本文主要是介绍RetroMAE论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Introduction
在NLP常用的预训练模型通常是由token级别的任务进行训练的,如MLM和Seq2Seq,但是密集检索任务更倾向于句子级别的表示,需要捕捉句子的信息和之间的关系,一般主流的策略是自对比学习(self-contrastive learning)和自动编码(auto-encoding)。
- self-contrastive learning的效果会被数据增强的质量所限制,且需要大量的负样本,而auto-encoding不受制于这两个问题
- auto-encoding的研究重点在于encoding-decoding workflow的设计,对数据要求不高,但是下面两个因素会影响基于自动编码方法的性能:重建任务必须对编码质量有足够的要求;预训练数据需要被充分利用。
本文的作者针对上面的两个因素,提出了一种面向检索的基于自动编码的预训练模型–RetroMAE:
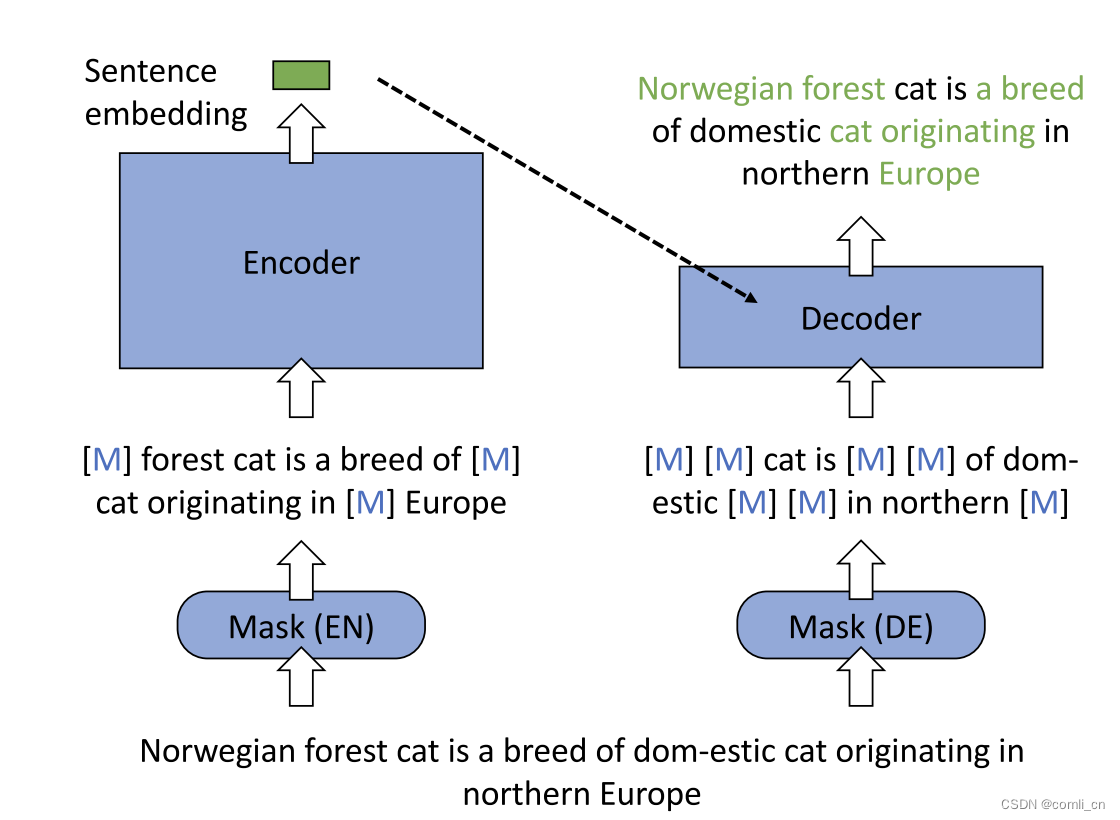
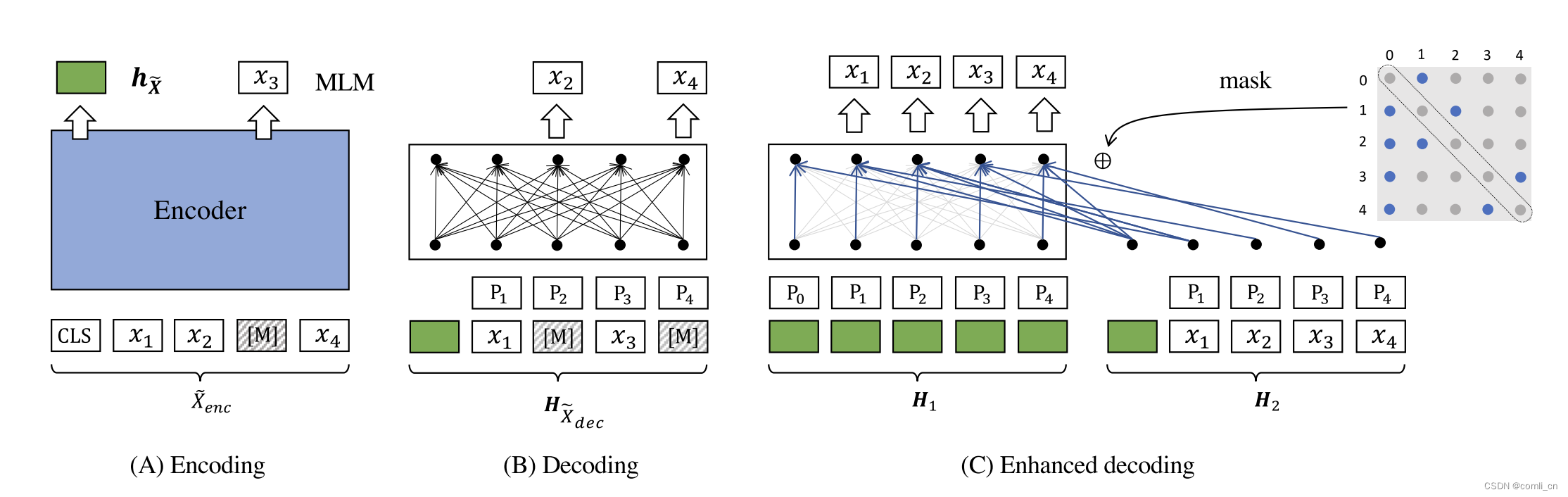
- 全新的自动编码流程:输入句子被掩码两次,第一次的掩码结果输入到编码器生成句子嵌入,另一个掩码结果结合生成的句子嵌入,输入到解码器中,通过MLM恢复原始句子;
