pytesseract专题
Opencv学习项目3——pytesseract
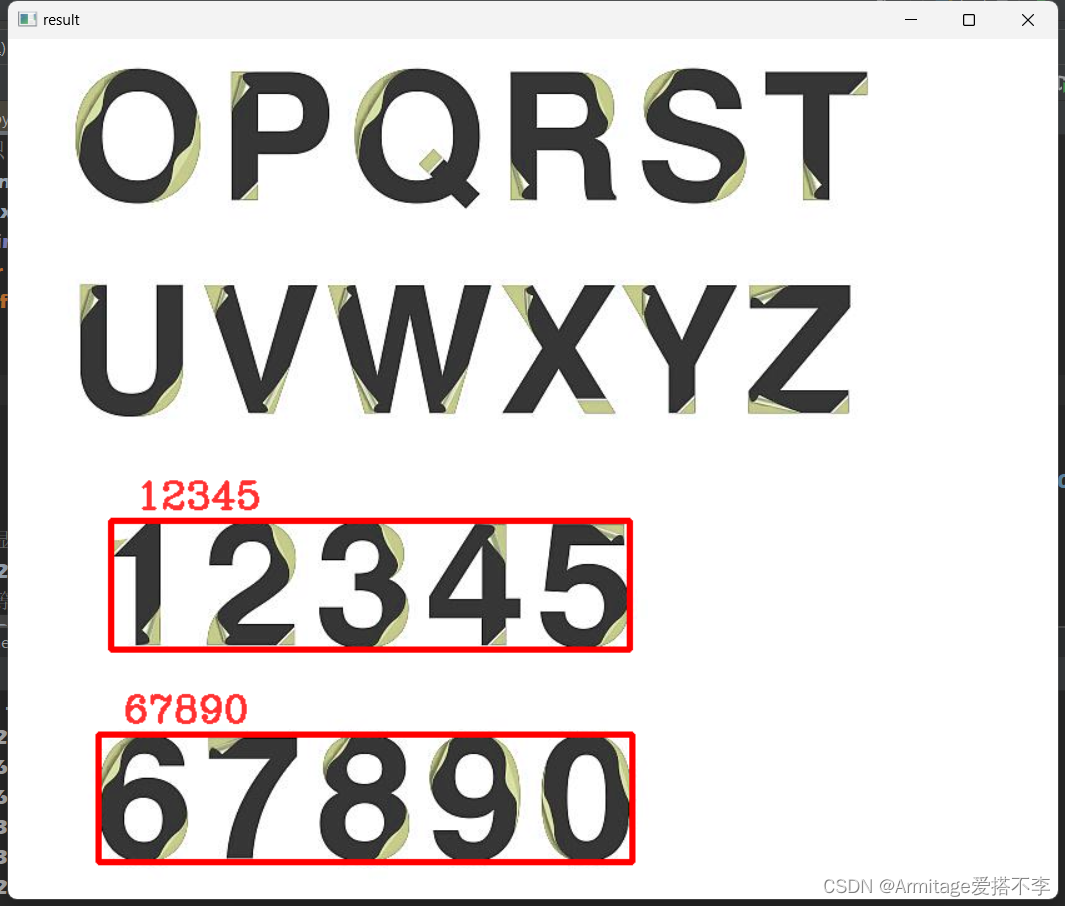
上一次我们使用pytesseract.image_to_data(img)来检测文本,这次我们来只检测数字 项目演示 可以看到,我们只检测了数字其他的并没有检测出来 代码实现 前面两次介绍了opencv的画矩形和设置文本,这次就直接用了,不太明白的可以看之前的博客 import cv2import pytesseractpytesseract.pytesseract.tes

python使用selenium脚本实现网站自动登录,通过百度文字识别(baidu-aip)或pytesseract自动识别验证码信息
使用谷歌浏览器chrome自动登录网页,下载chromedriver.exe并放到项目目录下,选择自己谷歌浏览对应的版本 http://npm.taobao.org/mirrors/chromedriver/ 1、使用之前必须要先安装第三方扩展库 pip install seleniumpip install Imagepip install baidu-aippip instal

python图像识别库-pytesseract
内容目录 一、安装1.安装tesseract OCR1) MAC中安装2) Windows中安装3) 中文报下载 二、pytesseract的简单使用 pytesseract是python的一个用于图像提取的库, 它实际上是对Tesseract OCR引擎的封装。pytesseract使得在Python项目中调用Tesseract变得更加简便,主要用于从图像中提取和识别文本

PIL + pytesseract 玩转验证码图片识别
有时候我们在模拟登陆的时候会遇到图片验证码,如果是简单的数字字母验证码,可以通过图片识别的方法识别验证码,再发送post请求模拟登陆。 验证码图片的爬取可以通过找到某验证码的url,通过python的requests模块get图片资源,这里不做过多介绍。 我们在本地尝试完成验证码图片的识别。本地已经安装Anaconda3,使用Python3。其下均在Anaconda环境进行操作。 1.安装P

python pytesseract使用
##正确使用方法 1.tesseract-orc安装 tesseract-ocr-setup-3.05.00dev.exe下载 2.pytesseract pip install pytesseract 3.设置 tesseract-orc路径 将 C:\Program Files (x86)\Tesseract-OCR添加到系统路径(路径因安装过程而异)修改pytesseract.py文件

使用Pytesseract进行OCR
在Python中,可以使用Tesseract OCR库来识别图片上的文字。Tesseract是一个开源的光学字符识别(OCR)引擎,可以识别多种语言的文本。为了在Python中使用Tesseract,通常会使用pytesseract这个Python库作为Tesseract的一个接口。 安装和配置 安装Tesseract OCR:首先需要在你的系统上安装Tesseract OCR。这可以从Te

Python文字识别自动化处理库之pytesseract使用详解
概要 在当今数字化时代,文字识别技术扮演着越来越重要的角色。Python pytesseract 库是一个强大的工具,能够帮助开发者轻松实现图像中文字的识别。本文将深入探讨 pytesseract 库的原理、功能、使用方法以及实际应用场景,并提供丰富的示例代码,让读者更全面地了解这个工具库。 什么是 Python pytesseract 库? Python pytesseract

pytesseract报错pytesseract安装教程
cmd或者PyCharm终端``pip install pytesseract`进行安装,但是安装完还不能使用。 tesseract-OCR下载地址:[http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe ] 下载完成之后双击打开安装,一直下一步(next),知道出现安装路径界面,记住安装路径
pytesseract中文OCR安装详细步骤(windows环境)
下载tesseract 安装依赖包pillow pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow 安装Tesseract-OCR 直接下载地址: https://digi.bib.uni-mannheim.de/tesseract/ 下载v5-2019版本; 安装exe时,选择安装中文简体和繁体的语言包,自定义安装路

openCV实战-系列教程14:文档扫描OCR识别下(灰度/高斯滤波/边缘检测/轮廓检测/透视变换/tesseract OCR/pytesseract/OCR文字识别)项目实战、源码解读
🧡💛💚💙💜OpenCV实战系列总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 上篇内容: openCV实战-系列教程11:文档扫描OCR识别上(图像轮廓/模版匹配)项目实战、源码解读 中篇内容: openCV实战-系列教程13:文档扫描OCR识别中(图像轮廓/模版匹配)项目实战、源码解读 7、pytesser
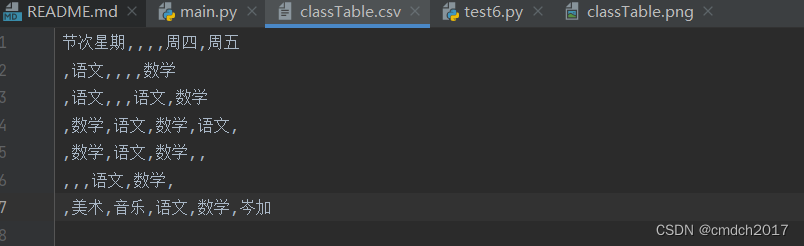
github上的python图片转excel,pytesseract安装相关问题
问题1:明明都pip install pytesseract,但是就是安装不上 pytesseract 未安装 链接: https://pan.baidu.com/s/1I4HzCgO4mITWTcZFkdil6g?pwd=afes 提取码: afes 安装后一路next,然后配置环境变量 C:\Program Files\Tesseract-OCR 新建一个系统变量 问题2

