slurm专题

并行 云架构 深度框架 sbatch slurm 深度学习 tensorflow环境从搭建到使用 conda
有一定的GPU云时常可用,一个节点4个GPU,我本人决定使用anaconda搭建tensorflow1.13并且使用。 anaconda是乙方提供的,使用bash命令可以加载 module load anaconda/3.7 加载后正常使用create命令建立环境 详情见我所有conda标志的博客,其实就是下面一句代码,看明白就不用翻了。 下面这句代码就从零开始建立了一个tensorf
将MAE方法用于reflacx数据集--MMpretrain/slurm
MAE—reflacx 问题问题一 === 对数据集reflacx的了解问题二 === MAE实现的是有监督,还是无监督任务问题三 === 实验流程问题四 === 实验目的 一、从github上fork我师兄的项目30min(github账号的注册什么的,可以去参考b站)1.1 点开下面这个链接1.2 看到页面的上方,跟随我们的小兔子fork一下1.3 根据这个指引,填好之后,点击绿色的Cr

slurm是什么,怎么用? For slurm和For Pytorch有什么区别和联系?
1.slurm是什么? Slurm(Simple Linux Utility for Resource Management)是一种开源的、用于集群和超级计算机的作业调度系统。它主要用于管理和调度大规模计算任务,使得用户可以有效地利用集群中的计算资源。Slurm提供了一套功能强大的工具,用于提交、调度和管理作业。它可以根据用户的需求,动态地分配计算资源,并监控作业的执行状态。同时,Slurm还支

