nutch专题

转:nutch相干框架安装使用最佳指南
转:http://user.qzone.qq.com/281032878/blog/1342675154#!app=2&via=QZ.HashRefresh&pos=1362131478Chinese installing and using instruction - The best guidance in installing and using Nutch in China 超清

执行./nutch 命令后出现的nutch脚本用法解读
Usage: nutch COMMAND where COMMAND is one of: inject inject new urls into the database :注入新的url到数据库中 hostinject creates or updates an existing host table from a text file :从一个文本文
转:cygwin简单应用及Nutch之Crawler工作流程
cygwin简单应用: cygwin home 目录: ls / -- 根目录 ls /cygdrive -- 查看本地操作系统的盘符,如c盘、d盘 pwd -- 当前位置路径 /home/zf

Nutch库入门指南:利用Java编写采集程序,快速抓取北京车展重点车型
概述 在2024年北京车展上,电动汽车成为全球关注的焦点之一。这一事件不仅吸引了全球汽车制造商的目光,也突显了中国市场在电动汽车领域的领先地位。117台全球首发车的亮相,其中包括30台跨国公司的全球首发车和41台概念车,彰显了中国市场对电动化的强烈需求。 这次车展呈现了全球电动汽车发展的最新趋势。各大品牌纷纷推出技术先进、性能卓越的电动车型,展示了电动汽车技术的不断进步,如更长的续航里程、

nutch,solr,安装配置,1KAnalyzer,
第1章引言 1.1nutch和solr Nutch 是一个开源的、Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。 Solr 拥有像 web-services API 的独立的企业级搜索服务器。用 XML 通过 HTTP 向它添加文档(称为做索引),通过 HTTP 查询返回 XML 结果。 1.2研究nutch 的原因 可能有的朋友会有疑问,我们有google,有百度,为
Aapche Nutch建立自己的搜索引擎
sudo apt install default-jdk‘ java -version openjdk version "11.0.22" 2024-01-16 vi .bashrc export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 爬梯子下载源代码 Apache Nutch™ – Downloads mkdir -p urls c

Nutch+ElasticSearch/Solr+Hadoop
方案:Nutch+ElasticSearch/Solr+Hadoop Nutch:爬取网页 ES/Solr:构建索引库,提供搜索服务,Restful API支持 Hadoop:hdfs用于存储索引文件,关于存储也可以考虑NoSql,如:cassandra,hbase

Nutch的Hadoop方式爬取效率优化
下面这些是潜在的影响爬取效率的内容(官方资料翻译): 1)DNS设置 2)你的爬虫数量,太多或太少 3)带宽限制 4)每一主机的线程数 5)要抓取的urls的分配不均匀 6) robots.txt中的高爬取延时(通常和urls的分配不均匀同时出现) 7)有很多比较慢的网页(通常和分配不均匀同时出现) 8)要下载太多的内容(PDF,大的html页面,通常和分配不均匀同时出现) 9)其它 那现
探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一)
本系列文章简介: 本系列文章将带领大家深入探索Nutch的世界,从其基本概念和架构开始,逐步深入到爬虫、索引和查询等关键环节。通过了解Nutch的工作原理,大家将能够更好地理解搜索引擎背后的原理,并有能力利用Nutch构建自己的搜索引擎。 欢迎大家订阅《Java技术栈高级攻略》专栏,一起学习,一起涨分! 目录 一、引言 1.1 Nutch的起源与发展 1.2 Nutch在
七、 基于Nutch主题搜索引擎方案设计
七、 基于Nutch主题搜索引擎方案设计 7.1主题搜索引擎 7.2 主题搜索引模块设计 7.2.1 系统组成 7.2.2 主题确立模块 。 7.2.3 优化初始种子模块 7.2.4 主题相关度分析模块 7.2.5 排序模块 7.3 Yahoo API 简介 7.4 基于Nutch主题搜索引擎方案
搜索引擎工作原理(Nutch)
二、搜索引擎工作原理 2.1 搜索引擎模块组成 一个典型的网络信息检索系统的系统架构由信息收集、信息处理和查询服务三个模块组成。 从具体运行方式上说,系统根据站点/网页的URL信息和网页之间的链接关系,利用网络蜘蛛在互联网上收集数据;收集的数据分别通过链接信息分析器和文本信息分析器处理,保存在链接数据库和文本索引数据库中,同时,网页质量评估器依据网页的链接关系和页面结构特征对页面质量进行评估
开源搜索引擎Nutch 0.9的安装使用
开源搜索引擎Nutch 0.9的安装使用 Nutch是Apache组织的一个开源项目,利用它用户可以 建立自己内部网的搜索引擎,也可以建立针对整个网络的搜索引擎。一、Linux下的安装使用 (我使用的操作系统是red hat as4) 1.安装JDK,我安装的是JDK1.5 update11,安装方法到网上搜 2.安装TOMCAT,我安装的是tomcat5.5.23,安装方法到网上
从零开始搭建nutch搜索引擎
我载nutch1.2并解压: # wget http://apache.etoak.com//nutch/apache-nutch-1.2-bin.tar.gz . # tar zxvf apache-nutch-1.2-bin.tar.gz 下载tomcat6并解压: # wget http://apache.etoak.com/tomcat/tomcat-6/v6.0.32/bin/apac
解决nutch搜不到结果
搜索中文出现乱码:修改/etc/tomcat5/server.xml。增加URIEncoding/useBodyEncodingForURI两项。 <Connector port="8080" protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"URIEncoding="UTF-8"useBodyEncodingFo