Python - PIL-pytesseract-tesseract验证码识别
N天前实现了简单的验证识别,这玩意以前都觉得是高大上的东西,一直没有去研究,这次花了点时间研究了一下,当然只是一些基础的东西,高深的我也不会,分享一下给大家吧。 关于python验证码识别库,网上主要介绍的为pytesser及pytesseract,其实pytesser的安装有一点点麻烦,所以这里我不考虑,直接使用后一种库。 要安装pytesseract库,必须先安装其依赖的PIL及tesse

实战:使用 OpenCV 和 PyTesseract 对文档进行 OCR
随着世界各地的组织都希望将其运营数字化,将物理文档转换为数字格式是非常常见的。这通常通过光学字符识别 (OCR) 完成,其中文本图像(扫描的物理文档)通过几种成熟的文本识别算法之一转换为机器文本。当在干净的背景下处理打印文本时,文档 OCR 的性能最佳,具有一致的段落和字体大小。 在实践中,这种情况远非常态。发票、表格甚至身份证明文件的信息分散在整个文件空间中,这使得以数字方式提取相关数据的任务
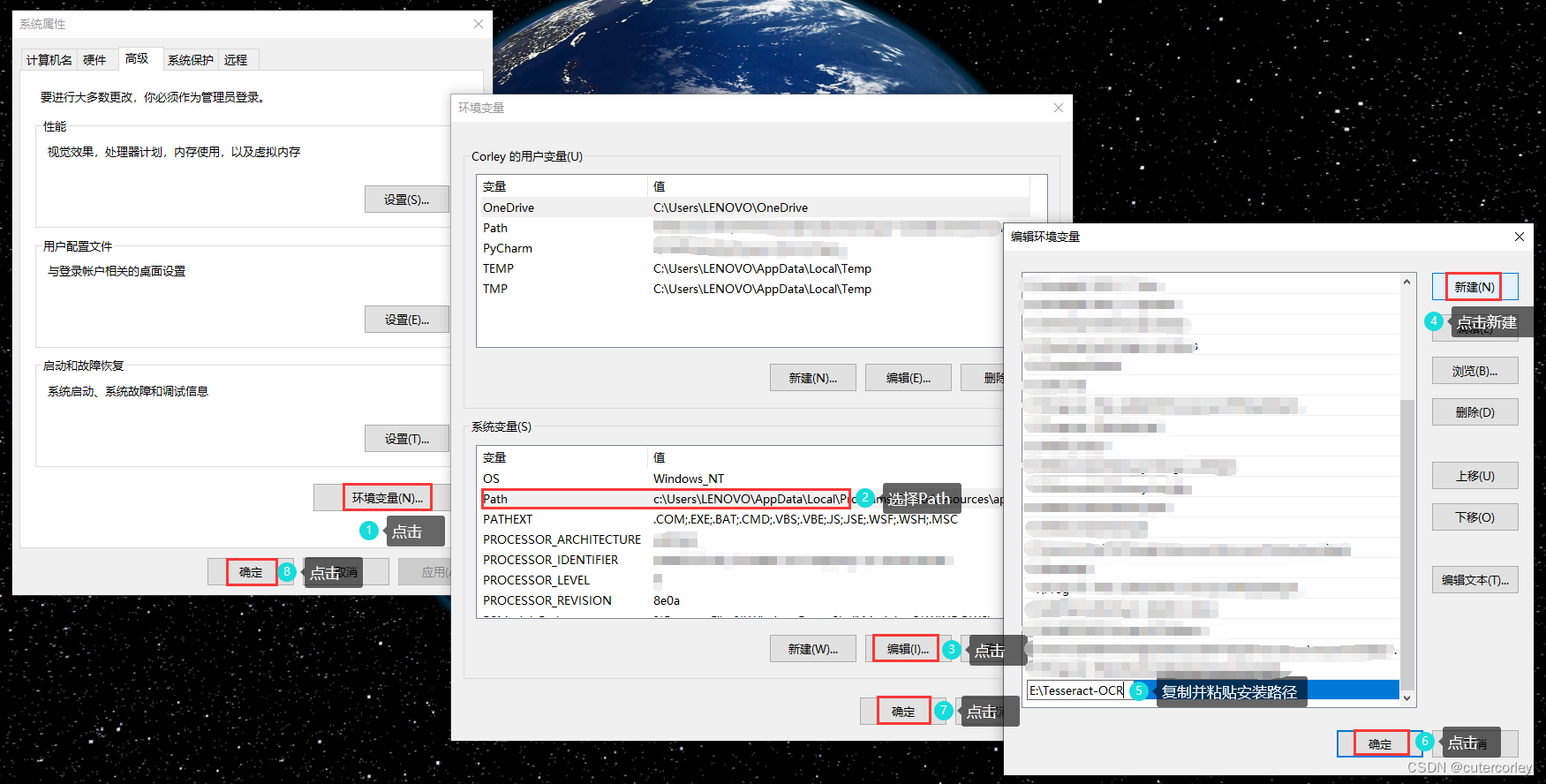
Windows安装Tesseract OCR与Python中使用pytesseract进行文字识别
文章目录 前言一、下载并安装Tesseract OCR二、配置环境变量三、Python中安装使用pytesseract总结 前言 Tesseract OCR是一个开源OCR(Optical Character Recognition)引擎,用于从图像中提取文本。Pytesseract是Tesseract OCR的Python封装,它使得在Python中使用Tesseract OC
Windows安装Tesseract OCR与Python中使用pytesseract进行文字识别
文章目录 前言一、下载并安装Tesseract OCR二、配置环境变量三、Python中安装使用pytesseract总结 前言 Tesseract OCR是一个开源OCR(Optical Character Recognition)引擎,用于从图像中提取文本。Pytesseract是Tesseract OCR的Python封装,它使得在Python中使用Tesseract OC

