ranked专题

《BLINKS: Ranked Keyword Searches on Graphs》——论文笔记
ABSTRACT 目前关键词查询的技术缺陷:poor worst-case performance, not taking full advantage of indexes, and high memory requirements. 本文方法:BLINKS, a bi-level indexing and query processing scheme for top-k keyword

ranked-model
为什么80%的码农都做不了架构师?>>> 相当于 acts_as_sortable, 很容易理解。 先来看看常用的方法 scope :rank, lambda { |name|order arel_table[ ranker(name.to_sym).column ]} def ranks *argsself.rankers ||= []ranker = RankedMod

论文复现Ranked batch-mode active learning表述非常好的论文
Reference:[1]Silva, Rodrigo, M, et al. Ranked batch-mode active learning[J]. Information Sciences: An International Journal, 2017. 复现了,效果很好~ 这个是pointwise 版本的 import xlwtimport numpy as npimp

斯坦福大学-自然语言处理入门 笔记 第十八课 排序检索介绍(ranked retrieval)
一、介绍 之前我们的请求都是布尔类型。对于那些明确知道自己的需求并且了解集合体情况的用户而言,布尔类型的请求是很有效的。但是对于大部分的其他用户而言,布尔请求的问题是:大部分用户不熟悉布尔请求;布尔请求比较复杂;布尔请求的结果不是太多就是太少。排序检索应运而生。排序检索返回的是排序好的文档结果,它可以很好地处理布尔请求以及自由文档请求(free text queries),即自然语言的请求。而我
《BLINKS: Ranked Keyword Searches on Graphs》——论文笔记
ABSTRACT 目前关键词查询的技术缺陷:poor worst-case performance, not taking full advantage of indexes, and high memory requirements. 本文方法:BLINKS, a bi-level indexing and query processing scheme for top-k keyword

A Secure and Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data (1)
系统框架 数据拥有者DO构建加密索引树,将加密文档和索引外包给云服务。 云存储服务根据数据使用者Data User发来的数据搜索token和已经存好的加密索引树进行搜索,返回top K个排序结果。 排序的计量方法根据TF-IDF公式计算相似度。 Term Frequency: the number of times a given term appears within a document
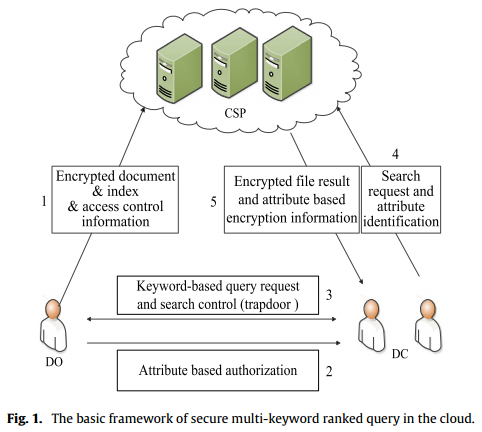
Efficient multi-keyword ranked query over encrypted data in cloud computing (3)
Problem definition 符号含义 Notations 问题描述 Problem description 主要的Roles: Data Owner, DOData Consumer, DCCloud Service Provider, CSP 文件加密使用DES或AES陷门Trapdoor(T)由DO利用它的秘密密钥和DC的查询请求生成,交给DC后用于在CSP上进行查询使用基
斯坦福NLP笔记75 —— Introducing Ranked Retrieval
2019独角兽企业重金招聘Python工程师标准>>> 基本是一些tdidf的基本概念,先跳过。 转载于:https://my.oschina.net/silverhammer/blog/294134
计算机视觉中评价指标计算:Accuracy,Precision,Recall,AP,mAP,Top-1,Top-5,Top-N ranked,IoU
计算机视觉中评价指标计算:Accuracy,Precision,Recall,AP,mAP,Top-1,Top-5,Top-N ranked,IoU 引言对应场景图像分类(image classification)目标检测(object detection) 指标计算准确率(Accuracy),精确度(Precision),召回率(Recall)在image classification中在