phantomjs专题

linux:The driver is not executable: /phantomjs/bin/phantomjs
在linux使用selenium抓取的时候出现错误 java.lang.IllegalStateException: The driver is not executable: /phantomjs/bin/phantomjsat com.google.common.base.Preconditions.checkState(Preconditions.java:518)at org.openq
phantomjs-2.1.1-windows
需要用一下PhantomJS https://phantomjs.org/download.html 直奔官网而去 不过这也太慢了吧 我是shoufa好公民 没有可以出去的软件 下载了很久很久。。。 由于太恶心度盘,我上传了个蓝盘,就不传csdn下载了 有需要的下吧,这速度嗖嗖的 下载:https://www.lanzous.com/ia60sfe 密码:be0e 找到了

Selenium+PhantomJS使用时报错原因及解决方案
问题 今天在使用selenium+PhantomJS动态抓取网页时,出现如下报错信息: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox insteadwarnings.warn('Selenium support
java使用phantomJs抓取动态页面
随时随地技术实战干货,充分利用闲暇时间,请关注源代码社区公众号和技术交流群。 from:http://blog.csdn.net/kaka0930/article/details/68941932 1. phantomjs的镜像网站:http://npm.taobao.org/dist/phantomjs/ 2. phantomjs内置webkit内核,也就是chrome的内核。可以无界

基于phantomJS实现web性能监控
随时随地技术实战干货,充分利用闲暇时间,请关注源代码社区公众号和技术交流群。 from:http://www.webryan.net/2013/02/web-page-test-based-on-phontomjs/ 1、web性能监控背景描述 上期分享的《Web性能监控自动化探索之路–初识WebPageTest》从依赖webpagetest的角度给出了做性能日常检查的方案,但由于依赖
Python爬虫 PhantomJS运行提示WebDriverException: 'bin' executable may have wrong permissions.
PhantomJS声明已经在2016年不再官方更新,不过2017年又释放出了beta版本在镜像站点: https://npm.taobao.org/dist/phantomjs/ 可以从上述站点下载,比从phantomjs.org上下载快。 Selenium也需要安装。下面代码段是一个例子,可以直接敲进去用的。 webdriver.PhantomJS 这一句要注意 在windows里面,
phantomjs 抓取网页
phantomjs:我的理解就是它是一个无显示的浏览器,也就是说除了不能显示页面内容以外,浏览器能干的活儿它基本上都能干。so,最近由于实验需要,要从某电商爬一点图片,但是它又是AJAX生成的,单纯的爬取HTML的方法是行不通的,o(╯□╰)o,于是在经过一些求助后,;了解到了PHANTOMJS,鉴于网上没找到太多实例,只好自己总结下以备不时之需。另外直接查看官网上的说明文档会有很大收获滴~顺便

java 调用 phantomjs
日前有采集需求,当我把所有的对应页面的链接都拿到手,准备开始根据链接去采集(写爬虫爬取)对应的终端页的时候,发觉用程序获取到的数据根本没有对应的内容,可是我的浏览器看到的内容明明是有的,于是浏览器查看源代码也发觉没有,此时想起该网页应该是ajax加载的。不知道ajax的小朋友可以去学下web开发啦。 采集ajax生成的内容手段不外乎两种。一种是通过http观察加载页面时候的请求,然后我们模仿该请

