nadam专题
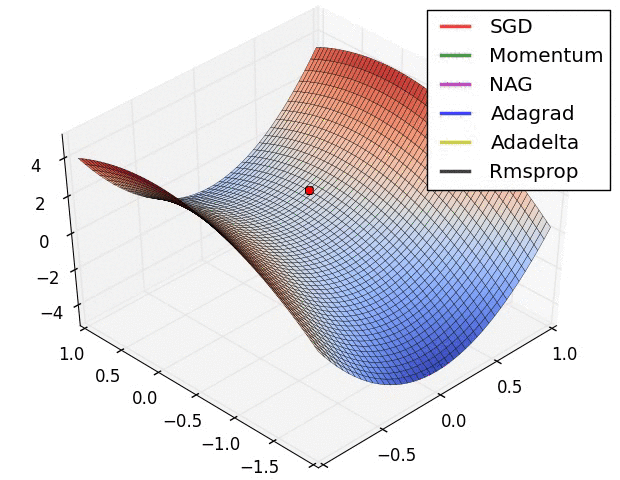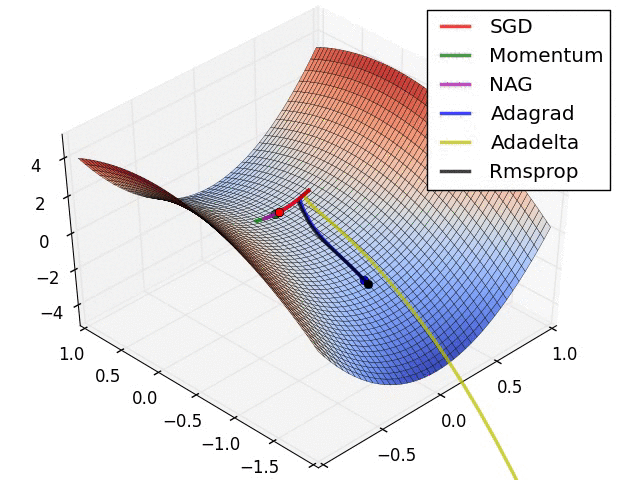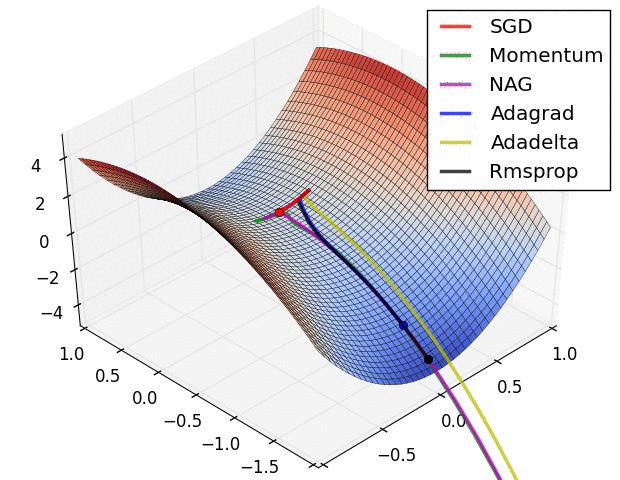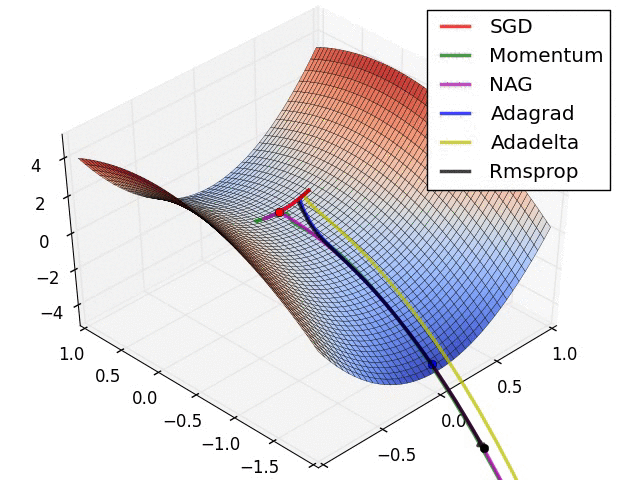
自适应学习速率SGD优化方法比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) 前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。 SGD 此处的SGD指mini-batch gradient descent,关于batch gradient desc

![[work] 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)](https://pic1.zhimg.com/80/4a3b4a39ab8e5c556359147b882b4788_hd.jpg)
[work] 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。 SGD 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent