soup专题

3.2 Beautiful Soup使用
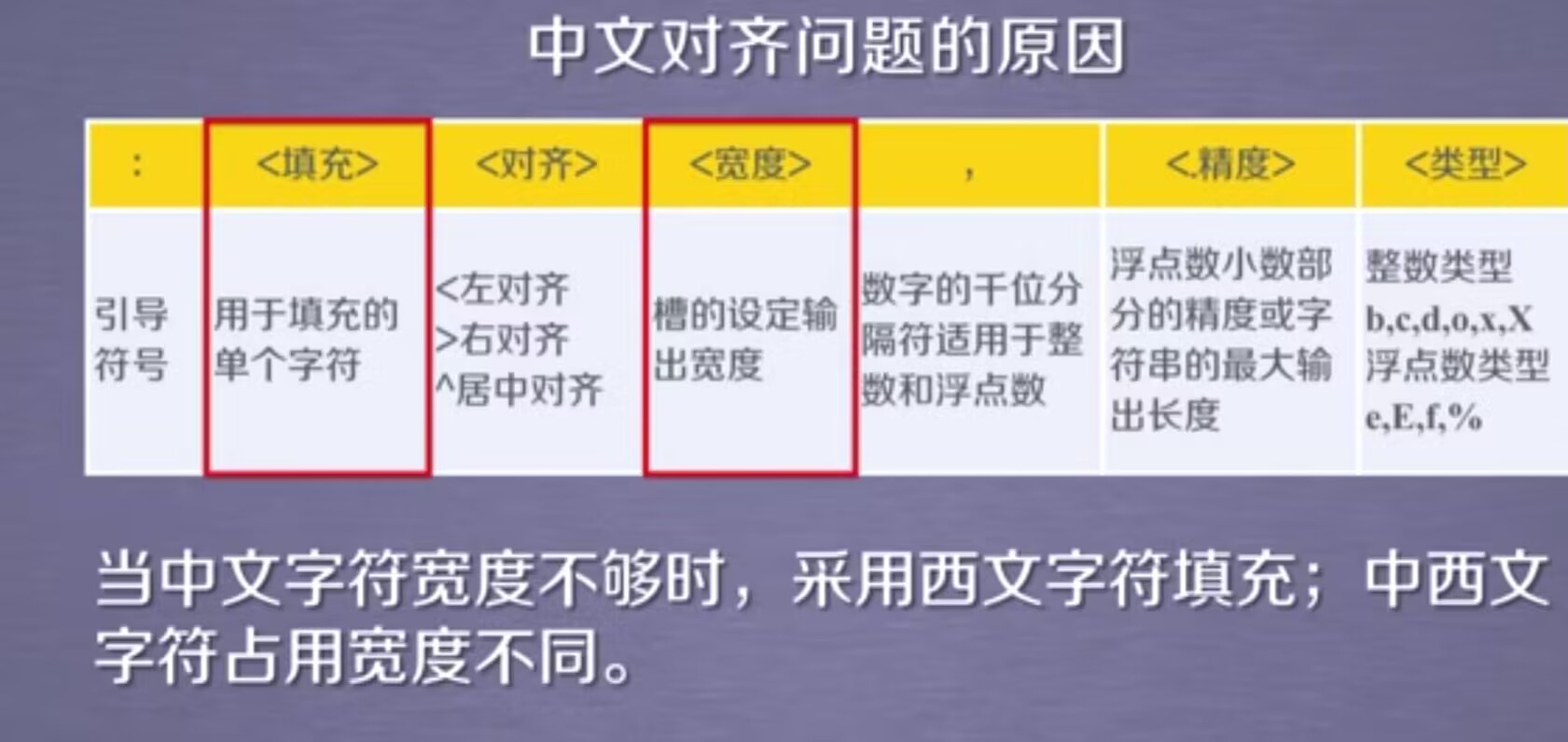
课程目标 理解HTML文档结构和解析方法学习使用Beautiful Soup库解析HTML和XML文档 课程内容 Beautiful Soup 1. HTML文档结构 HTML(超文本标记语言)是构建网页的标准标记语言。了解HTML的基本结构对于使用Beautiful Soup解析网页至关重要。 标签:HTML由一系列的标签组成,例如<p>表示段落。属性:标签可以包含属性,例如<img

HTML解析之Beautiful Soup
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501 Beautiful Soup是一个用于从HTML和XML文件中提取数据的Python库。Beautiful Soup 提供一些简单的、函数用来处理导航、搜索、修改分析树等功能。Beau