开发基于 Nutch 的集群式搜索引擎
简介 Nutch 是一个基于 Java 实现的开源搜索引擎,其内部使用了高性能全文索引引擎工具 Lucene。从 nutch0.8.0开始,Nutch 完全构建在 Hadoop 分布式计算平台之上。Hadoop 除了是一个分布式文件系统外,还实现了 Google 的 GFS 和 MapReduce 算法。因此基于 Hadoop 的 Nutch 搜索引擎可以部署在由成千上万计算机组成的大型集群
Linux下Nutch分布式配置和使用
介绍 这是本人在完全分布式环境下在 Cent-OS 中 配置 Nutch-1.1 时的总结文档,但该文档适合所有 Linux 系统和目前各版本的 nutch 。 0 集群网络环境介绍 集群中所有节点均是Cent-OS系统,防火墙均禁用,sshd服务均开启;所有节点上均有一个名为nutch的用户(非超级用户,安装前root使用useradd添加),用
nutch分布式搭建
一、下载安装文件 1、下载目前最新版本 nutch-1.0:http://lucene.apache.org/nutch 2、下载tomcat6.0:http://tomcat.apache.org 3、解压下载的两个压缩文件到 /home/java 二、配置文件 1、修改conf/hadoop-site.xml (配置文件和前面的hadoop-0.20.2不一样,这里的版

二,nutch 1.0 web应用部署
本文为solomon@javaeye原创,如有转载,注明出处(作者solomon与链接http://zolomon.javaeye.com ). 本专题使用中文分词为ikanalyzer,感谢其作者为java中文事业做出的巨大贡献. 我的个人资料http://www.google.com/profiles/solomon.royarr a)将解压出来目录中的nutch-1.0.war放

Nutch学习——读源码 Injector.java
Injector.java主要是向crawldb注入 URL,这些URL也可以选择性的带上对应当metadata。里面用到了MapReduce和插件机制 Injector.inject(...): public void inject(Path crawlDb, Path urlDir) throws IOException {SimpleDateFormat sdf = new

