sentencepiece专题

SentencePiece的中文测试实践
许多自然语言处理程序中都用到了谷歌开源的SentencePiece作为词切分的基础工作之一,于是跟踪学习了下。 1、基本介绍 What is SentencePiece? SentencePiece is a re-implementation of sub-word units, an effective way to alleviate the open vocabulary probl

随机分词与tokenizer(BPE->BBPE->Wordpiece->Unigram->sentencepiece->bytepiece)
0 tokenizer综述 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后

【深度学习】sentencepiece工具之BPE训练使用
为什么要使用BPE,BPE是什么 BPE:迭代的将字符串里出现频率最高的子串进行合并 训练过程 使用教程 代码使用的语料在这里 # -*- coding: utf-8 -*-#/usr/bin/python3import osimport errnoimport sentencepiece as spmimport reimport logginglogging.basicC
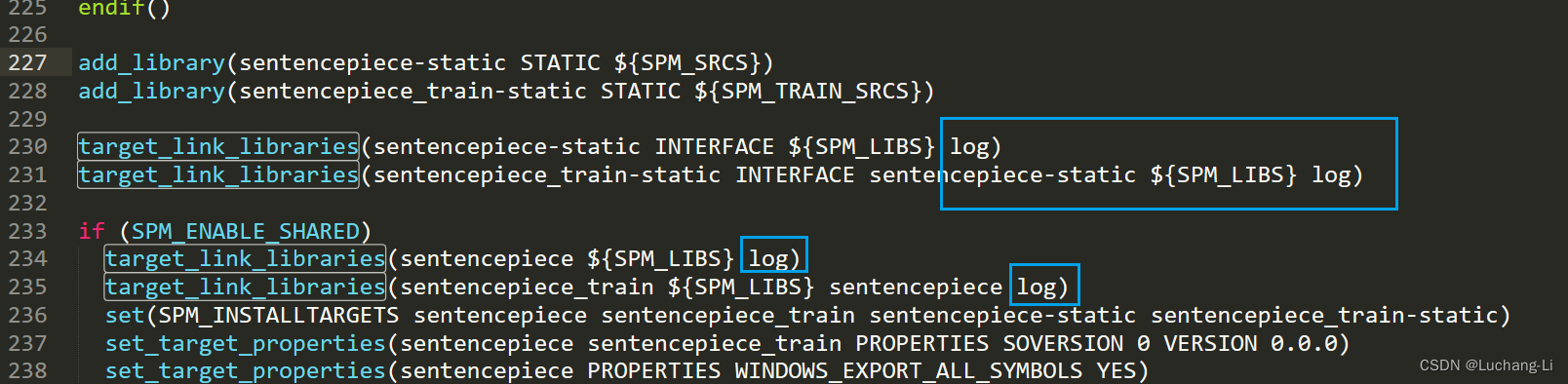
SentencePiece android ndk编译
LLaMa等LLM语言模型一般使用SentencePiece tokenizer,在端侧部署需要编译和使用其c++版本。 在安卓平台使用NDK编译 CMakeLists.txt需要进行一些修改: src/CMakeLists.txt如下位置加上log依赖,否则提示android log相关符号不存在。 此外,入口处的CMakeLists.txt加上 set(CMAKE_CXX_F