nemotron专题
NVIDIA新模型Nemotron-4:98%的训练数据是合成生成的,你敢信?
获取本文论文原文PDF,请公众号 AI论文解读 留言:论文解读 标题:Nemotron-4 340B Technical Report 模型概述:Nemotron-4 340B系列模型的基本构成 Nemotron-4 340B系列模型包括三个主要版本:Nemotron-4-340B-Base、Nemotron-4-340B-Instruct和Nemotron
NVIDIA发布Nemotron-4 340B 用于生成高质量的合成数据
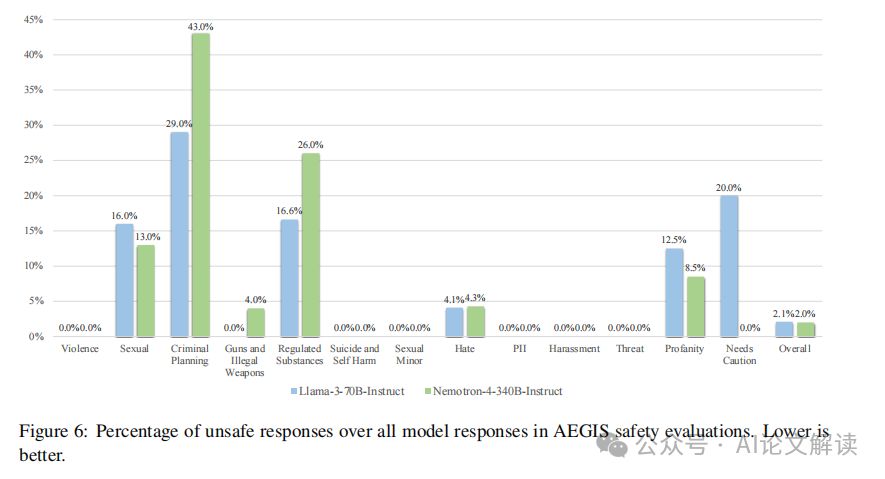
Nemotron-4 340B 是一系列为 NVIDIA NeMo 和 NVIDIA TensorRT-LLM 优化的模型,包括最先进的指令和奖励模型,以及用于生成式 AI 训练的数据集。 英伟达今日宣布推出 Nemotron-4 340B,这是一系列开放模型,开发者可以使用它们生成用于训练大型语言模型(LLM)的合成数据,以应用于医疗、金融、制造、零售及其他各行各业的商业应用。 高质量的

英伟达发布Nemotron-4 340B通用模型:专为生成合成数据设计的突破性AI
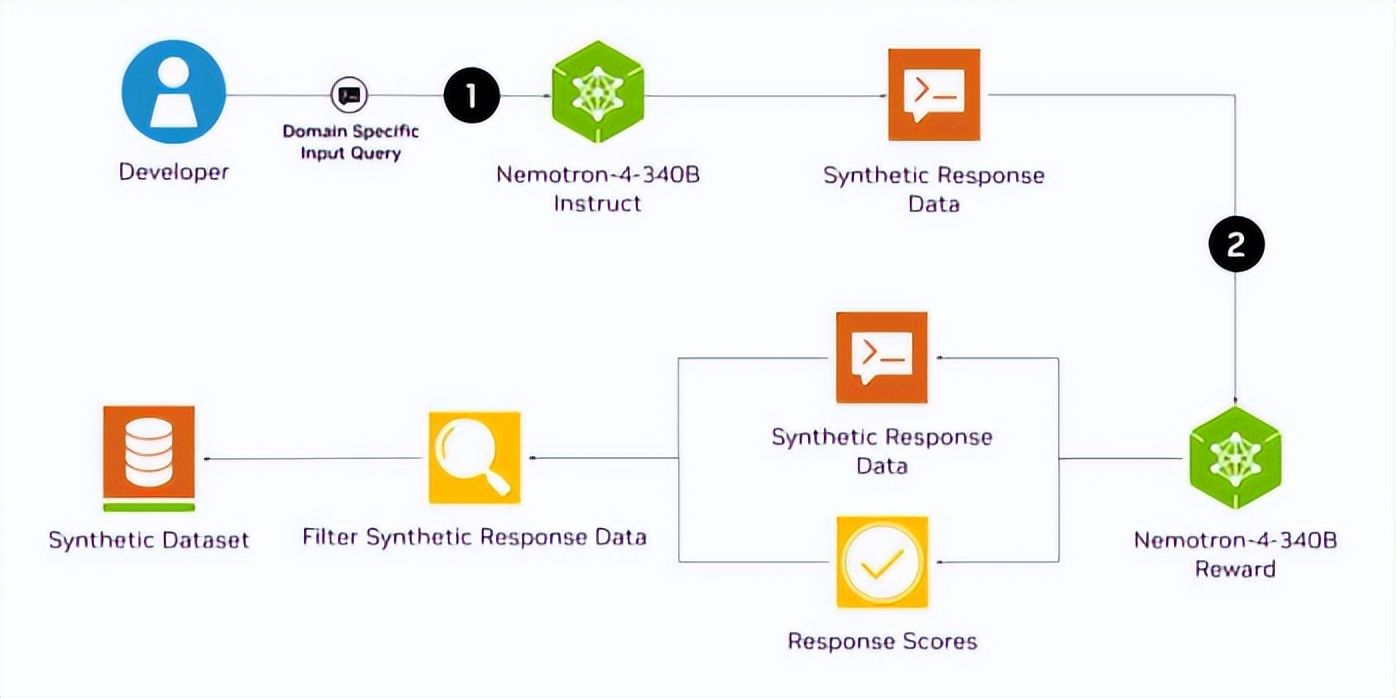
引言 2023年6月14日,英伟达发布了Nemotron-4 340B通用模型,专为生成训练大语言模型的合成数据而设计。这一模型可能彻底改变训练大模型时合成数据的生成方式,标志着AI行业的一个重要里程碑。本文将详细介绍Nemotron-4 340B的各个方面,包括其性能、设计特点、训练数据以及实际应用和潜在影响。 在这个合成数据 pipeline 中,(1)Nemotron-4 340B

英伟达开源最强通用模型Nemotron-4 340B:开启AI合成数据新纪元
【震撼发布】 英伟达最新力作——Nemotron-4 340B,一个拥有3400亿参数的超级通用模型,震撼登场!这不仅是技术的一大飞跃,更是AI领域的一次革命性突破! 【性能卓越】 Nemotron-4 340B以其卓越的性能超越了Llama-3,专为合成数据而生。它将为医疗健康、金融、制造、零售等行业带来前所未有的商业应用潜力。 【免费开源】 英伟达的这一壮举,为开发者提供了

Nemotron-4 15B Technical Report
#Nemotron-4 15B #Large Language Model #Multilingual #Transformer #Machine Learning 摘要: Nemotron-4 15B 是一个训练在8万亿文本标记上的150亿参数的大型多语言语言模型。在英语、多语言和编码任务上表现出色,超越了所有类似规模的开放模型,并在剩余领域与领先开放模型具有竞争力。特别是,Nemotron-