Nutch-2.2.1学习之七Nutch与Solr的集成
Nutch以开箱的方式支持Solr,这极大的简化了Nutch与Solr的集成。Nutch也移除了遗留的对Tomcat运行旧的Nutch web应用程序和Apache Lucene索引的依赖。Nutch1.x和2.x关于Solr的区别在于1.x版本可以选择是否使用Solr索引,这需要一步一步地进行爬取工作,而2.x则提供了更为简洁的方式——crawl脚本,直接将爬取成功的页面与Solr集成在一起。当
Nutch-2.2.1学习之五Nutch抓取数据在HBase中的存储
Nutch-2.2.1爬取的数据可以存储在HBase、Accumulo、Cassandra、MySQL、DataFileAvroStore、AvroStor中,这是与Nutch-1.x系列很大的区别,在提供多样性的同时也增加了一些复杂性,比如使用不同存储时的不同配置,对特定的存储结构客户端处理方式的不同等等。这篇文章主要介绍了Nutch-2.2.1与HBase结合使用时,Nutch爬取的数据在HB
Nutch-2.2.1学习之四Nutch与Hbase结合使用时常见问题
Nutch-2.2.1不再使用单一的存储结构,而是通过使用Apache Gora,是得Nutch-2.2.1可以将数据存储在诸如HBase、Accumulo、Cassandra、MySQL、DataFileAvroStore、AvroStor中。这一变化在提供更多选择,更多灵活性的同时,势必增加了Nutch的复杂性。相信很多人在从Nutch-1.x版本过渡到Nutch-2.x版本时都
Nutch-2.2.1学习之三Nutch配置文件
Nutch2.2.1的配置文件存放在Nutch目录下的conf文件夹下,对此文件夹下的配置文件做的修改,需要执行ant命令重新编译Nutch,由于编译所依赖的jar都已经缓存,重新编译花费的时间是很短暂的。对该文件夹下的文件所做的修改,在重新编译后也会更新到runtime目录下的deploy和local目录下的conf目录中,所以大家不要奇怪,明明只是修改了根目录下的conf中的配置文件
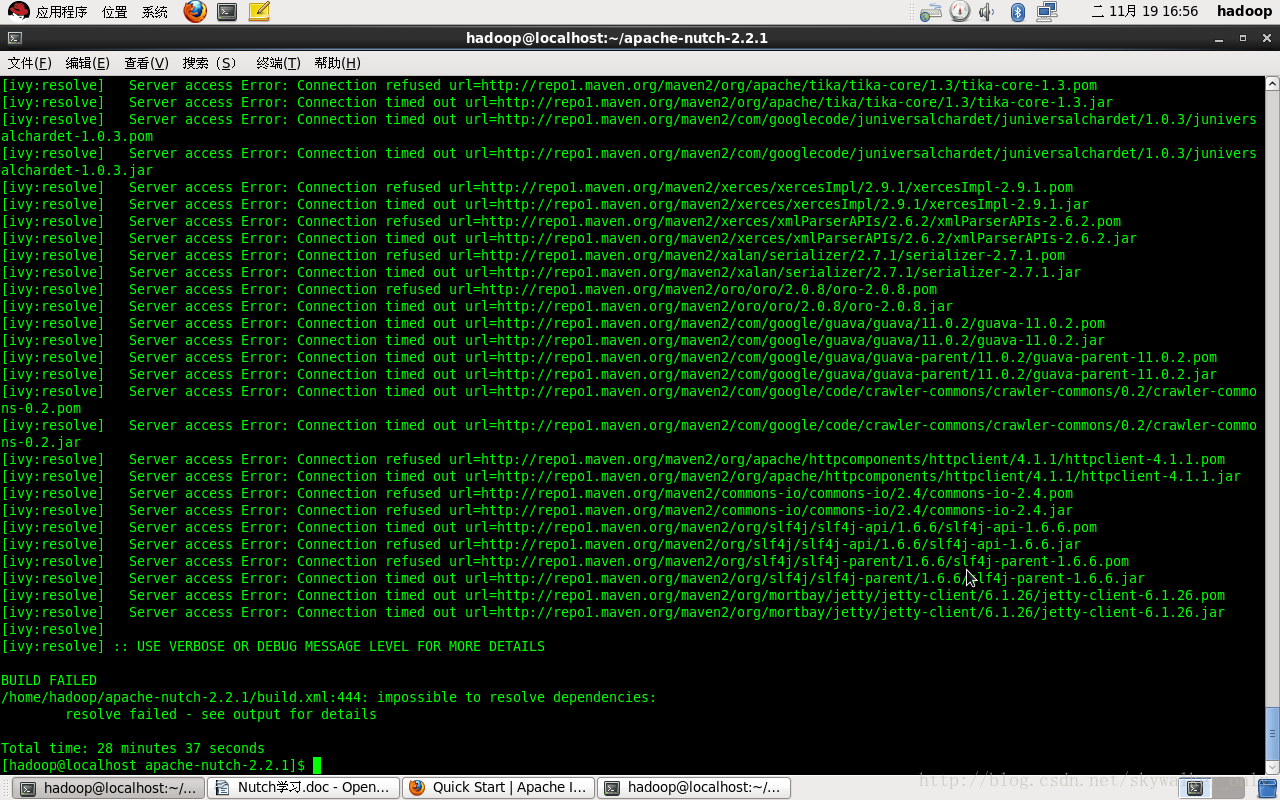
Nutch-2.2.1学习之二编译部署Nutch及常见问题
Nutch1.x从1.7版本开始不再提供完整的部署文件,只提供源代码文件及相关的build.xml文件,这就要求用户自己编译Nutch,而整个Nutch2.x版本都不提供编译完成的文件,所以想要学习Nutch2.2.1的功能,就必须自己手动编译文件。这篇文章主要介绍了如何编译Nutch2.2.1版本,同时罗列了一些编译过程中遇到的问题及解决方案。当然不可能列举所有的问题,希望大家可以补充自己遇到的
Nutch-2.2.1学习之一Nutch简介
Nutch起源于ApacheLucene项目,已经是一个高度可扩展和可伸缩的开源网络爬虫软件项目,并且实现了多元化,包括两个版本的代码库,即: 1. Nutch1.x版本:一个成熟的产品化的爬虫。1.x版本依赖于Apache Hadoop的数据结构,并使用了细粒度配置。Hadoop对于批处理提供了很强大的功能。 2. Nutch2.x的版本:一个新兴的、直接受1.x