Windows pytesseract image_to_osd Invalid resolution 0 dpi. Using 70 instead. Too few characters报错及解决
Windows pytesseract image_to_osd Invalid resolution 0 dpi. Using 70 instead. Too few characters报错及解决 1. 安装 python3.7+ pip install pytesseract==0.1.9 安装tesseract-ocr(配置path环境变量或者在代码中指定tesseract_cm

python pytesseract实现图片内容识别
python pytesseract实现图片内容识别 1.安装PIL pip install pillow 2.安装pytesser3(我提前安装过了) pip install pytesser3 3.安装pytesseract pip install pytesseract 4.安装autopy3 链接: https://pan.baidu.com/s/1fnsvIiKCdUWXRFNlV

Python+OpenCV+pytesseract 识别 银行卡号
首先给大家看下什么是OCR-A字体: 尽管现代OCR系统不需要专门的字体(如OCR-A),但仍被广泛应用于身份证,报表和信用卡。 下面给出具体的教程: 1. OCR通过模板匹配与OpenCV结合 在本节中,我们将使用Python + OpenCV实现我们的模板匹配算法,以自动识别信用卡数字。 为了实现这一点,我们需要应用一些图像处理操作,包括阈

Python将PDF按页拆分为图片,并OCR识别为文本【windows,主要使用模块/工具包括wand、pytesseract、PIL等,附下载及安装】
Python将PDF按页拆分为图片,并OCR识别为文本 下载所需安装包并完成安装1、下载并安装tesseract-ocr2、下载并安装imagemagic3、下载并安装Ghostscript PFD转成jpeg图片,并识别成文本 下载所需安装包并完成安装 1、下载并安装tesseract-ocr 链接:https://pan.baidu.com/s/1FypYuviozcC4J