- 非对称的结构:编码器是一个全尺寸的BERT,用来生成有区别的句子嵌入;解码器只有一个单层的transformer。Encoder部分是一个全尺寸的BERT(有12层以及768个隐藏维度),Decoder部分是一个单层的Transformer
- 非对称的掩码率:编码器的输入掩码率为15%-30%;解码器的掩码率为50%-70%。
总的来说:输入的句子在进入Encoder之前先进行15%~30%的适度mask,经过Encoder之后生成Sentence embedding;输入的句子在进入Decoder之前先进行50%~70%的mask,然后与Sentence embedding一起通过Decoder还原Sentence
论文
2. RetroMAE模型的优势
- 传统的自回归可能会在解码过程中注意前缀(与GPT的mask方式相似),且传统的MLM(Masked Language Model)只mask一个较小比例的输入token(15%)。而RetroMAE会mask掉大部分的decoding输入,且使用简单的单层transformer作为decoder,这样的话在重建输入时仅仅利用decoder的input就不够了,会促使encoder去捕捉输入的深层语义信息。
- 确保了训练信号完全由input sentence生成,是由自己提出的enhanced decoding实现的
3. 实现细节
- 选择[CLS] token的最后一个hidden state作为sentence embedding
- 在Decoder阶段masked input直接和sentence embedding进行拼接
