principal专题

Learning Feature Sparse Principal Subspace 论文阅读
1 Abstract: 这篇论文提出了新的算法来解决特征稀疏约束的主成分分析问题(FSPCA),该问题同时执行特征选择和PCA。现有的FSPCA优化方法需要对数据分布做出假设,并且缺乏全局收敛性的保证。尽管一般的FSPCA问题是NP难问题,我们展示了对于低秩协方差,FSPCA可以全局解决(算法1)。然后,我们提出了另一种策略(算法2),通过迭代构建一个精心设计的代理来解决一般协方差情况下的FSP

GEE:主成分分析(Principal components analysis,PCA)
本文将介绍主成分分析(Principal components analysis,PCA)原理和在Google Earth Engine(GEE)平台上应用 PCA 算法的代码和案例。并应用于 Landsat 数据可见光波段和生态遥感指数(RSEI) 案例中。并介绍如何针对一副影像、一个影像集合进行 PCA 分析,文中对 PCA 的计算过程进行了封装,只需要调用 imagePCA(imageCol

upc国庆集训第八天 Princess Principal(思维+栈)
问题 H: Princess Principal 时间限制: 2 Sec 内存限制: 1024 MB 提交: 183 解决: 37 [提交] [状态] [讨论版] [命题人:admin] 题目描述 阿尔比恩王国(the Albion Kingdom)潜伏着一群代号“白鸽队(Team White Pigeon)”的间谍。在没有任务的时候,她们会进行各种各样的训练,比如快速判断一个文档有没有
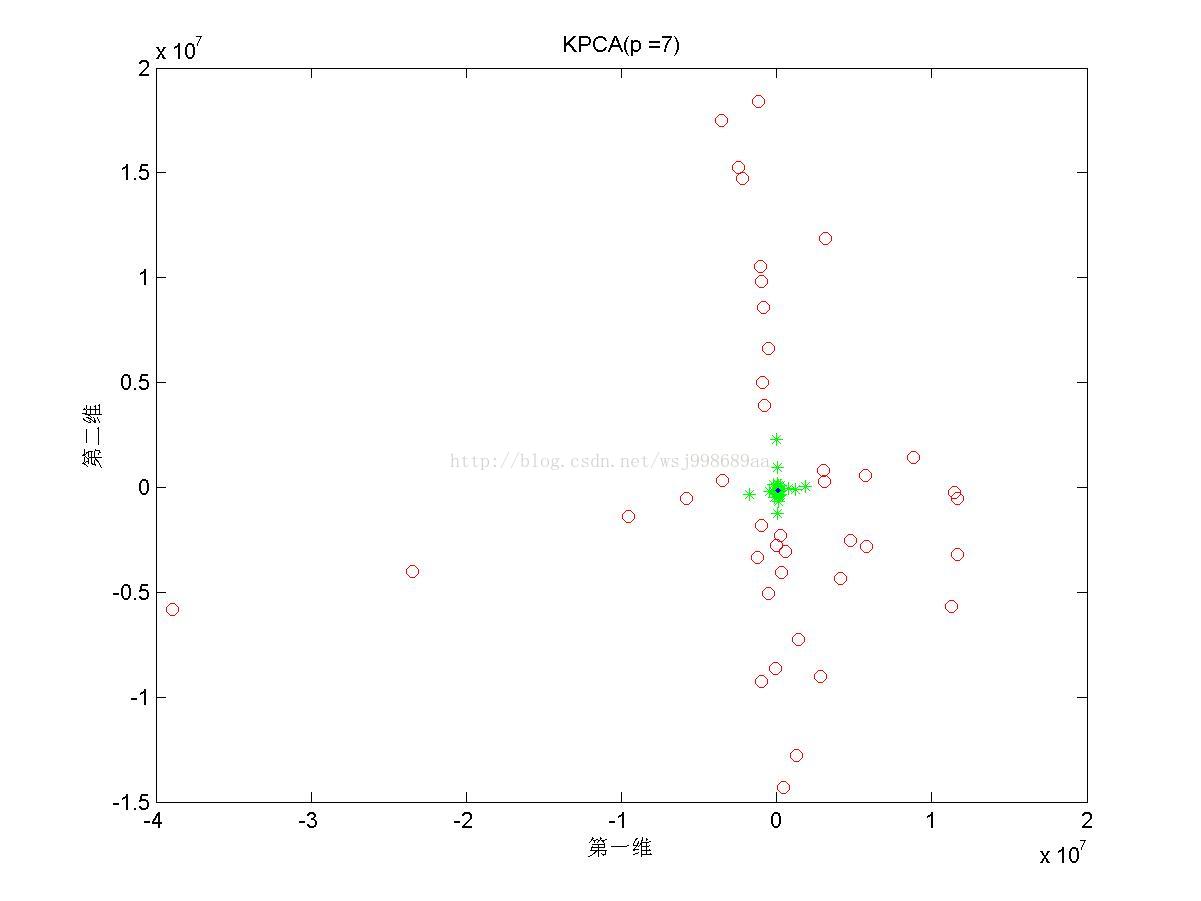
解释一下核主成分分析(Kernel Principal Component Analysis, KPCA)的公式推导过程~
转载请注明:http://blog.csdn.NET/wsj998689aa/article/details/40398777 KPCA,中文名称”核主成分分析“,是对PCA算法的非线性扩展,言外之意,PCA是线性的,其对于非线性数据往往显得无能为力,例如,不同人之间的人脸图像,肯定存在非线性关系,自己做的基于ORL数据集的实验,PCA能够达到的识别率只有88%,而同样是无监督学习的

