retromae专题

基于自动编码器的预训练模型方法模型预训练方法RetroMAE和RetroMAE-2
文章目录 RetroMAERetroMAE详情编码解码增强解码 RetroMAE-2RetroMAE-2详情编码[CLS]解码OT解码和训练目标向量表征 总结参考资料 RetroMAE RetroMAE 出自论文《RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
RetroMAE论文阅读
1. Introduction 在NLP常用的预训练模型通常是由token级别的任务进行训练的,如MLM和Seq2Seq,但是密集检索任务更倾向于句子级别的表示,需要捕捉句子的信息和之间的关系,一般主流的策略是自对比学习(self-contrastive learning)和自动编码(auto-encoding)。 self-contrastive learning的效果会被数据增强的质量所限
![[论文笔记]RetroMAE](https://img-blog.csdnimg.cn/img_convert/7e97dd435dd42fbbbb647c5f8d92549e.png)
[论文笔记]RetroMAE
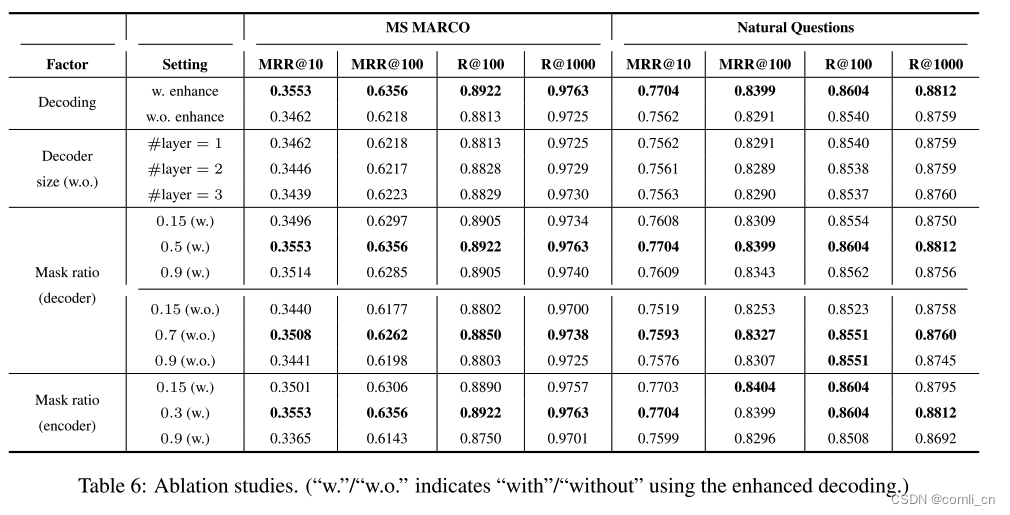
引言 RetroMAE,中文题目为 通过掩码自编码器预训练面向检索的语言模型。 尽管现在已经在许多重要的自然语言处理任务上进行了预训练,但对于密集检索来说,仍然需要探索有效的预训练策略。 本篇工作,作者提出RetroMAE,一个新的基于掩码自编码器(Masked Auto-Encoder,MAE)的面向检索的预训练范式。主要有三个关键设计: 一个新颖的MAE工作流,其中输入句子用不同的掩码
[论文笔记]RetroMAE
引言 RetroMAE,中文题目为 通过掩码自编码器预训练面向检索的语言模型。 尽管现在已经在许多重要的自然语言处理任务上进行了预训练,但对于密集检索来说,仍然需要探索有效的预训练策略。 本篇工作,作者提出RetroMAE,一个新的基于掩码自编码器(Masked Auto-Encoder,MAE)的面向检索的预训练范式。主要有三个关键设计: 一个新颖的MAE工作流,其中输入句子用不同的掩码