mobilevit专题

【机器学习】基于Transformer架构的移动设备图像分类模型MobileViT
1.引言 1.1. MobileViT是什么? MobileViT是一种基于Transformer的轻量级视觉模型,专为移动端设备上的图像分类任务而设计。 背景与目的: MobileViT由Google在2021年提出,旨在解决移动设备上的实时图像分类需求。与传统的卷积神经网络(CNN)相比,MobileViT在保持高性能的同时,显著降低了计算复杂度和内存需求,从而更适应移动设备的计算能力

MobileVIT原理详解篇
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、收藏⭐、留言📩 MobileVIT原理详解篇 写在前面 Hello,大家好,我是小苏🧒🏽🧒🏽🧒🏽 在之前,我已经为大家介绍过各种基础的深度神经网络,像AlexNet、VGG、ResNet等等,也为大家介绍

【DeepLearning-9】YOLOv5模型网络结构中加入MobileViT模块
一、神经网络的前中后期 在神经网络中,特别是在深度卷积神经网络(CNN)中,“网络早期(低层)”、“网络中期(中层)”和“网络后期(高层)”通常指的是网络结构中不同层级的部分,每个部分在特征提取和信息处理方面有其特定的作用和特性。 1. 网络早期(低层) 在网络的早期阶段插入 MobileViTBv3 可能会对原始图像进行较深层次的处理,有助于捕捉更丰富的空间特征。但同时,Transform
【DeepLearning-8】MobileViT模块配置
完整代码: import torchimport torch.nn as nnfrom einops import rearrangedef conv_1x1_bn(inp, oup):return nn.Sequential(nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),nn.SiLU())def conv_

【文献解读】“MOBILEViT:轻量级、通用目的、移动友好的视觉变换器”。
今天阅读这篇2022年ICLR会议上发表的论文,主要是为了学习MobileViT模型,用于YOLO模型主干改造。 一、文献概述 作者:Sachin Mehta 和 Mohammad Rastegari。地点:作者所属机构是 Apple。内容简述: 提出了一种名为MobileViT的视觉变换器,它是为移动设备设计的轻量级、通用目的的卷积神经网络(CNN)。MobileViT旨在结合CNN

Pytorch之MobileViT图像分类
文章目录 前言一、Transformer存在的问题二、MobileViT1.MobileViT网络结构🍓 Vision Transformer结构🍉MobileViT结构 2.MV2(MobileNet v2 block)3.MobileViT block🥇Local representations🥈Transformers as Convolutions (global repre
MobileVIT学习笔记
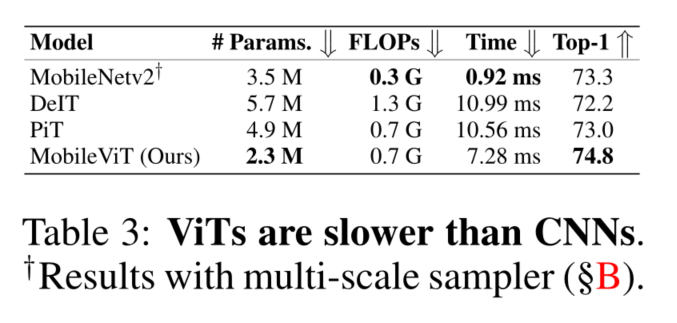
MobileVIT学习笔记 MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER ABSTRACT 轻型卷积神经网络(CNN)实际上是用于移动视觉任务的。他们的空间归纳偏差允许他们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表示,采用了基于自注意力

论文阅读:MobileViT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER
发表时间:2022.03.04 论文地址:https://arxiv.org/abs/2110.02178 项目地址:https://github.com/apple/ml-cvnets 轻量级卷积神经网络(CNNs)实际上是移动视觉任务的首选。他们的空间归纳偏差允许他们在不同的视觉任务中以更少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表示,我们采用了基于self-atten