milvus专题

SpringBoot集成Milvus实现数据增删改查功能
《SpringBoot集成Milvus实现数据增删改查功能》milvus支持的语言比较多,支持python,Java,Go,node等开发语言,本文主要介绍如何使用Java语言,采用springboo... 目录1、Milvus基本概念2、添加maven依赖3、配置yml文件4、创建MilvusClient

从Milvus迁移DashVector
本文档演示如何从Milvus将Collection数据全量导出,并适配迁移至DashVector。方案的主要流程包括: 首先,升级Milvus版本,目前Milvus只有在最新版本(v.2.3.x)中支持全量导出其次,将Milvus Collection的Schema信息和数据信息导出到具体的文件中最后,以导出的文件作为输入来构建DashVector Collection并数据导入 下面,将详细

向量数据库之Milvus
Milvus 是一个开源的向量数据库,专门设计用于高效存储、管理和搜索大规模向量数据。它常用于机器学习、人工智能、推荐系统、图像搜索、自然语言处理等领域,特别适合处理需要高效相似性搜索的应用场景。Milvus 由 Zilliz 开发,具有高性能、可扩展性和易用性。 基本概念与架构 1. 基本概念 向量数据(Vector Data):Milvus 主要处理高维向量数据,常见于图像、文本、视频等
linux安装milvus数据库lite版本
https://milvus.io/docs/milvus_lite.md 参考上述教程,直接安装该包即可。标准版和分布式版要运行docker。 pip install -U pymilvus 下面是官方的demo,一起看看 from pymilvus import MilvusClient # 导入库,客户端import numpy as np # # 创建客户端,并连接到一个名

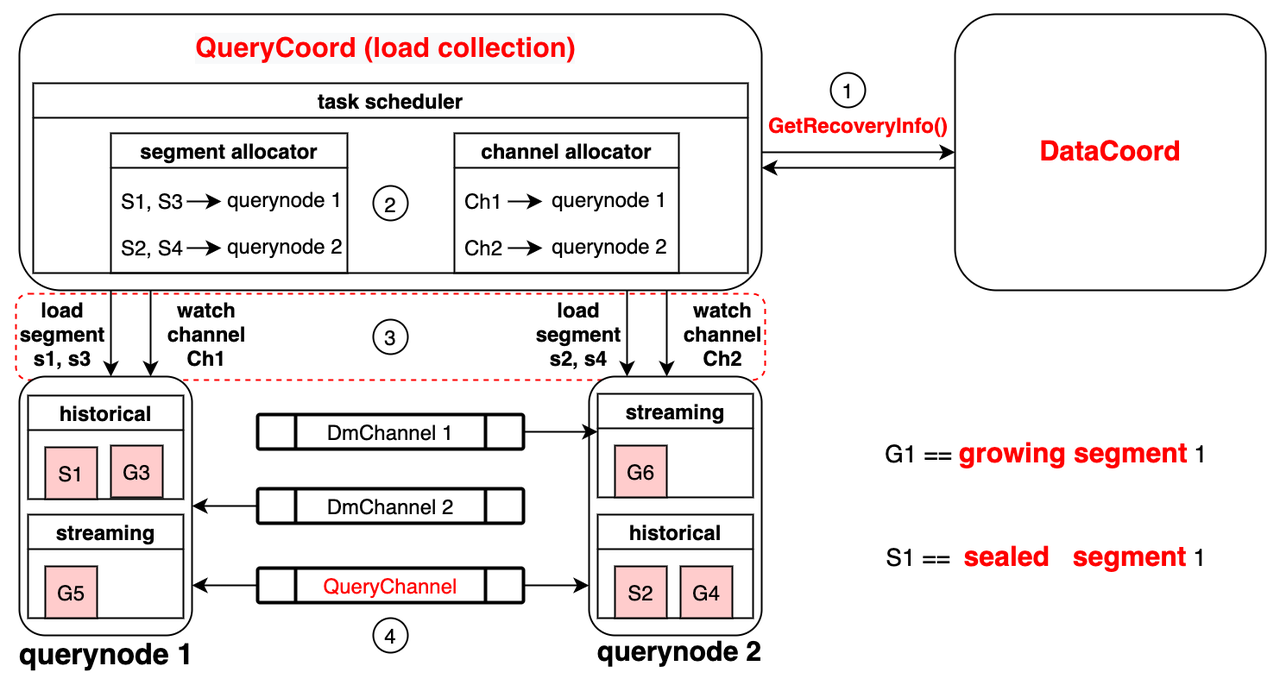
Milvus实践(5) ---- 从attu2.4x窥探Milvus数据结构变化及原理
目录 背景 启动 attu 首页 数据库 系统信息 剖析数据库存储 整体 集合描述 collection & shard segment & partition index 图解 设计动机 可视化对应部分 collection partition segment 查询数据段状态 持久数据段状态 query部分 向量搜索 scalar data 搜索 m
Milvus向量数据库-内存中索引简介
以下内容是自己在学习Milvus向量数据库时,在Milvus官方网站文档库中对索引的学习整理和翻译,通过自己和借助翻译软件进行了理解整合翻译,有可能有一些地方理解整理的不到位,还望大家理解。 一、内存中索引 本文列出了 Milvus 支持的各种类型的内存索引、每种索引最适合的场景,以及用户可以配置以实现更好的搜索性能的参数。有关磁盘上的索引,请参阅磁盘上的索引。 索引是有效组织数据的过程,它

RAG实操教程langchain+Milvus向量数据库创建你的本地知识库 二
Miluvs 向量数据库 关于 Milvui 可以参考我的前两篇文章 • 一篇文章带你学会向量数据库Milvus(一)[1]• 一篇文章带你学会向量数据库Milvus(二)[2] 下面我们安装 pymilvus 库 pip install --upgrade --quiet pymilvus 如果你使用的不是 Miluvs 数据库,那也没关系,langchain 已经给我们分装了几十
【向量检索】之向量数据库Milvus,Faiss详解及应用案例
Reference https://www.modb.pro/db/509268 笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 (zhihu.com) 向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss - 苏洋的文章 - 知乎 常用的三种索引方式及原理-CSDN 向量搜索应用 向量检索技术,其
Milvus进行分类任务
使用Milvus进行分类任务主要涉及数据准备、集合创建、数据插入、索引构建以及分类查询等步骤。以下是一个清晰的步骤说明: 一、数据准备 数据集:首先,你需要一个待分类的数据集。这个数据集可以包含图像特征向量、文本特征向量、音频特征向量等,具体取决于你的任务需求。特征提取:根据数据集的类型,使用合适的特征提取方法将数据转换为向量表示。例如,对于图像数据,可以使用深度学习模型(如ResNet、VG
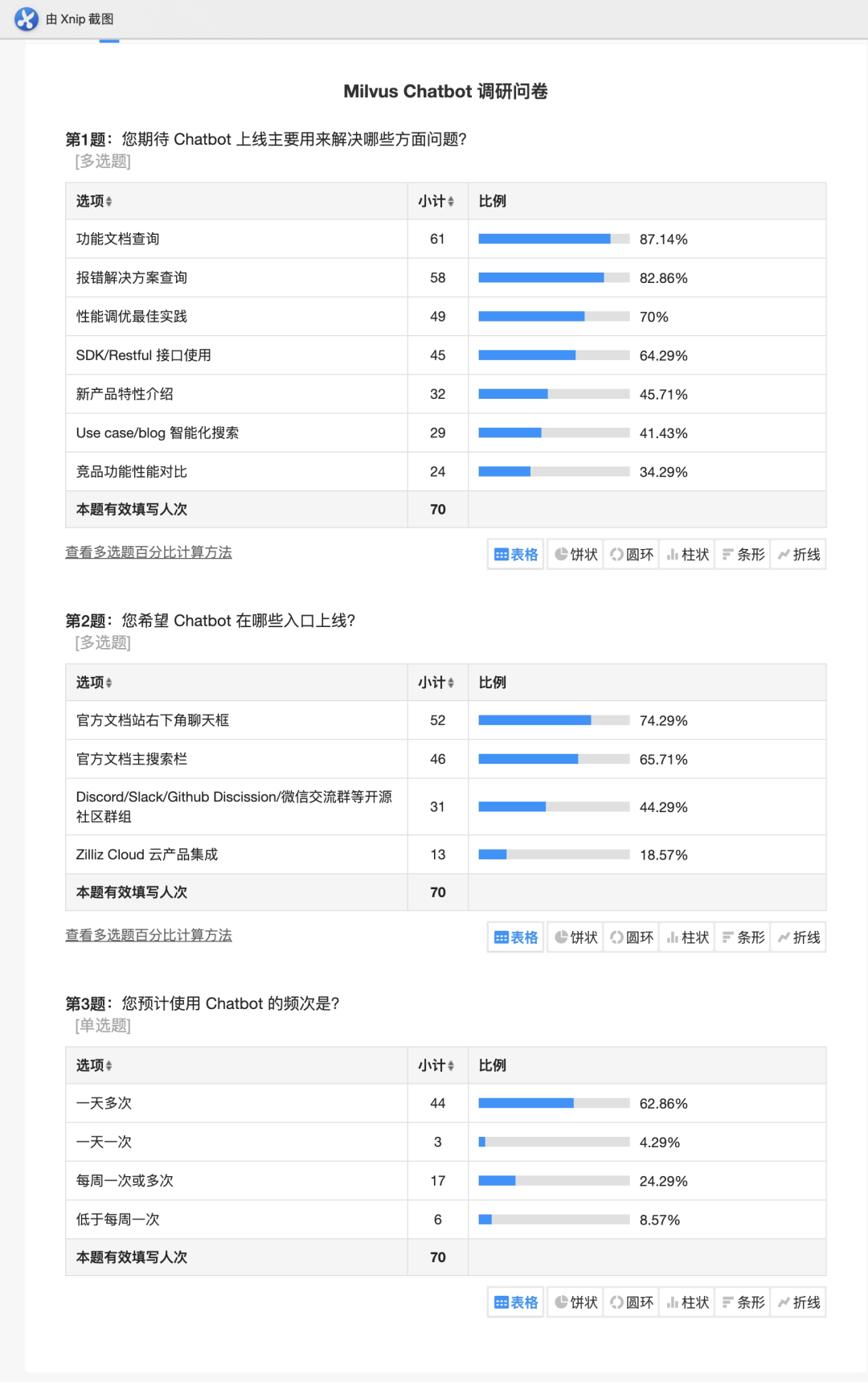
Milvus Cloud 问答机器人 上线!构建企业级的 Chatbot
01. 背景 早些时候我们在社区微信群发出了一份关于Milvus Cloud 自动问答机器人的调研问卷。 调研受到了社区同学的积极响应,很快我们就收到了很多热心用户的回复。 基于这些回复,我们整理出了 Milvus Cloud Chatbot 的形态: 以功能使用和文档查询为核心 提供聊天和搜索双形态提供 经过数月的努力,我们完成了原型验证,对接测试