解析Perl爬虫代码:使用WWW__Mechanize__PhantomJS库爬取stackoverflow.com的详细步骤
在这篇文章中,我们将探讨如何使用Perl语言和WWW::Mechanize::PhantomJS库来爬取网站数据。我们的目标是爬取stackoverflow.com的内容,同时使用爬虫代理来和多线程技术以提高爬取效率,并将数据存储到本地。 Perl爬虫代码解析 首先,我们需要安装WWW::Mechanize::PhantomJS库,这可以通过CPAN进行安装。这个库允许我们模拟一个浏览器会
将phantomjs制成docker镜像
几个前的一篇文章中介绍了phantomjs+echarts生成图表图片的一种方式,但其部署复杂,制作为docker镜像运行就方便多了。文章参见:https://blog.csdn.net/u011943534/article/details/121524397 1、准备echarts 将上次文章中提到过下载的EchartsConvert 解压,并复制到一个安装docker的服务器。 下载地址:
phantomjs/casperjs动态传入参数
我们常用phantomjs/casperjs脚本来做一些事情。有时候希望从外部动态传入参数来进行操作。如何实现呢?介绍三种办法: 1.通过phantomjs.args获取参数 即在脚本中直接调用phantom.args,即可获取到命令行参数数组。注意,它默认会带三个内部参数在数组前面。第一个casperjs的安装路径,第二个casperjs的参数--cli,第三个是当前脚本名称(含路径)。之后
Python3 爬虫 Requests Urllib Chrome PhantomJS 代理总结
学爬虫我们已经了解了多种请求库,如 Requests、Urllib、Selenium 等。我们接下来首先贴近实战,了解一下代理怎么使用。 下面我们来梳理一下这些库的代理的设置方法。 1. 获取代理 在做测试之前,我们需要先获取一个可用代理,搜索引擎搜索“代理”关键字,就可以看到有许多代理服务网站,在网站上会有很多免费代理,比如西刺:http://www.xicidaili.com/,这里
Phantomjs+Java+springboot实现后端截图
一、phantomjs介绍 (1)一个基于webkit内核的无界面浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。 (2)提供javascript API接口,即通过编写js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了以前c/c++才能比较好的基于webkit开发优质采集器的限制。 (
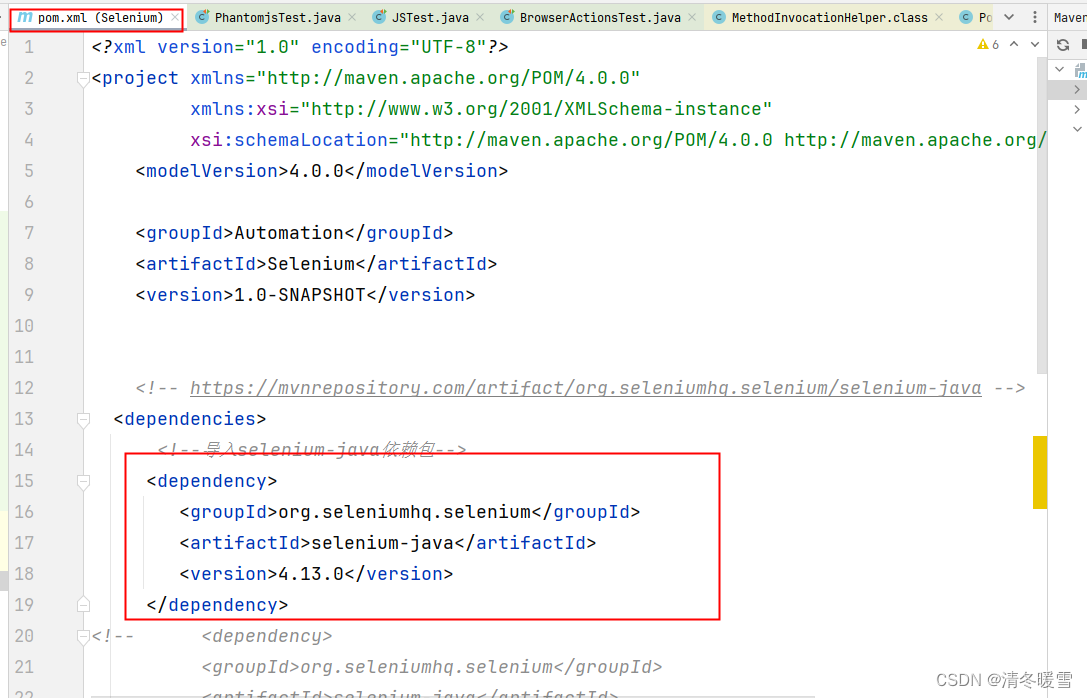
无界面自动化测试(IDEA+Java+Selenium+testng)(PhantomJS)
自动化测试(IDEA+Java+Selenium+testng)(PhantomJS)_phantomjs怎么写js脚本idea-CSDN博客 上述连接是参考:现在如果按照如上链接进行操作大概率会失败,下面会针对如上链接的部分步骤做出修改 1、在pom.xml文件中需要使用低版本selenium-java依赖包,目前我使用的是4.13.0版本的所以在运行时铁定失败,目前除了降低selenium
![[译]使用PhantomJS进行网页剪报](https://images0.cnblogs.com/blog/116671/201304/20020246-3f4fa40f883341768dacf1104d6a2e2d.png)
[译]使用PhantomJS进行网页剪报
原文:http://ariya.ofilabs.com/2013/04/web-page-clipping-with-phantomjs.html PhantomJS的一个主要用途就是用来抓取网页并将它渲染成图片.在渲染图片时有很多选项可供调整,其中最常用的一个就是缩放选项(调整zoomFactor属性的值),它经常会被用在制作缩略图的场景下.另外一个不怎么被人熟知的选项就是"按指定矩形区域渲
Python爬虫---selenium基本使用(支持无界面浏览器PhantomJS和Chrome handless)