如何使用 Selenium 和 Beautiful Soup 抓取动态内容
网页抓取有时需要从动态内容中提取数据。对于大多数人来说,这可能是一项艰巨的任务,尤其是非技术专业人士。此外,抓取动态内容需要比传统的网页抓取更高的精度。这是因为大多数动态内容都是通过 JavaScript 加载的,这使得提取信息变得具有挑战性。 Selenium 和 BeautifulSoup 等著名库可以有效地抓取动态内容。Crawlbase 创建了无缝处理动态内容的抓取解决方案。本文将教您如

Miyeok Guk (Korean Seaweed Soup) - Миён Гук (Корейский суп из морепродуктов)
Для всех у кого скоро день рождение и не только!! [РЕЦЕПТЫ] Miyeok Guk (Korean Seaweed Soup) - Миён Гук (Корейский суп из морепродуктов) Суп Миёк Гук делается с миёком (так же знают как вакаме),

Python Beautiful Soup 使用详解
大家好,在网络爬虫和数据抓取的领域中,Beautiful Soup 是一个备受推崇的 Python 库,它提供了强大而灵活的工具,帮助开发者轻松地解析 HTML 和 XML 文档,并从中提取所需的数据。本文将深入探讨 Beautiful Soup 的使用方法和各种功能,希望能给大家带来一些帮助。 一、Beautiful Soup介绍 Beautiful
You are trying to run the Python 2 version of Beautiful Soup under Python 3. This will not work
但是在IDLE中import bs4时,会出现:Traceback (most recent call last): File "<pyshell#3>", line 1, in <module> import bs4 File "C:\Users\Administrator\AppData\Local\Programs\Python\Python35-32\lib\bs4\__in

Python3网络爬虫(二):使用Beautiful Soup爬取小说
转载请注明作者和出处:http://blog.csdn.net/c406495762 运行平台: Windows Python版本: Python3.x IDE: Sublime text3 一、Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下: Beautiful Soup提供

Python网络数据抓取(3):Beautiful Soup
Beautiful Soup 这个库通常被称为Beautiful Soup 4(BS4)。它主要用来从HTML或XML文件中抓取数据。此外,它也用于查询和修改HTML或XML文档中的数据。 现在,让我们来了解如何使用Beautiful Soup 4。我们将采用上一节中使用的HTML数据作为示例。不过在此之前,我们需要先将这些数据导入到我们的文件中。 from bs4 import Beautif

Beautiful Soup库入门并用其构建简单的网页爬虫
简介: Beautiful Soup是一个HTML和XML文档的Python解析器。我们可以用它从不提供API调用的web站点获取网页并构造数据集,还可以利用它在网页中查找索引所需要的文本。利用urllib2和Beautiful Soup, 我们可以建立一个爬虫程序。 urllib2是一个与Python绑定的库,其作用是方便网页的下载。urllib和urllib2两个模块功能都差不多,但url

利用Python进行网络爬虫:Beautiful Soup和Requests的应用【第131篇—Beautiful Soup】
利用Python进行网络爬虫:Beautiful Soup和Requests的应用 在网络数据变得日益丰富和重要的今天,网络爬虫成为了获取和分析数据的重要工具之一。Python作为一种强大而灵活的编程语言,在网络爬虫领域也拥有广泛的应用。本文将介绍如何使用Python中的两个流行库Beautiful Soup和Requests来创建简单而有效的网络爬虫,以便从网页中提取信息。 什么是Beau
Beautiful Soup 4.2.0 官方中文文档
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间. 这篇文档介绍了BeautifulSoup4中所有主要特性,并切有小例子.向我们展示了它适合做什么,如何工作,怎样使用,如何达到你想要的效果,和处理异常情况等. Beautif

布朗温莎汤(Brown Windsor Soup)布朗温莎汤的特点起源与争议现代的布朗温莎汤白兰地加苏打水这个搭配如何,并讲述这样搭配的由来白兰地的特点苏打水的特点白兰地加
目录 布朗温莎汤(Brown Windsor Soup) 布朗温莎汤的特点 起源与争议 现代的布朗温莎汤 白兰地加苏打水这个搭配如何,并讲述这样搭配的由来 白兰地的特点 苏打水的特点 白兰地加苏打水的搭配 由来 迎春花和紫罗兰 迎春花(Jasminum nudiflorum) 紫罗兰(Viola) 生态和用途 文化象征 伦敦河岸街(London's South Ban
Python使用Beautiful Soup及解析html获取元素并提取内容值
Python使用Beautiful Soup及解析html获取元素并提取内容值 1. 包括解析获取标题2. 根据标签及id获取所有元素3. 根据标签及class获取所有元素4. 获取元素下的标签的值5. 获取元素下的parent及child的元素的值参考 1. 包括解析获取标题 2. 根据标签及id获取所有元素 3. 根据标签及class获取所有元素 4. 获取元素下的标签