-
- 式(1)是sentence embedding的生成,输入通过编码器生成embedding
- 式(2)是将sentence embedding和masked input拼在一起,其中 e x i e_{xi} exi表示token x i x_i xi的嵌入, p i p_i pi表示位置嵌入
- 式(3)是还原输入的过程,CE表示cross-entropy loss
- 图C的M矩阵表示第i个token是由第 i i i行可见的上下文重建的(可见的是蓝色的点),比如第0个token是由第1个context重建的,第1个token是由第0个和第2个token决定的。
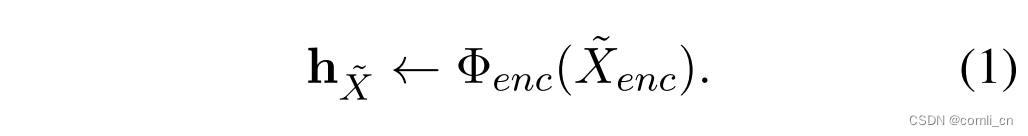
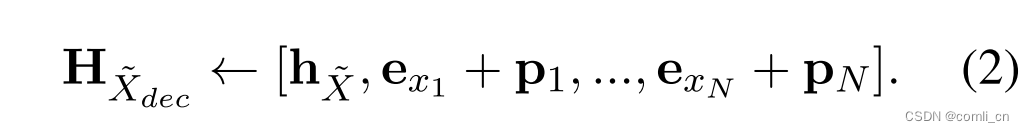
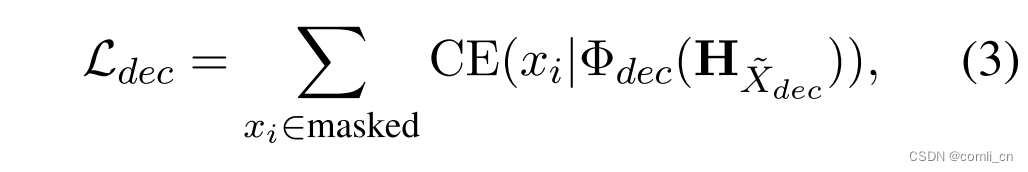
-
Enhanced Decoding
从(2)和(3)两个式子中可以看到交叉熵损失只能从被掩码的tokens中进行训练获得,而且,每次重建都是基于相同的上下文,即 H X d e c H_{X_{dec}} HXdec。作者认为满足下列条件可以进一步增强预训练的效果:- 在输入句子中获得更多的训练信号;
- 基于多样的上下文执行重建任务。
所以作者提出了通过双流自我注意力和特定位置注意力掩码的增强解码,具体来说,作者生成了两个输入流: H 1 H_1 H1(query)和 H 2 H_2 H2 (context),解码操作(图C):