Msg 15138 The database principal owns a schema in the database, and cannot be dropped.
删除用户报错: Msg 15138, Level16, State 1, Line 1 The database principal owns a schemain the database, and cannot be dropped. 解决办法(SSMS): 1.找到用户拥有的Schema 2.在Schema中找到db_owner将Schema Ow
无监督学习Principal Component Analysis(PCA)精简高维数据
目录 介绍 一、PCA之前 二、PCA之后 介绍 Principal Component Analysis (PCA) 是一种常用的数据降维和特征提取技术。PCA通过线性变换将高维数据映射到低维空间,从而得到数据的主要特征。PCA的目标是找到一个正交基的集合,使得将数据投影到这些基上时,能够保留尽可能多的数据信息。每个正交基称为一个主成分,它的重要性通过其对应的特征值来衡量。PCA

Principal Convex Hull Analysis (PCHA) Method
代码:GitHub - ulfaslak/py_pcha: Python package that implements the PCHA algorithm for Archetypal Analysis by Mørup et. al. 论文举例: https://arxiv.org/pdf/1901.09078.pdf (PDF) Take ACTION to characte

基于PCA-WA(Principal Component Analysis-weight average)的图像融合方法 Matlab代码及示例
摘要: 高效地将多通道的图像数据压缩(如高光谱、多光谱成像数据)至较低的通道数,对提高深度学习(DL)模型的训练速度和预测至关重要。本文主要展示利用PCA降维结合weight-average的图像融合方法。文章主要参考了题为“Noninvasive Detection of Salt Stress in Cotton Seedlings by Combining Multicol
@Wannafly summer camp Day2 H:Princess Principal (栈模拟)
阿尔比恩王国(the Albion Kingdom)潜伏着一群代号“白鸽队(Team White Pigeon)”的间谍。在没有任务的时候,她们会进行各种各样的训练,比如快速判断一个文档有没有语法错误,这有助于她们鉴别写文档的人受教育程度。 这次用于训练的是一个含有n个括号的文档。括号一共有mm种,每种括号都有左括号和右括号两种形式。我们定义用如下的方式定义一个合法的文档: 1.一个空的字符串是一
机器学习之主成分分析(Principal Component Analysis,PCA)案例解析附代码
概念 主成分分析(Principal Component Analysis,PCA)是一种常用的降维技术,用于减少数据集维度并保留数据集中的主要特征。它通过线性变换将高维数据投影到低维空间,同时尽量保留数据集中的信息。 PCA的目标是找到数据中最重要的方向,即方差最大的方向,这些方向被称为主成分。这些主成分是原始特征的线性组合。通过保留主要的主成分并舍弃次要的成分,可以实现数据的降维。 PC

coursera Machine Learning 第八周 测验quiz2答案解析 Principal Component Analysis
1.选择AB 解析:u(1)的选择应该是使投影距离最短,而向量的方向正负皆可,故选择AB 2.选择B 解析:k的选择与m无关,肘方法适用于聚类类数的选择。k的选择应该是在满足差异性的情况下,取最小的值。故选择B。 3.选择B 解析:对照公式选择即可。这里是直接的(式子)<0.05,后面使用svd中得到的Sii是(1-另一个式子)<0.05。 4.选择AD 解析:A
机器学习:Principal components analysis (主分量分析)
Principal components analysis 这一讲,我们简单介绍Principal Components Analysis(PCA),这个方法可以用来确定特征空间的子空间,用一种更加紧凑的方式(更少的维数)来表示原来的特征空间。假设我们有一组训练集 {x(i);i=1,...m} \{x^{(i)}; i=1,...m \},含有m个训练样本,每一个训练样本 x(i)∈Rn x^
![Ambaris Hive创建自定义函数报错 Principal [name=hdfs, type=USER] does not have following privileges for operat](https://img-blog.csdnimg.cn/64887ea21a3d4692bc48e2de0e3d3316.png)
Ambaris Hive创建自定义函数报错 Principal [name=hdfs, type=USER] does not have following privileges for operat
文章目录 环境报错内容原因解决方法 环境 Ambari 2.7.5 集群未启动Kerberos 报错内容 > hive0: jdbc:hive2://bigdata-24-194:2181,bigdata-2> create function OneID as 'com.udf.OneIDUDF' using jar 'hdfs:/hive/udf/oneid-udf-1.

Streaming Principal Component Analysis in Noisy Settings
论文背景: 面对来袭的数据,连续样本不一定是不相关的,甚至不是同分布的。当前,大部分在线PCA都只关注准确性,而忽视时效性!噪声?数据缺失,观测有偏,重大异常? 论文内容: Section 2 Online Settings Online PCA, 就是在观察到 x 1 , x 2 , x 3 , … , x t − 1 x1, x2, x3, \dots, x_{t-1} x1,x2,