Databricks超10亿美元收购Tabular;Zilliz 推出 Milvus Lite ; 腾讯云支持Redis 7.0
重要更新 1. Databricks超10亿美元收购Tabular,Databricks将增强 Delta Lake 和 Iceberg 社区合作,以实现 Lakehouse 底层格式的开放与兼容([1] [2])。 2. Zilliz 推出 Milvus Lite 轻量级向量数据库,支持本地运行;Milvus Lite 复用了 Milvus 向量索引和查询解析的核心组件,同时

轻松掌握:Milvus向量数据库部署与RAG使用技巧
Milvus简介 Milvus是一款开源的向量数据库,由 Zilliz 开发并维护,适合用于机器学习和人工智能领域。是一款专为处理向量查询而设计的数据库,Milvus 能够对万亿级向量进行索引。 Milvus官网:https://milvus.io/ Milvus中文文档:https://www.milvus-io.com/ Milvus部署 环境准备 Linux操作系统Docker 19

Milvus LIKE操作符
在Milvus中,虽然LIKE操作符被用于模糊匹配字符串,但其支持的模式匹配能力有限。根据你收到的错误信息,Milvus目前只支持两种类型的LIKE模式匹配: 前缀匹配,例如LIKE 'ab%',这意味着任何以'ab'开头的字符串都会匹配。完全匹配,例如LIKE 'ab',这意味着字符串必须完全等于'ab'。 对于中间或结尾的通配符(例如'%产品添加%'),Milvus当前版本并不支持。这是因

直播预告|手把手教你玩转 Milvus Lite !
Milvus Lite(https://milvus.io/docs/milvus_lite.md)是一个轻量级向量数据库,支持本地运行,可用于搭建 Python 应用,由 Zilliz 基于全球最受欢迎的开源向量数据库 Milvus(https://milvus.io/intro)研发。 上周,我们发布了名为《重磅推出:Milvus Lite 正式上线,几秒内即可轻松搭建 GenAI 应用》的