Python爬虫第二章(HTMl文件,CSS语言与第三方库Beautiful Soup)
文章目录 一、前置知识二、HTMl文件结构三、HTML常用标签四、CSS五、CSS基础语法六、一个简单网页模板七、BeautifulSoup库八、查找标签九、获取标签的属性和文本 欢迎大家阅读这篇关于BeautifulSoup的博客。在互联网信息爆炸的时代,获取和处理网络数据显得尤为重要。BeautifulSoup是一个强大的Python库,它能够帮助我们轻松地从网页获取所需信息。无
网页数据的解析提取(Beautiful Soup库详解)
前面介绍了lxml库和re库,(网页数据的解析提取(XPath的使用----lxml库详解)-CSDN博客 网页数据的解析提取(正则表达式----re库详解)-CSDN博客)。现在来介绍一个更为简便和强大的解析工具--Beautiful Soup,其借助网页的结构和属性等特性来解析网页。 目录 Beautiful Soup 1、 Beautiful Soup 的简介 2、解
[Python]HTML/XML解析器Beautiful Soup
【简介】 Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库。即HTML/XMLX的解析器。 它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。 【安装】 下载地址:点击打开链接 Linux平台安装: 如果你用的是新版的Deba
【python】网络爬虫与信息提取--Beautiful Soup库
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/ 作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。 使用原理:它能够把任何我们给它的文档当作一锅汤,任何给我们煲制这锅汤。 一、安装

python 爬虫篇(3)---->Beautiful Soup 网页解析库的使用(包含实例代码)
Beautiful Soup 网页解析库的使用 文章目录 Beautiful Soup 网页解析库的使用前言一、安装Beautiful Soup 和 lxml二、Beautiful Soup基本使用方法标签选择器1 .string --获取文本内容2 .name --获取标签本身名称3 .attrs[] --通过属性拿属性的值 标准选择器find_all( name , attrs , r
Python爬虫 Beautiful Soup库详解#4
爬虫专栏:http://t.csdnimg.cn/WfCSx 使用 Beautiful Soup 前面介绍了正则表达式的相关用法,但是一旦正则表达式写的有问题,得到的可能就不是我们想要的结果了。而且对于一个网页来说,都有一定的特殊结构和层级关系,而且很多节点都有 id 或 class 来作区分,所以借助它们的结构和属性来提取不也可以吗? 这一节中,我们就来介绍一个强大的解析工具 Beaut
如何使用 Python 3 中的 Requests 和 Beautiful Soup 处理 Web 数据
简介 网络为我们提供了比我们能阅读和理解的更多数据,因此我们经常希望以编程方式处理这些信息,以便理解它。有时,网站创建者通过 .csv 或逗号分隔值文件或通过 API(应用程序编程接口)向我们提供这些数据。其他时候,我们需要自己从网络上收集文本。 本教程将介绍如何使用 Requests 和 Beautiful Soup Python 包来利用网页数据。Requests 模块允许您将 Pytho

Beautiful Soup 4知识点思维导图
Introduction 1 Introduction 2 Introduction 3 Tag NavigableString BeautifulSoup
Beautiful Soup学习笔记(对我自己比较常用)
本文仅为学习笔记,作用仅为方便自己查阅复习使用,具体学习路线参考 Beautiful Souo 4.2.0文档 文章目录 TagnameAttributestag属性的删除tag属性的修改多值属性tag中的字符串注释及特殊字符串 Tag tag中两个最重要的属性: name和attributes soup = BeautifulSoup('<b class="121"

python中的beautiful_Python中Beautiful Soup的用法
原标题:Python中Beautiful Soup的用法 1、Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。 官方解释如下: Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可
使用Beautiful Soup解析网页
3 使用Beautiful Soup解析网页 Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库。目前Beautiful Soup 3已经停止开发,大部分的爬虫选择使用Beautiful Soup 4开发。Beautiful Soup不仅支持Python标准库中的HTML解析器,还支持一些第三方的解析器,具体语法如下。 lxml解析器比较常用。

Python 网络爬虫从0到1 (4):Beautiful Soup 4库入门详解
从先前的几篇文章中,我们已经能够使用Requests库构造请求并获得正确的响应,但是在样例中我们也发现了仅使用Requests库的缺陷。在网络爬虫的设计中,仅能构造请求并收到响应是远远不够的。想要获取响应中有意义的信息并能够由此采取下一步行动,是整个流程中的重要一段。所以本篇文章,我们就来一起学习较为流行的HTML/XML数据分析提取库:Beautiful Soup 4 Beaut