pyppeteer专题

【爬虫渲染神器】selenium 和pyppeteer 的动态渲染ajax反爬虫
许多网页是动态加载的网页,其中不乏使用了ajax异步技术,那么我们有没有一种渲染工具,直接省略分析过程,模拟浏览器渲染的操作呢,获取到我们想要的内容。当然有,下面我们介绍两种渲染工具的实战使用。 目标网站: http://www.porters.vip/verify/sign/ 点击参看详情页的里面内容。 前一篇文章,我们介绍了,js逆向分析两种方法JS逆向–签名验证反爬虫】sign签名验证
【爬虫神器 pyppeteer】比 selenium 更高效的爬虫利器--pyppeteer
Puppeteer 是 Google 基于 Node.js 开发的工具,调用 Chrome 的 API,通过 JavaScript 代码来操纵 Chrome 完成一些操作,用于网络爬虫、Web 程序自动测试等。pyppeteer 使用了 Python 异步协程库 asyncio,可整合 Scrapy 进行分布式爬虫。要注意的是它执行python3.6+以后版本使用,下面我们一起来了解下如何使用。

pyppeteer爬虫保存图片,python爬虫,完美
#pip install pyppeteer,使用 Pyppeteer(异步方案)import asyncioimport osimport randomimport requestsfrom pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()awai

python爬虫,使用pyppeteer异步,爬取,获得指定标签内容
获得指定 #pip install pyppeteer,使用 Pyppeteer(异步方案)import asynciofrom pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()await page.goto('http://xxx/#/login')

神器:用 pyppeteer 转换公众号文章为 PDF
这是「进击的Coder」的第 368 篇技术分享 作者:刘志军 来源:Python 之禅 “ 阅读本文大概需要 8 分钟。 ” 之前介绍过一些将 html 转换为 PDF 文件的库,比如 wkhtmltopdf、WeasyPrint,今天再介绍另一个神器 Pyppeteer 可将 html 页面转换为 PDF。 Pyppeteer 是什么 介绍 Pyppeteer 之前,有必要先介绍一下 Pu
![解决Pyppeteer下载chromium慢或者失败的问题[INFO] Starting Chromium download.](https://img-blog.csdnimg.cn/direct/8068d2b209ea41a98c08e9a2888e0079.png)
解决Pyppeteer下载chromium慢或者失败的问题[INFO] Starting Chromium download.
文章目录 1.进入网址2.选择上面对应自己系统的文件夹进去3. 然后找到自己的python环境中的site-packages中pyppeteer中的chromium_downloader.py文件并打开 在首次使用Pyppeteer时需要下载chromium 1.进入网址 https://registry.npmmirror.com/binary.html?path=chro
pyppeteer 执行js函数调用ajax post传入参数并获取返回值
在Pyppeteer中,你可以使用page.evaluate()方法来执行JavaScript函数,并且可以传递参数给这个函数。如果你需要执行一个调用AJAX POST请求的函数并且传入参数,同时需要获取返回值,可以使用以下方法: import asynciofrom pyppeteer import launchasync def run():browser = await launch()
python+Pyppeteer+SpringBoot验证码自动识别登录(文末附源码)
效果如下: 实现流程: 一、Pyppeteer打开网址 import asynciofrom pyppeteer import launchimport pdbimport random# 启动 Pyppeteerbrowser = await launch({'headless': False})page = await browser.newPage()# 打开登录页面

超越Selenium的存在---Pyppeteer
“ 阅读本文大概需要 10 分钟。 ” 如果大家对 Python 爬虫有所了解的话,想必你应该听说过 Selenium 这个库,这实际上是一个自动化测试工具,现在已经被广泛用于网络爬虫中来应对 JavaScript 渲染的页面的抓取。 但 Selenium 用的时候有个麻烦事,就是环境的相关配置,得安装好相关浏览器,比如 Chrome、Firefox 等等,然后还要到官方网站去下载对应

pyppeteer和requests简单应用
pyppeteer和requests简单应用 本文章只是分享pyppeteer技术。有些反扒网站可以使用pyppeteer库,完整代码没有分享。 获取相关开发工具软件,可以关注公众号:爬虫探索者。 发送下面图片的关键字可以获取对应软件。sql指的是Navicat。 破解教程可以参考主页其他文章。 运行环境 pip install -i https://mirrors.aliyun.
网络爬虫之使用pyppeteer替代selenium完美绕过webdriver检测
1引言2 手动安装3 主要操作 3.1 打开浏览器3.2 调整窗口大小 3.3 设置userAgent3.4 执行js脚本3.5 模拟操作 3.6 某电商平台模拟登陆4 总结 回到顶部 1引言 曾经使用模拟浏览器操作(selenium + webdriver)来写爬虫,但是稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易

Pyppeteer中Chromium安装步骤
1、下载压缩文件 在官网下载chrome-win.zip文件 2、终端下载pyppeteer 首先在Pycharm终端运行pip install pyppeteer 3、查找文件默认路径 在运行以下代码,找到可执行文件默认路径 import pyppeteer.chromium_downloaderprint('默认版本是:{}'.format(pyppeteer.__chrom

