实现形式来进行讨论: Z-Score标准化的评估器实现方法 #首先是评估器导入from sklearn.preprocessing import StandardS
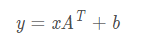
model.train()与model.eval(),标准化(Standardization)、归一化(Normalization),Dropout,Batch Normalization通俗理解
目录 model.train()与model.eval() 归一化(Normalization) 标准化(Standardization) Batch Normalization Dropout TensorFlow和pytorch中dropout参数p relu,sigmiod,tanh激活函数 nn.Linear model.train()与model.eval() 当