naf专题

NAF和联想公布移动应用大赛的获奖者名单
非营利性组织和全球科技领导者创造STEM学习和就业机会 纽约和北卡罗来纳州罗利--(美国商业资讯)--全球领先的科技公司联想与专注于高中教育的非营利性组织NAF,今日公布了来自不同NAF学院的、角逐第四届年度“联想学者网络全美移动应用开发大赛”(Lenovo Scholar Network National Mobile App Development Competition)的获

NAF(Non-adjacent form) w-NAF及其在curve25519-dalek中scalar的实现
1. 引言 The non-adjacent form (NAF) of a number is a unique signed-digit representation. Like the name suggests, non-zero values cannot be adjacent. For example: ( 0 1 1 1 ) 2 = 4 + 2 + 1 = 7 (0\ 1\ 1

深度强化学习(文献篇)—— 从 DQN、DDPG、NAF 到 A3C
自己第一篇 paper 就是用 MDP 解决资源优化问题,想来那时写个东西真是艰难啊。 彼时倒没想到这个数学工具,如今会这么火,还衍生了新的领域——强化学习。当然现在研究的内容已有了很大拓展。 这段时间会做个深度强化学习的专题,包括基础理论、最新文献和实践三大部分。 DRL 的核心思想是,用神经网络来表征值函数或者参数化 policy,从而使用梯度优化方法来优化损失。 本篇介绍近年来 D

Lee Hung-yi强化学习 | (5) Q-learning用于连续动作 (NAF算法)
Lee Hung-yi强化学习专栏系列博客主要转载自CSDN博主 qqqeeevvv,原专栏地址 课程视频 课件地址 普通的Q-learning比policy gradient比较容易实现,但是在处理连续动作(比如方向盘要转动多少度)的时候就会显得比较吃力。 因为如果action是离散的几个动作,那就可以把这几个动作都代到Q-function去算Q-value。但是如果action是连续的,此
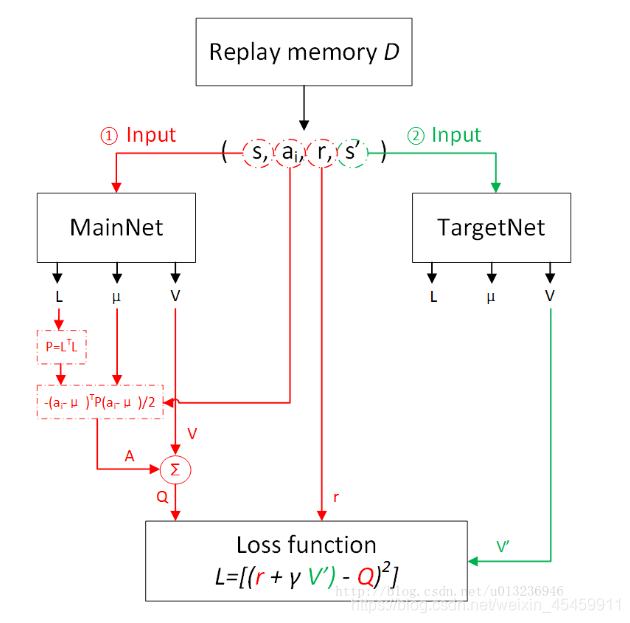
强化学习入门(六):Q-learning系列算法3:连续动作(NAF)
本文是在https://blog.csdn.net/acl_lihan/article/details/104076938的基础上进行了部分改动,加上了一点个人理解,原博客写的非常好,不妨一同查阅。 普通的Q-learning比policy gradient比较容易实现,但是在处理连续动作(比如方向盘要转动多少度)的时候就会显得比较吃力。 因为如果action是离散的几个动作,那就可以把这几个

深度强化学习5:Q-learning用于连续动作 (NAF算法)
【李宏毅深度强化学习笔记】5、Q-learning用于连续动作 (NAF算法) qqqeeevvv 2020-01-26 00:53:56 2806 收藏 4 分类专栏: 强化学习 # 理论知识 </div></div><div class="up-time"><span>最后发布:2020-01-26 00:53:56</span

深度强化学习中的NAF算法-连续控制(对DQN的改进)
DQN算法以及之前的种种改进都是面向离散的action的,DQN算法没有办法面向连续的action,因为Q值更新的时候要用到求最大的action。 本来DQN主要是输出Q值的,aciton是通过argmax顺便实现的,但是现在NAF需要用神经网络输出了,那么就是同时输出Q 和 a。 基本的idea就是引入了Advantage函数A(s,a),也就是每一个动作在特定状态下的优劣。