在 Slurm 上运行 Jupyter
1. 背景介绍 现在的大模型训练越来越深入每个组了,大规模集群系统也应用的愈发广泛。一般的slurm系统提交作业分为2种,一种是srun,这种所见即所得的申请方式一般适用于短期的调试使用,大概一般允许的时间从几个小时到1天左右,很多集群分组都会限制运行时长。而另一种sbatch,则是批量提交作业,当srun调试程序能够成功运行的时候,就可以使用sbatch提交。如何使用slurm可以参考之前写的
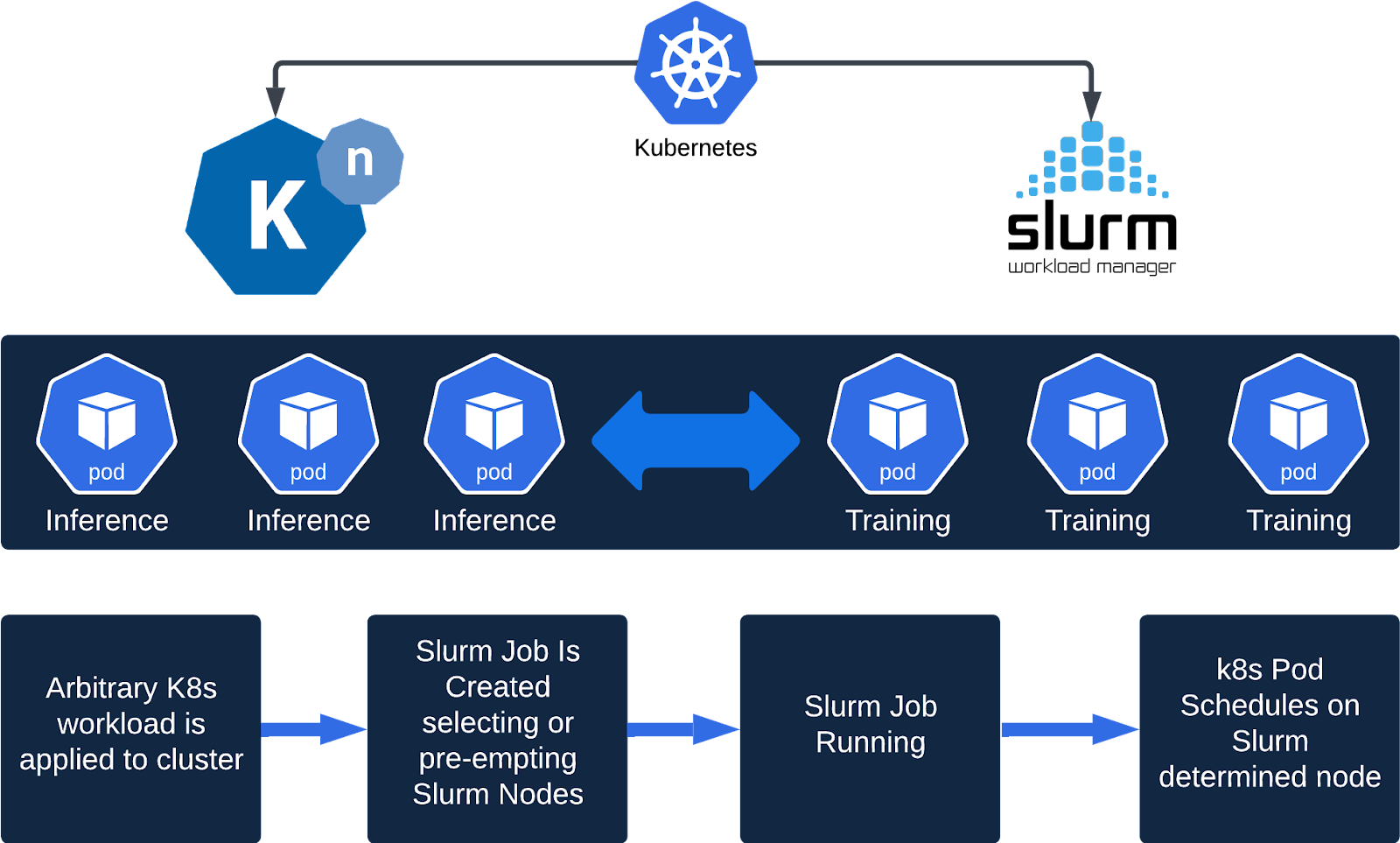
拥抱高性能计算:将Slurm集成为K8s调度程序
Kubernetes 运行 HPC 工作负载的挑战 任何使用过 Docker 的人都会体会到容器所带来的巨大效率提升。虽然 Kubernetes 擅长编排容器,但在 Kubernetes 上部署高性能计算 (HPC) 应用程序可能很棘手。 在 Kubernetes 中,调度的基本单位是 Pod:调度到集群主机的是一个或多个容器。虽然 Kubernetes 具有Cron 作业和一次性作业的概念,
slurm作业管理系统怎么用?
对于大型集群环境,通常需要有作业管理系统来调度分配系统资源,本文介绍一款开源免费的容错和高度可扩展的集群管理和作业调度系统:SLURM。在我国首次获得世界TOP500计算机排名第一的天河一号计算机上使用的集群管理和作业调度系统,就是基于SLURM二次开发的,可见其强大。 它的官网是:传送门。 准备可执行程序和输入文件 我们想提交一个计算任务,首先要准备好可执行程序和输入文件。 可执行程序需
slurm作业管理:一次提交运行多个任务
针对抢占式的作业调度系统,如果分配节点时候是独占节点,那么每次申请的资源最少就是1个节点。如何实现一次提交作业,计算多个任务呢?(包括串行、openmp或mpi的任务)。最简单的方式就是按照自己的需求写一个运行脚本,然后通过作业管理系统提交即可。下面给出一个具体的例子加以说明,先给出实例,然后给出详细解释: #!/bin/bashcd ~/helloworldyhrun -N1 -n1 .
SLURM资源调度管理系统REST API服务配置,基于slurm22.05.9,centos9stream默认版本
前面给大家将了一下slurm集群的简单配置,这里给大家再提升一下,配置slurm服务的restful的api,这样大家可以将slurm服务通过api整合到桌面或者网页端,通过桌面或者网页界面进行管理。 1、SLURM集群配置 这里请大家参考:SLURM超算集群资源管理服务的安装和配置-基于slurm22.05.9和centos9stream,配置slurmdbd作为账户信息存储服务-CSDN博