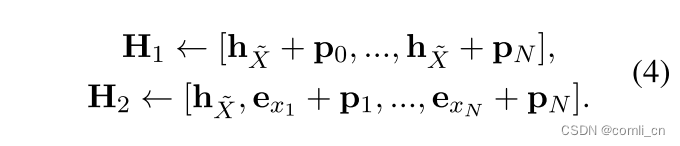
其中h_x是sentence embedding,e_x_i是token embedding(没有被掩码的token embedding),p_i是position embedding。然后作者引进了特定位置的注意力掩码矩阵M,自注意力计算如下:
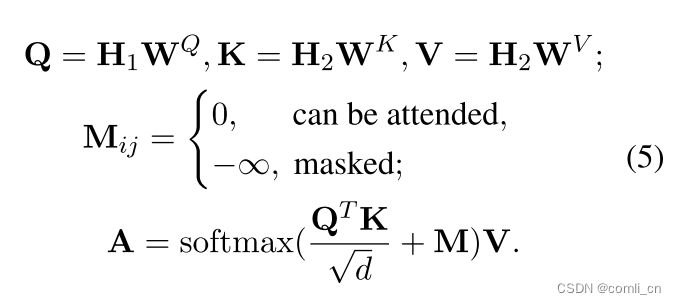
在原始的注意力机制中,Q、K、V的计算都是同一输入,而作者计算Q时选用 H 1 H_1 H1作输入,计算K和V时用 H 2 H_2 H2作输入,这样就可以基于的是多样的上下文输入进行重建句子。然后输出的A和 H 1 H_1 H1进行残差连接被用来重建原始输入,通过以下目标函数进行优化:
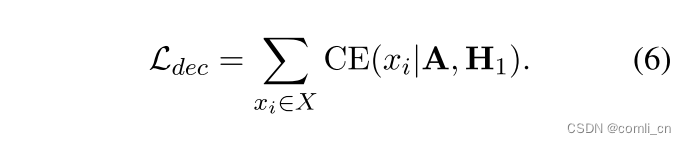
最终的目标函数是编码器损失和解码器损失之和。
要知道每个token x i x_i xi是基于对矩阵M的第 i i i行可见的上下文进行重建的,所以根据下面的规则生成掩码矩阵:
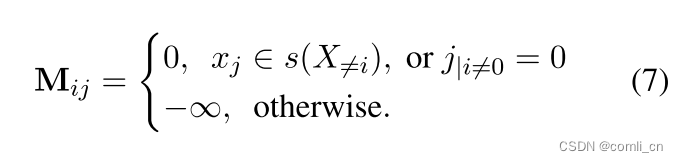
当我们重建 x i x_i xi这个token时,需要找出不同的上下文,所以在这里进行了抽样,s指的是抽样的token的集合, x j ∈ s ( X ≠ i ) x_j\in s(X_{\ne i}) xj∈s(X=i)表示当 x j x_j xj在抽样的token里,或者当 i ≠ 0 i\ne 0 i=0且 j = 0 j=0 j=0时,该位置在掩码矩阵中的值设为0,其它位置的值设为 − ∞ -\infty −∞,如图C所示。