本文主要是介绍github上的python图片转excel,pytesseract安装相关问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题1:明明都pip install pytesseract,但是就是安装不上
pytesseract 未安装
链接: https://pan.baidu.com/s/1I4HzCgO4mITWTcZFkdil6g?pwd=afes 提取码: afes
安装后一路next,然后配置环境变量
C:\Program Files\Tesseract-OCR
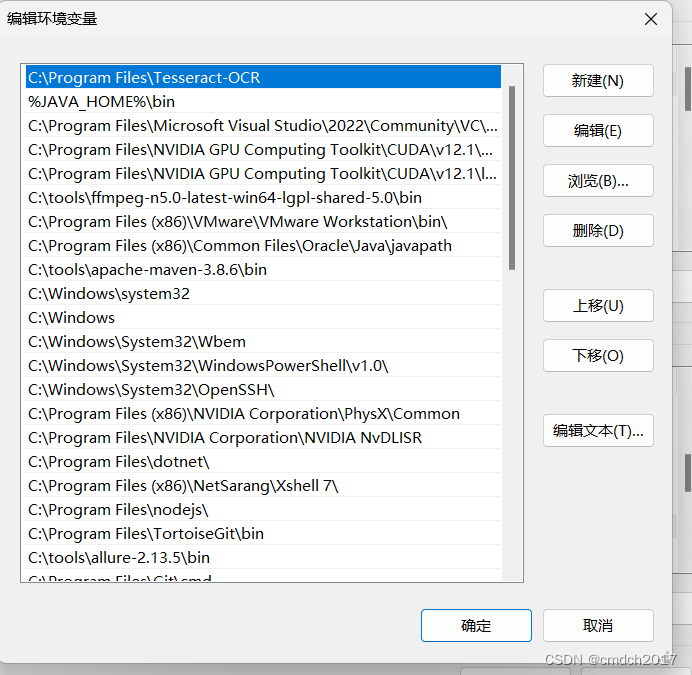
新建一个系统变量
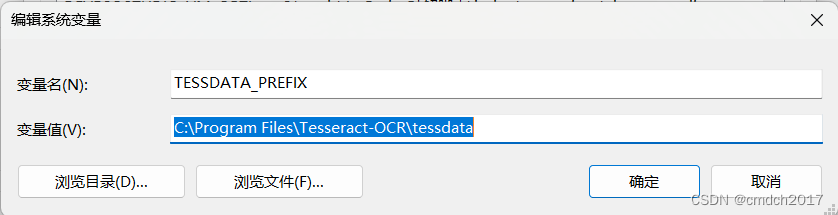
问题2:程序如果报错信息:
Error opening data file D:\\Tesseract-OCR/tessdata/chi_sim.traineddata
通过如下路径下载模型:https://github.com/tesseract-ocr/tessdata/blob/main/chi_sim.traineddata
存储到tessdata目录下,再次运行,程序成功执行。
python图片转excel
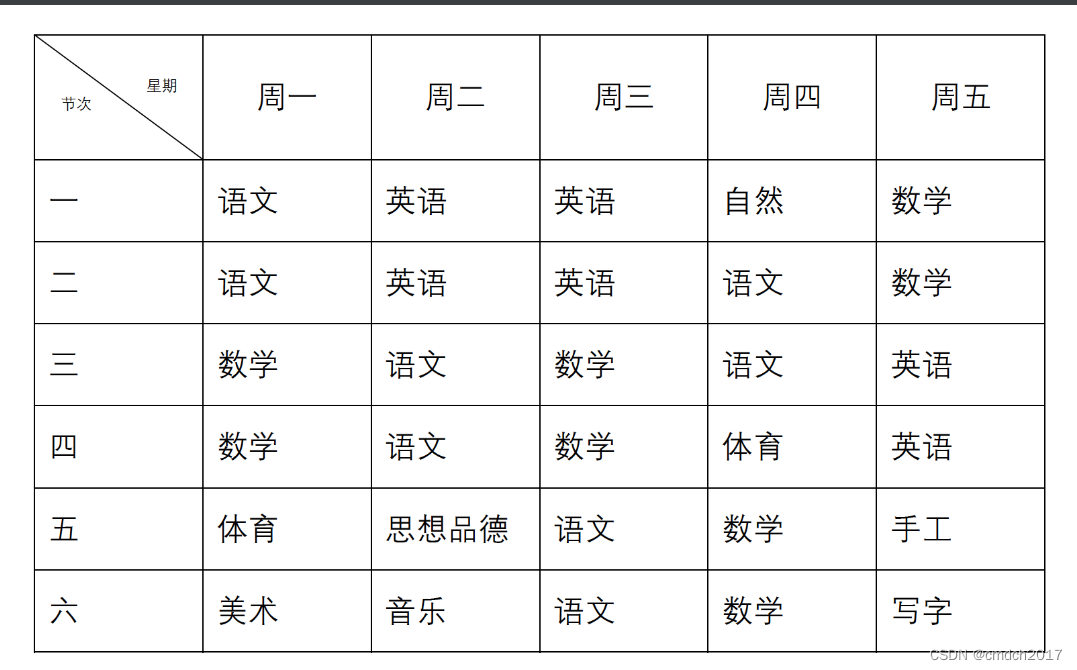
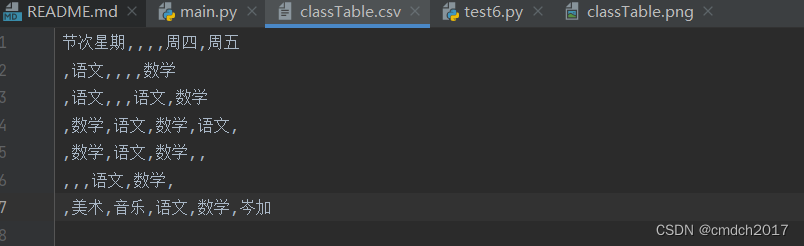
我的运行效果不是太好,好像说要训练什么的,我在代码中加了一行避免报错
if len(item) >= 6:
脚本思路大致是:
使用OpenCV (cv2)读取图像文件。
将图像转换为灰度图,并应用自适应阈值处理,生成二值图像。
使用形态学运算识别表格的水平和垂直线。
检测线的交点,定位表格的单元格。
使用Tesseract OCR (pytesseract)从每个单元格提取文本。
清理提取的文本,去除特殊字符。
将提取的数据写入CSV文件。
import osimport cv2
import numpy as np
import pytesseract
from PIL import Image
import csv
import re
import jsondef parse_pic_to_excel_data(src):raw = cv2.imread(src, 1)# 灰度图片gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY)# 二值化binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)cv2.imshow("binary_picture", binary) # 展示图片rows, cols = binary.shapescale = 40# 自适应获取核值 识别横线kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1))eroded = cv2.erode(binary, kernel, iterations=1)dilated_col = cv2.dilate(eroded, kernel, iterations=1)cv2.imshow("excel_horizontal_line", dilated_col)# cv2.waitKey(0)# 识别竖线scale = 20kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale))eroded = cv2.erode(binary, kernel, iterations=1)dilated_row = cv2.dilate(eroded, kernel, iterations=1)cv2.imshow("excel_vertical_line", dilated_row)# cv2.waitKey(0)# 标识交点bitwise_and = cv2.bitwise_and(dilated_col, dilated_row)cv2.imshow("excel_bitwise_and", bitwise_and)# cv2.waitKey(0)# 标识表格merge = cv2.add(dilated_col, dilated_row)cv2.imshow("entire_excel_contour", merge)# cv2.waitKey(0)# 两张图片进行减法运算,去掉表格框线merge2 = cv2.subtract(binary, merge)cv2.imshow("binary_sub_excel_rect", merge2)new_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))erode_image = cv2.morphologyEx(merge2, cv2.MORPH_OPEN, new_kernel)cv2.imshow('erode_image2', erode_image)merge3 = cv2.add(erode_image, bitwise_and)cv2.imshow('merge3', merge3)# cv2.waitKey(0)# 识别黑白图中的白色交叉点,将横纵坐标取出ys, xs = np.where(bitwise_and > 0)# 纵坐标y_point_arr = []# 横坐标x_point_arr = []# 通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点# 这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变)i = 0sort_x_point = np.sort(xs)for i in range(len(sort_x_point) - 1):if sort_x_point[i + 1] - sort_x_point[i] > 10:x_point_arr.append(sort_x_point[i])i = i + 1x_point_arr.append(sort_x_point[i]) # 要将最后一个点加入i = 0sort_y_point = np.sort(ys)# print(np.sort(ys))for i in range(len(sort_y_point) - 1):if (sort_y_point[i + 1] - sort_y_point[i] > 10):y_point_arr.append(sort_y_point[i])i = i + 1# 要将最后一个点加入y_point_arr.append(sort_y_point[i])print('y_point_arr', y_point_arr)print('x_point_arr', x_point_arr)# 循环y坐标,x坐标分割表格data = [[] for i in range(len(y_point_arr))]for i in range(len(y_point_arr) - 1):for j in range(len(x_point_arr) - 1):# 在分割时,第一个参数为y坐标,第二个参数为x坐标cell = raw[y_point_arr[i]:y_point_arr[i + 1], x_point_arr[j]:x_point_arr[j + 1]]cv2.imshow("sub_pic" + str(i) + str(j), cell)# 读取文字,此为默认英文# pytesseract.pytesseract.tesseract_cmd = 'E:/Tesseract-OCR/tesseract.exe'text1 = pytesseract.image_to_string(cell, lang="chi_sim")# 去除特殊字符text1 = re.findall(r'[^\*"/:?\\|<>″′‖ 〈\n]', text1, re.S)text1 = "".join(text1)print('单元格图片信息:' + text1)data[i].append(text1)j = j + 1i = i + 1# cv2.waitKey(0)return datadef write_csv(path, data):with open(path, "w", newline='') as csv_file:writer = csv.writer(csv_file, dialect='excel')for item in data:# Check if the item list has at least 6 elements before accessing themif len(item) >= 6:writer.writerow([item[0], item[1], item[2], item[3], item[4], item[5]])if __name__ == '__main__':file = "classTable.png"# 解析数据data = parse_pic_to_excel_data(file)# 写入excelwrite_csv(file.replace(".png", ".csv"), data)下面是原作者写的博客
https://blog.csdn.net/sc9018181134/article/details/104577247
这篇关于github上的python图片转excel,pytesseract安装相关问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