Python|Pyppeteer实现启动Adspower并自动关闭多余的窗口页面(23)
前言 本文是该专栏的第23篇,结合优质项目案例持续分享Pyppeteer的干货知识,记得关注。 本文笔者将针对pyppeteer启动adspower浏览器的时候,出现多个浏览窗口的问题,详细介绍一个解决方法。这也是很多同学,比较关心的一个问题。正好借助此文,笔者对该问题结合实际案例代码进行详细介绍。 具体细节部分以及详细思路逻辑,跟着笔者直接往下看正文内容。(附带完整代码) 正文
【python--用pyppeteer爬取知乎中个人回答内容,出现点击个人头像不跳转的问题,如何解决】
代码如下: import asyncioimport pyppeteer as pypasync def antiAntiCrawler(page):await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0
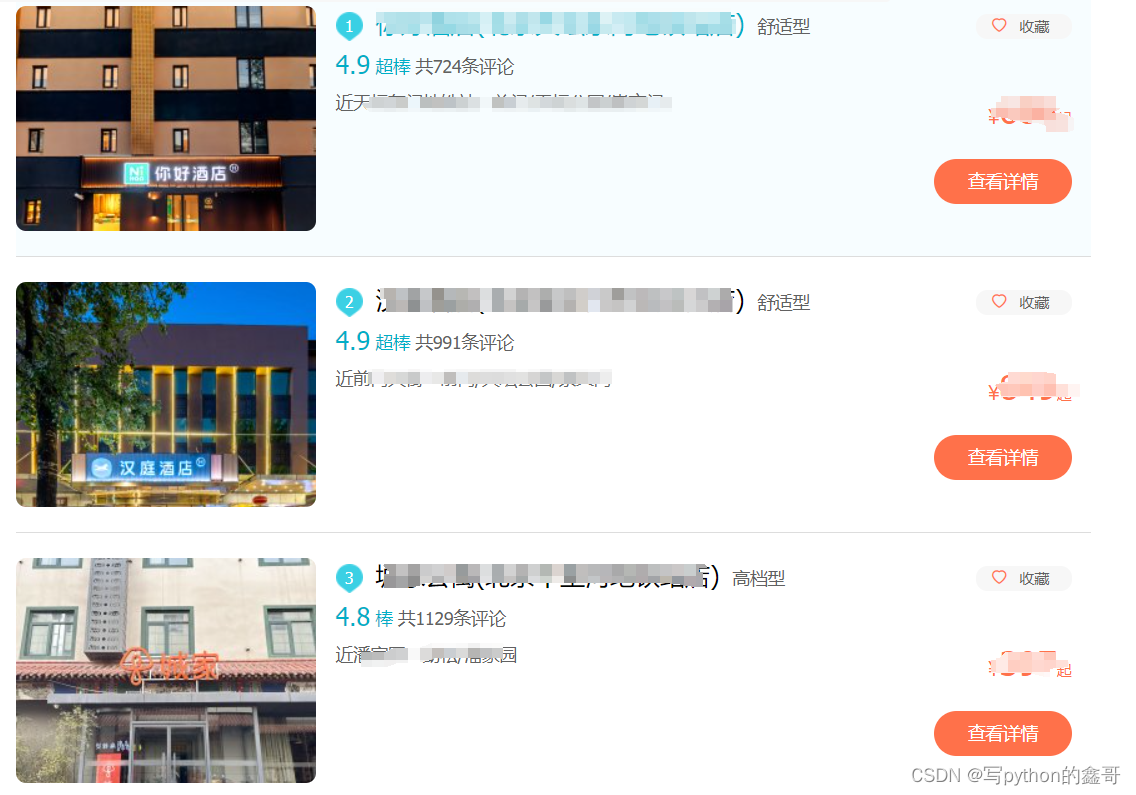
Python|Pyppeteer获取去哪儿酒店数据(20)
前言 本文是该专栏的第20篇,结合优质项目案例持续分享Pyppeteer的干货知识,记得关注。 本文以去哪儿为例,笔者将详细介绍使用pyppeteer获取去哪儿的酒店数据。如果对pyppeteer的使用以及知识点不太熟悉的同学,可往前查看本专栏前面介绍的pyppeteer知识点。 接下来,我们言归正卷。跟着笔者直接往下看,使用pyppeteer获取去哪儿酒店数据的方法。(附带完整代
pyppeteer爬虫案例
pyppeteer官方说明网站API Reference — Pyppeteer 0.0.25 documentationhttps://miyakogi.github.io/pyppeteer/reference.html import asynciofrom pyppeteer import launchfrom lxml import etreefrom txdpy import s
使用 pyppeteer 碰到的错误
pyppeteer 实在是有点坑,坑太多了,填不完。 使用 pyppeteer 碰到的错误 pyppeteer.errors.ElementHandleError: Error: failed to find element matching selector ".btn_ok" 我使用了下面的代码后出现的:为了实现检测元素是否存在,存在则程序结束,不存在则重试 btn_ok = await
Python|Pyppeteer获取去哪儿酒店数据(20)
前言 本文是该专栏的第20篇,结合优质项目案例持续分享Pyppeteer的干货知识,记得关注。 本文以去哪儿为例,笔者将详细介绍使用pyppeteer获取去哪儿的酒店数据。如果对pyppeteer的使用以及知识点不太熟悉的同学,可往前查看本专栏前面介绍的pyppeteer知识点。 接下来,我们言归正卷。跟着笔者直接往下看,使用pyppeteer获取去哪儿酒店数据的方法。(附带完整代