如此一来,模型可以获得更多的训练信号
- 整体的RetroMAE算法如下所示:

4. Experiment
作者评估了由 RetroMAE 的预训练编码器生成的句子嵌入的检索性能,其中探讨了两个主要问题:
(1) 与通用预训练模型和面向检索的预训练模型相比,RetroMAE 对零样本和有监督的密集检索的影响。
(2)RetroMAE中四个技术因素的影响:增强解码、解码器大小、解码器掩码率和编码器掩码率。
main results:
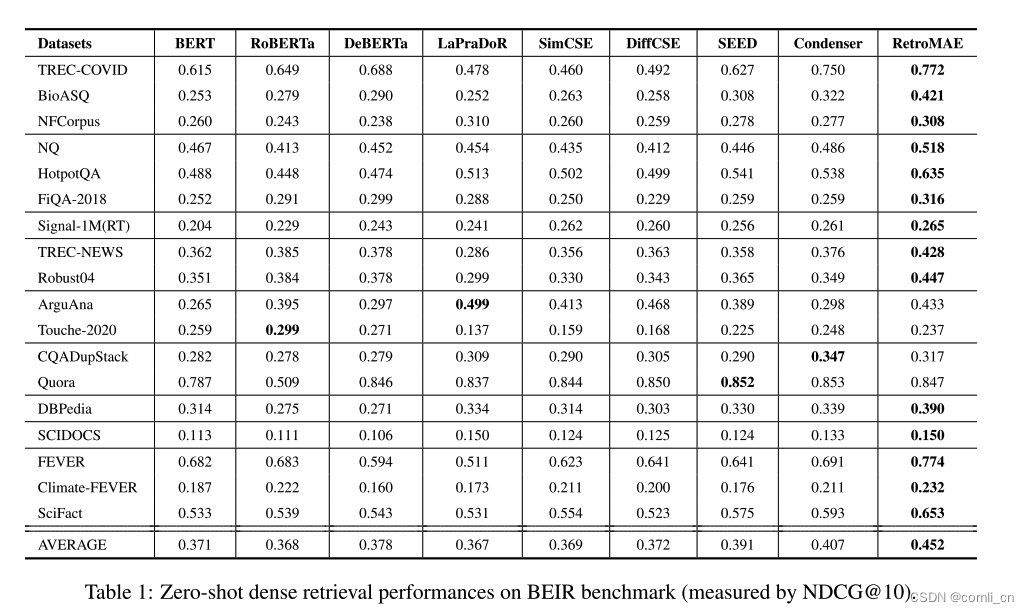
- 在BEIR基准上进行零样本密集检索性能对比
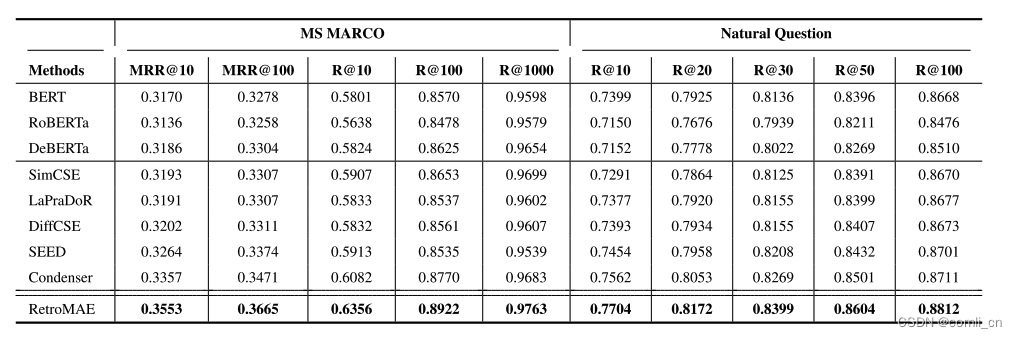
- 基于DPR微调方法的有监督评估结果
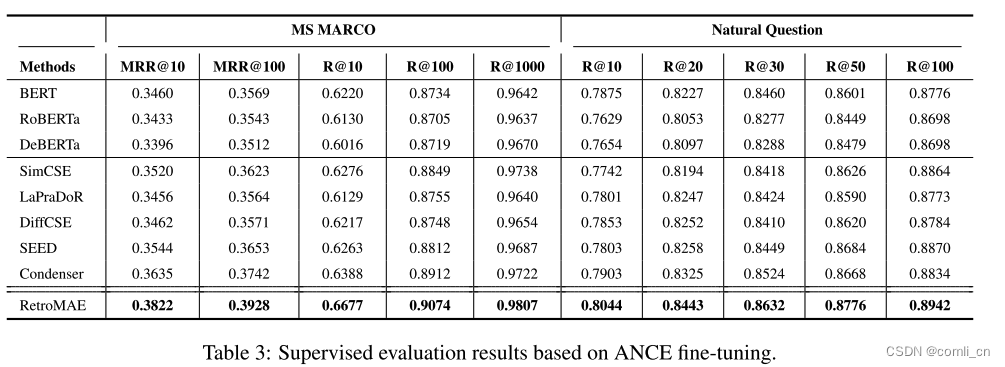
- 基于ANCE微调方法的有监督评估结果
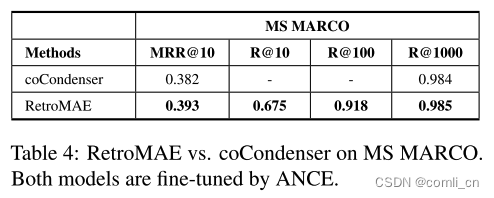
- 与同类方法的预训练模型 coCondenser的对比
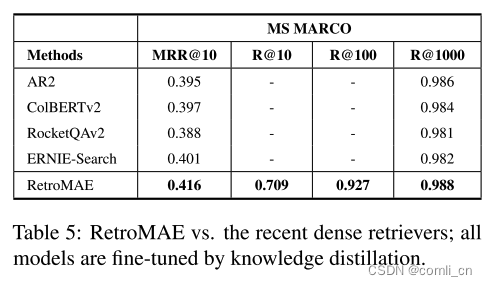
- 通过知识蒸馏方法的性能对比
消融实验
解码方法、解码器规模、解码器的掩码率和编码器的掩码率的影响:
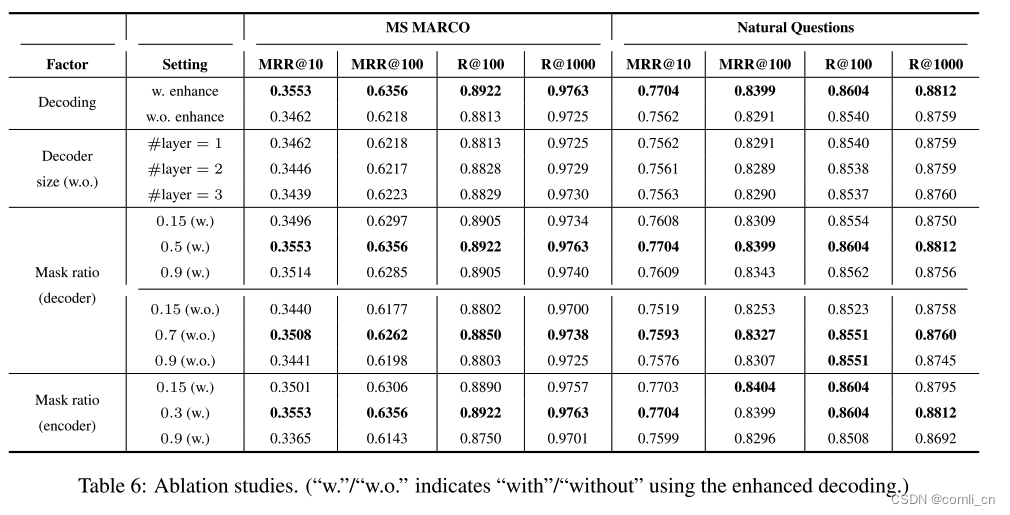
可以看到不使用增强解码的性能明显比使用增强解码的性能要低;
虽然解码器的transformer的层数从1增加到3性能并没有下降多少,但是会产生严重的计算成本,所以结合准确率和计算成本,单层的transformer更适合解码器;
对于解码器的掩码率带来的影响,作者分了两个部分:一个是使用增强解码,另一部分未使用增强解码。可以看到随着掩码率的提升,最终的性能也会跟着提升,使用增强解码的性能在掩码率为0.5时到达峰值,未使用增强解码的一组的性能在掩码率为0.7时达到峰值;
对于编码器的掩码率,作者发现调整为30%时性能会提升,但是增加到90%时性能会急剧下降,这表示适当提高掩码率有利于增强模型的学习能力,但是过高的掩码率会导致原本的语义信息的缺失。
5. conclusion
作者提出了 RetroMAE,这是一种新的掩码自动编码框架,用于面向检索的预训练语言模型:输入句子被随机的掩码,然后输入到编码器和解码器,然后句子嵌入与解码器的掩码输入进行结合以重建原始输入。作者引入了非对称模型结构(全尺寸编码器和单层解码器)和非对称掩码率(编码器的中等焱玛利率和解码器的高掩码率),这使得重建要求足够高。作者还提出了增强解码,充分利用了预训练数据。可以看到作者提出的模型在零样本密集检索以及有监督的密集检索性能都有所提升。
这篇关于RetroMAE论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)