mrr专题

一键部署Phi 3.5 mini+vision!多模态阅读基准数据集MRR-Benchmark上线,含550个问答对
小模型又又又卷起来了!微软开源三连发!一口气发布了 Phi 3.5 针对不同任务的 3 个模型,并在多个基准上超越了其他同类模型。 其中 Phi-3.5-mini-instruct 专为内存或算力受限的设备推出,小参数也能展现出强大的推理能力,代码生成、多语言理解等任务信手拈来。而 Phi-3.5-vision-instruct 则是多模态领域的翘楚,能同时处理文本和视觉信息,图像理解、视频摘要

推荐系统-排序算法:常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等
参考资料: 推荐算法常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等 搜索评价指标——NDCG
MRR vs MAP vs NDCG:具有排序意义的度量指标的可视化解释及使用场景分析
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Moussa Taifi, Ph.D 编译:ronghuaiyang 导读 3种指标,各有优缺点,各有适用场景,分析给你看。 机器学习度量之旅 在不适当的度量指标上报告小的改进是一个众所周知的机器学习陷阱。理解机器学习(ML)指标的优缺点有助于为ML从业者建立个人信誉。这样做是为了避免过早宣布胜利的陷阱。理解用于机器学习(
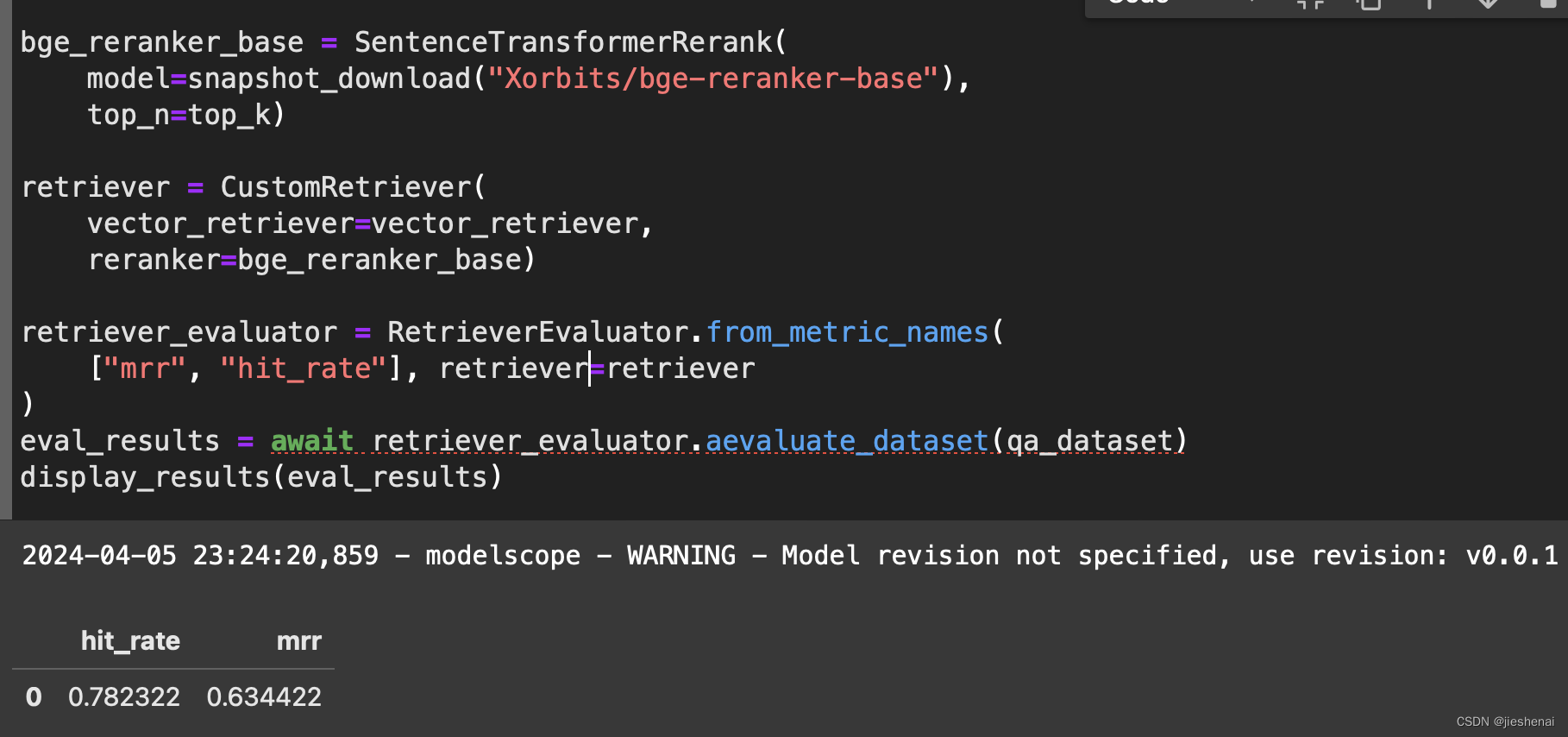
使用向量检索和rerank 在RAG数据集上实验评估hit_rate和mrr
文章目录 背景简介代码实现自定义检索器向量检索实验向量检索和rerank 实验 代码开源 背景 在前面部分 大模型生成RAG评估数据集并计算hit_rate 和 mrr 介绍了使用大模型生成RAG评估数据集与评估; 在 上文 使用到了BM25 关键词检索器。接下来,想利用向量检索器测试一下在RAG评估数据集上的 hit_rate 和 mrr; 简介 使用 向量检索 和 r
深度学习常用评价指标(Accuracy、Recall、Precision、HR、F1 score、MAP、MRR、NDCG)——推荐系统
混淆矩阵 混淆矩阵P(Positives)N(Negatives)T(Ture)TP:正样本,预测结果为正TN:负样本,预测结果为正F(False)FP:正样本,预测结果为负FN:负样本,预测结果为负 总结 AccuracyRecallPrecisionHits RatioF1 scoreMean Average PrecisionMean Reciprocal RankNormalized
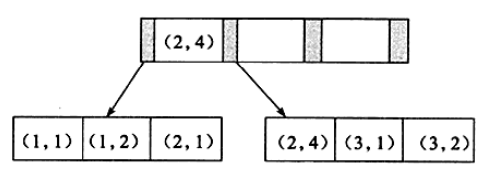
简析联合索引、覆盖索引、MRR优化、ICP优化
简析联合索引、覆盖索引、MRR优化、ICP优化 联合索引覆盖索引优化器选择不使用索引的情况Multi-Range Read(MRR)优化Index Condition Pushdown(ICP)优化 联合索引 与建立单个索引的方式相同,不过联合索引有多个索引列,且不同的列有严格的先后顺序。 如图所示,为一个由两个整形列组成的联合索引的索引结构。同单个键值的索引一样,联合索