secondary专题

【MongoDB】配置Secondary(从节点) 的 Sync Target(复制源)
一 概述 从节点 从 主节点捕获数据以保持副本集数据的最新副本。然而,默认情况下,从节点可能会根据成员之间的ping时间变化和其他成员的复制状态自动更改其同步目标。请参阅“副本集数据同步”和“管理链式复制”以获取更多信息。 对于某些部署,实施自定义复制同步拓扑可能比默认的同步目标选择逻辑更有效。MongoDB提供了指定主节点的能力。 要临时覆盖默认的同步目标选择逻辑,可以手动配置从节点的同步

mysql like %string% 索引失效问题,cluster index, secondary index,covering index意思
只有在like 子句是'string%'时,建在该字段的单列索引才会被使用。但实际中LIKE '%string%'的查询需求又可能被用到,该如何做? 这时可以用覆盖索引。就是新建一个联合索引,包含了select语句中要查询的所有字段(select语句要查询的字段不能超出联合索引包含的字段哦,除了主键id),这个时候用explain看执行计划,type是index,不是all了。也就是避免了全表扫
分布式系统之中心副本控制协议(Primary-secondary协议)
最近又把之前接触过一段时间的分布式系统及相关算法拾了起来,继续研究研究。大体将分布式涉及的一些基本原理及算法进行了理解掌握之后,又沿着从简到繁的次序依次记录了下来。 1. 副本协议 简单来讲,副本控制协议是按照指定的流程控制副本数据进行读写行为的协议,使副本满足一定的可用性和一致性要求的分布式协议。一般来说,副本协议需要满足:容错性、可用性和一致性(强一致性、会话一致性、最终一致性)。 按照
EJB3(中文版) 第七集 Secondary Tables
EJB规范允许映射一个实体到多个表,你可以通过使用@SecondaryTable批注.Customer组件映射它的地址属性到一个分开的ADDRESS表.首先定义第二个表.@Entity@Table(name = "CUSTOMER")@SecondaryTable(name = "EMBEDDED_ADDRESS", join = {@JoinColumn(name = "ADDRESS_
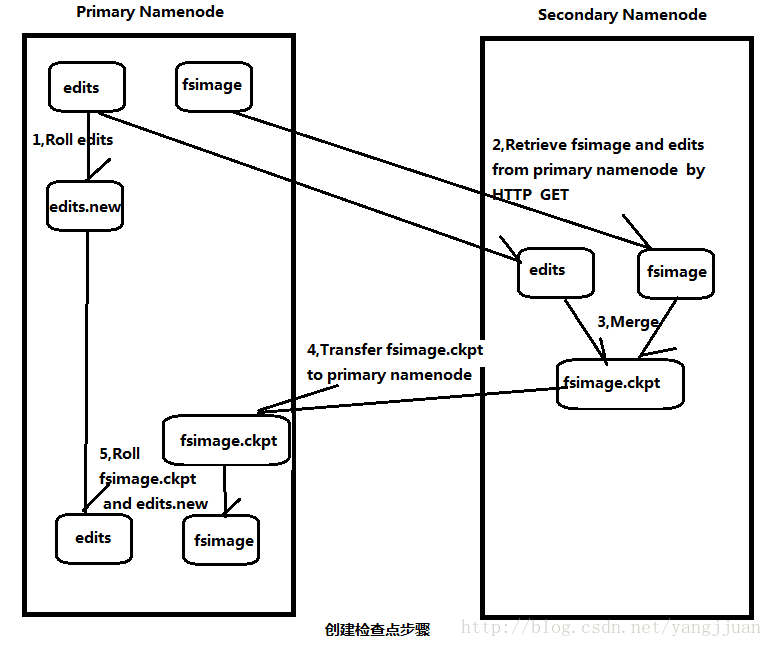
浅析 Secondary NameNode(辅助namenode)
浅析 Secondary NameNode(辅助namenode) 在初学Hadoop时,有个让人疑惑的概念:Secondary NameNode,也叫辅助namenode。从命名看,好像是第二个namenode,用于备份主namenode,在主namenode失败后启动。那么,Secondary NameNode的作用是什么?是如何工作的? 一,NameNode HDFS集群有两类节点以管
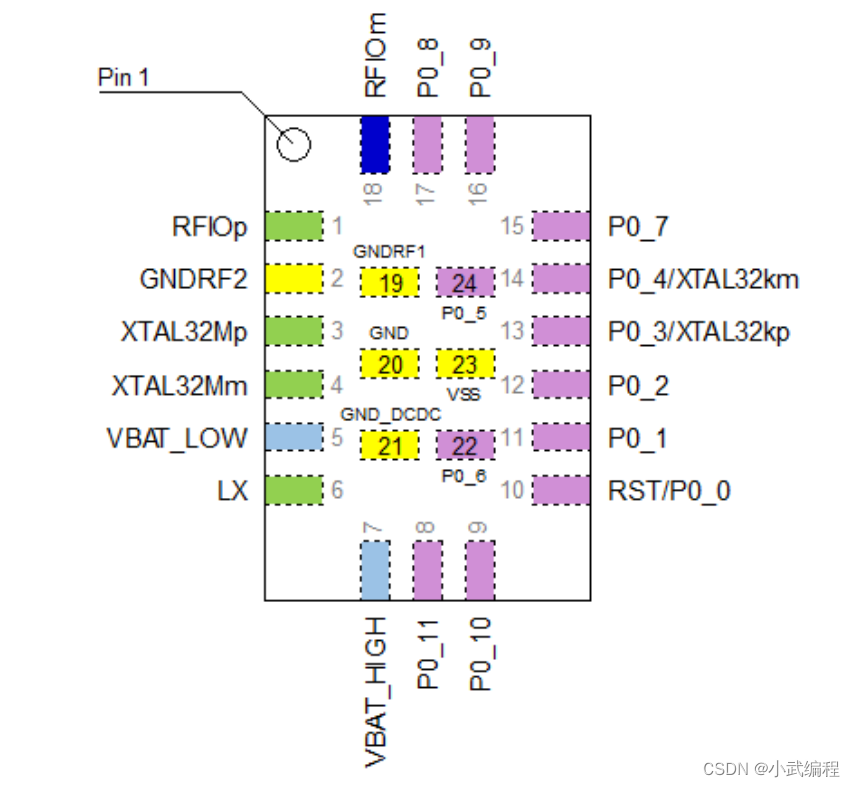
DA14531平台secondary_bootloade工程修改笔记
DA14531平台secondary_bootloade工程修改笔记 1.支持在线仿真 初始时加入syscntl_load_debugger_cfg(); 表示可以重复Jlink连接调试仿真 2.支持串口烧录,和支持单线线写 utilities\secondary_bootloader\includes\bootloader.h /************** 2-wire UART
PSSP之特征提取(PSSP protein secondary structure prediction)
PSSP之特征提取(PSSP protein secondary structure prediction) One-hot encoding AACPSSM encodingSVM 分类优化之特征清洗 One-hot encoding AAC 维度为20+3(BXZ)。 PSSM encoding fasta文件psi-blast程序+protein db(nr db 4