为什么使用selenium? 使用urllib.request.urlopen()模拟浏览器有时候获取不到数据,所以使用selenium (1) selenium是一个用于web应用程序测试的工具 (2) selenium 测试直接运行在浏览器中,就像真正的用户在操作一样 (3) 支持通过各种driver (FirfoxDriver,IternetExplorerDriver,OperaDri
phantomjs使用(创作助手)
PhantomJS是一个基于WebKit的无头浏览器(headless browser),它可以用来模拟用户在网页上的行为,比如点击、输入、滚动、截图等等。PhantomJS可以通过命令行来使用,也可以通过JavaScript脚本来操作。 以下是一些基本的PhantomJS使用示例: 下载PhantomJS并安装。 在命令行中运行phantomjs命令,可以进入PhantomJS的交互模式
![[Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据](https://images2015.cnblogs.com/blog/194720/201706/194720-20170622093605320-1051095409.png)
[Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一、介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息。 给定关键字:数字;融合;电视 抓取信息内如下: 1、资讯标题 2、资讯链接 3、资讯时间 4、资讯来源 二、网站
为什么casperjs比phantomjs好
本文翻译自这篇文章。 页面浏览 用CasperJS浏览页面比用PhantomJS更加方便和直观。 例如,先后打开webpage A,然后webpage B 用CasperJS的话,你可以这样写: casper.start('URL of website A', function(){console.log('Started');});casper.thenOpen('URL of
纯后台生成echarts图片-phantomjs-2.1.1
问题场景 后端需要定时发邮件,邮件正文带图片,图片要求每次即时生成。 开发环境 idea+Java8+springboot2 echart-convert.js phantomjs-2.1.1与字体 分析 phantomjs可以模拟浏览器执行js请求ajax等效果,俗称无头浏览器,可以用于客户端渲染。 步骤 下载上述资源,放入工程里,待调用。安装phantomjs-2.1.1及微软雅

学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面 由于业务需要,老大要我研究一下爬虫。 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周。基于以上原因固放弃python,选择java为语言来进行开发。等之后有时间再尝试python来实现一个。 本次爬虫选用了webMagic+selenium
Python3 自动化测试网页Selenium+PhantomJS
Python3 自动化测试网页Selenium+PhantomJS 本文由 Luzhuo 编写,转发请保留该信息. 原文: https://blog.csdn.net/Rozol/article/details/79974692 以下代码以Python3.6.1为例 Less is more! #!/usr/bin/env python# coding=utf-8__
君子性非异也 善假于物也(三) selenium+phantomjs java将淘宝网页转换成图片,支持下拉刷新
1.本地安装phantomjs,并且将bin加入环境变量path中 2.新建java项目,selenium和phantomjs的maven如下,driver有很多种,比如chromedriver等等,phtomjs作为无头浏览器做动态爬虫项目挺爽的 <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifa