qat专题

Vitis AI 进阶认知(Torch量化基础+映射+量化参数+对称性+每通道+PTQ+QAT+敏感性)
目录 1. 介绍 2. 基本概念 2.1 映射函数 2.2 量化参数 2.3 校准 2.4 对称与非对称量化 2.5 Per-Tensor and Per-Channel 2.6 PTQ 2.7 QAT 2.8 敏感性分析 2.6 退火学习率 3. 几点建议 4. 总结 1. 介绍 Practical Quantization in PyTorch | P

如何隐藏RibbonBar的QAT QuickAccessToolBar
方案1: .h文件 class CMyRibbonBar : public CMFCRibbonBar { DECLARE_DYNAMIC(CMyRibbonBar) protected: DECLARE_MESSAGE_MAP() virtual BOOL OnShowRibbonContextMenu(CWnd* pWnd, int x, int y, CMFC
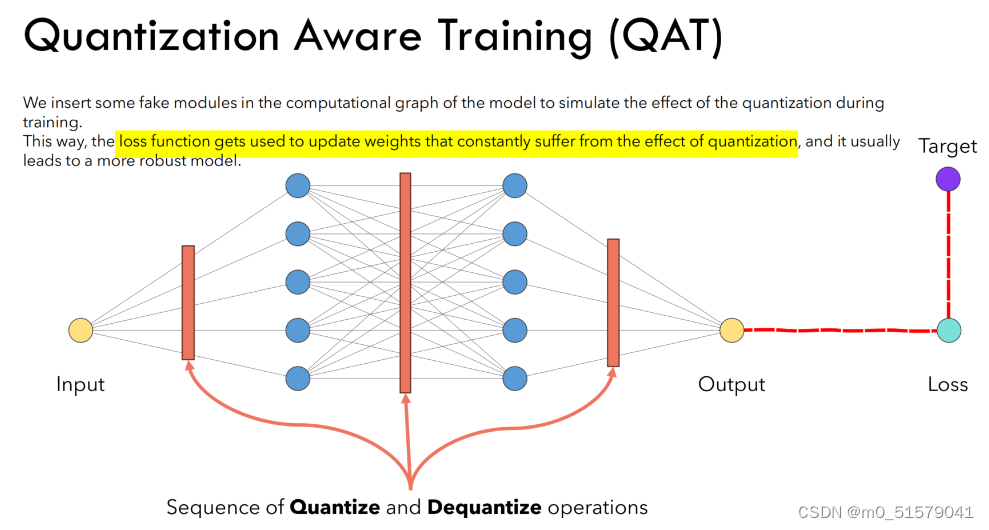
QAT量化 demo
一、QAT量化基本流程 QAT过程可以分解为以下步骤: 定义模型:定义一个浮点模型,就像常规模型一样。定义量化模型:定义一个与原始模型结构相同但增加了量化操作(如torch.quantization.QuantStub())和反量化操作(如torch.quantization.DeQuantStub())的量化模型。准备数据:准备训练数据并将其量化为适当的位宽。训练模型:在训练过程中,使用量化

基于Keras的模型量化(PTQ、QAT)
对PTQ和QAT的详细解释在这篇哦: 《模型量化(三)—— 量化感知训练QAT(pytorch)》 本文给的代码是基于tensorflow 目录 PTQ只量化权重权重和激活值全量化 QAT套路创建和训练模型用QAT克隆和微调预训练模型量化模型评估TF和TFLite PTQ 只量化权重 只是优化了模型大小,对于模型的计算没什么优化,因为W * X时,W要反量化为浮点进行运算

TensorRT模型优化模型部署(七)--Quantization量化(PTQ and QAT)(二)
系列文章目录 第一章 TensorRT优化部署(一)–TensorRT和ONNX基础 第二章 TensorRT优化部署(二)–剖析ONNX架构 第三章 TensorRT优化部署(三)–ONNX注册算子 第四章 TensorRT模型优化部署(四)–Roofline model 第五章 TensorRT模型优化部署(五)–模型优化部署重点注意 第六章 TensorRT模型优化部署(六)–Quanti
yolov8 PTQ和QAT量化实战(源码详解)
文章目录 1. 概述1.1 PTQ 和QAT的量化流程1.1.1 PTQ 量化流程1.1.2 QAT 量化流程 1.2 PTQ 和QAT的优缺点 2. 项目代码的使用2.1 环境安装2.2 代码使用 3. 代码详解3.1 数据校准calibrate3.2 敏感层分析sensitive layer3.2.1 quant模型及calib_dataloader准备3.2.2 校准模型

行业想做Qat些金融职位请务必分清楚
转 行业 | 想做Quant,这些金融职位请务必分清楚! 在Finance行业里,越靠近产生P&L的人赚的钱和权利越多(相对压力和风险也越大),所以纯粹按本职业发展前景(what u would make in mid 30s)来看,排名是: ● buy side quant pm/strategist ● sell side quant/algo trader, sell side
yolov5的qat量化
前两篇文章讲解了yolov5的敏感层分析及ptq量化流程,本篇文章在前两篇文章的基础上,继续讲解yolov5的qat量化流程。 ptq和qat的区别如下所示: qat量化流程如下所示: 首先在数据集上以FP32精度进行模型训练,得到训练好的baseline模型;在baseline模型中插入伪量化节点,进行PTQ得到PTQ后的模型;进行量化感知训练;导出ONNX 模型。 与传统量化方案的使用
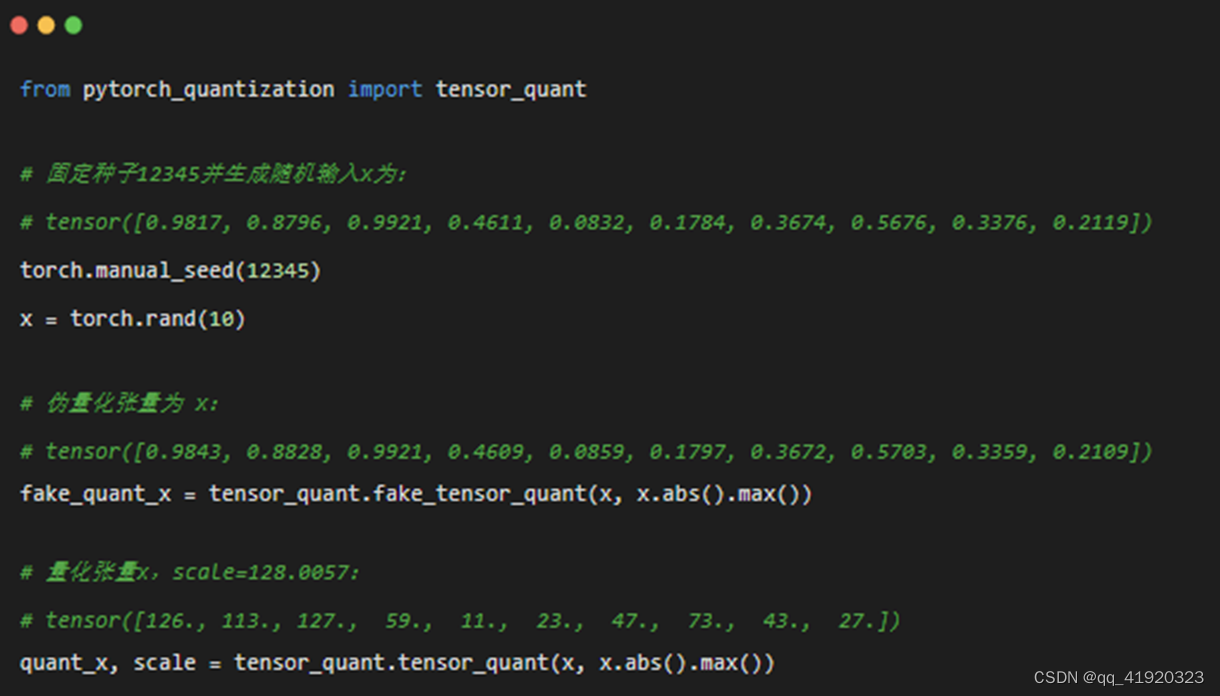
yolov5的pqt、qat量化---1(知识准备工作)
1、Pytorch-Quantization简介 PyTorch Quantization是一个工具包,用于训练和评估具有模拟量化的PyTorch模型。PyTorch Quantization API支持将 PyTorch 模块自动转换为其量化版本。转换也可以使用 API 手动完成,这允许在不想量化所有模块的情况下进行部分量化。例如,一些层可能对量化比较敏感,对其不进行量化可提高任务精度。 PyT
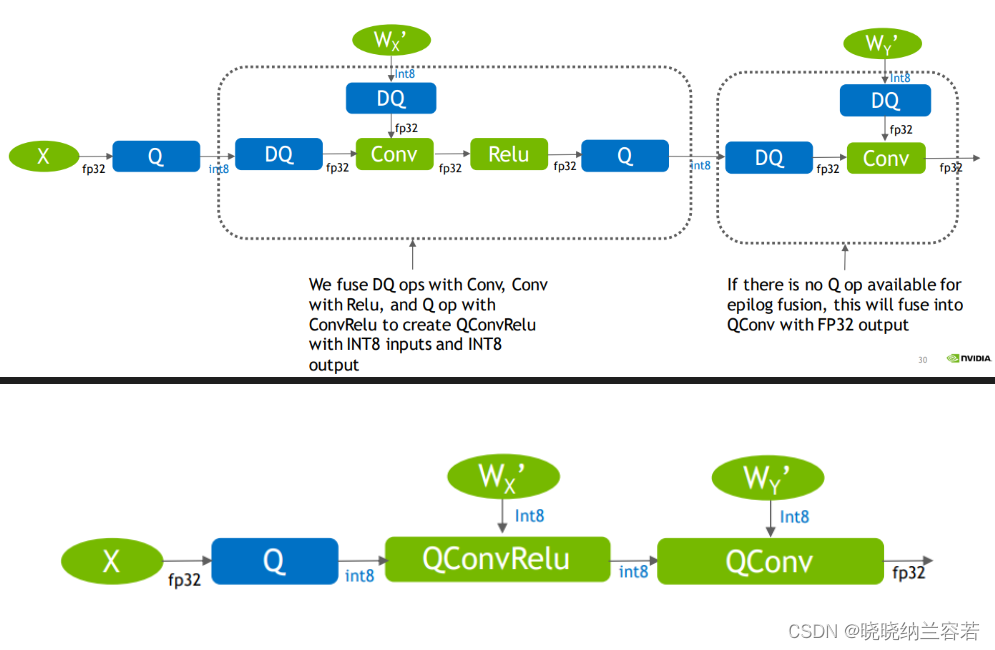
PTQ量化和QAT量化
目录 1--PTQ量化 2--QAT量化 1--PTQ量化 PTQ量化表示训练后量化(Post Training Quantization)。使用一批校准数据对训练好的模型进行校准,将训练好的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练,而只对几个超参数调整就可完成量化过程。(计算每一层的scale) TensorRT提供的PT