配置Log shipping失败Could not retrieve copy settings for secondary ID
配置Log Shipping的时候Copy和Restore的Job一直失败,错误如下: ***Error: Couldnot retrieve copy settingsfor secondary ID '[removed]'.(Microsoft.SqlServer.Management.LogShipping)*** ***Error: The specified agent_id B
Msg 3059 This BACKUP or RESTORE command is not supported on a database mirror or secondary replica
配置好 2012 AlwaysOn High availability Group就想体验一下在辅助数据库做备份的新功能。在辅助服务器备份,这样可以减轻主服务器的负载(非常好的一项改进,以前Databasemirroring辅助数据库是不可以访问的)。 但是备份的时候却报错: Backup databasetesttodisk ='c:\test.bak' Msg 305
退役笔记N#MySQL = lambda sql : sql + ' Source Code 4 Secondary Buffer Pool For InnoDB '
http://code.google.com/p/david-mysql-tools/wiki/innodb_secondary_buffer_pool
解读Secondary NameNode的功能
最近有朋友问我Secondary NameNode的作用,是不是NameNode的备份?是不是为了防止NameNode的单点问题?确实,刚接触Hadoop,从字面上看,很容易会把Secondary NameNode当作备份节点;其实,这是一个误区,我们不能从字面来理解,阅读官方文档,我们可以知道,其实并不是这么回事,下面就来赘述下Secondary NameNode的作用。 在Hadoop中,有

Zygote Secondary:加速应用启动的未来之路
Zygote Secondary:加速应用启动的未来之路 1. 引言 在现代的移动应用开发中,启动速度和响应性能是用户体验的重要方面。然而,传统的 Android 进程管理方式在启动应用时会出现性能瓶颈,导致启动时间过长和资源占用过多。为了解决这一问题,Google 引入了一个创新的技术——Zygote Secondary。 Zygote Secondary 的概念和定义 Zygote