【简单介绍下Milvus,什么是Milvus?】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 🎯Milvus 🎯Milvus是一个开源的向量相似度搜索引擎,主要用于处理大规模向量数据。它提供了高效的相似度搜索和向量索引功能,支持低延迟的近似最近邻搜索,并且可以适用于
milvus 中的集合与 database
在Milvus中,集合(Collection)和数据库(Database)是两个不同的概念,它们之间存在一定的关系。 1. 数据库(Database) 数据库是Milvus中的最顶层的组织单位,可以理解为一个命名空间,用于管理和组织集合。在Milvus中,可以创建多个数据库,每个数据库下可以包含多个集合。 2. 集合(Collection) 集合是Milvus中的存储单位,用于存储向量数据

Milvus Cloud 非结构化数据平台
从技术面来看,向量数据库底座自然而然向外延伸的产品包含: 1)向量提取,从非结构化数据中提取向量,这是向量数据库上游的工作,十分重要; 2)模型选择,选择正确的模型,能够更精准、更高质量地提取向量; 3)映射管理,即管理数据的本体和数据的语义层之间的映射,在非结构化数据量庞大的情况下,有效维护前述映射会变得很复杂; 4)映射关系的增删改查,数据不是一成不变的,如何动态维
Milvus基本介绍与相关概念
一、介绍 Milvus是一种开源的特征向量相似度搜索引擎,主要用于处理大规模的向量数据。它是由ZILLIZ团队推出的一款高效、可扩展的相似度搜索引擎。 Milvus的基本概念包括: 向量:Milvus主要用于处理向量数据,向量是由一组数值组成的数据结构,可以表示特征或者数据实例。距离度量:Milvus使用欧氏距离或余弦相似度等度量方式来度量向量之间的相似度。索引:为了加快向量搜索的速度,Mi
探索Milvus:高效的向量数据库引擎
Milvus 是一款备受关注的开源向量数据库引擎,它的出现为处理大规模向量数据提供了全新的解决方案。本文将介绍 Milvus 的基本概念、特点以及它在各种应用场景中的应用。 什么是 Milvus? Milvus 是一个高性能的向量数据库引擎,专注于存储和检索大规模的向量数据。它支持多种相似度搜索算法,并且在处理高维向量时表现出色。Milvus 的设计目标是为了满足人工智能领域中向量相似度搜索的
Milvus 美基本概念
Milvus是一种基于向量相似度搜索的开源向量数据库,被广泛应用于诸如图像检索、推荐系统、自然语言处理等领域。本文将从Milvus的基本概念出发,详细介绍其在向量相似度搜索方面的特点和应用。 一、Milvus的基本概念 向量:在Milvus中,向量是指一个具有n个数值的有序集合,可以表示数据的特征或属性。例如,对于一张图片,可以使用一个向量来表示其特征。向量搜索:Milvus的核心功能是向量搜
【简单介绍下Milvus】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 🎯Milvus 🎯Milvus是一个开源的向量相似度搜索引擎,主要用于处理大规模向量数据。它提供了高效的相似度搜索和向量索引功能,支持低延迟的近似最近邻搜索,并且可以适用
Milvus 基本概念
Milvus 是一个开源的向量数据库,专门用于高效地存储、管理和检索大规模向量数据。它基于 Apache 许可证 2.0 版本发布,由 Zilliz 公司开源并维护。 Milvus 的设计理念是为了解决向量数据存储和检索的挑战。在许多应用中,向量数据是一种重要的数据类型,例如图像、音频和自然语言处理等。传统的数据库系统并不擅长处理向量数据,因为它们通常侧重于适应关系型数据和非结构化数据。而 Mi
Springboot整合向量数据库Milvus
Springboot整合向量数据库Milvus 导入依赖 <!--milvus 向量数据库 client sdk --><dependency><groupId>io.milvus</groupId><artifactId>milvus-sdk-java</artifactId

掌握未来搜索的钥匙:深入解析 Milvus 向量搜索引擎的终极指南!
在大数据时代,向量搜索技术愈发重要。作为一个开源的向量相似性搜索引擎,Milvus 提供了基于向量的相似性搜索功能,广泛应用于机器学习、人工智能等领域。本文将深入介绍 Milvus 的基本概念,包括其介绍、主要作用、使用方法及注意事项。 Milvus 简介 Milvus(源自 Latin "millefolium",意为千叶草)是一个高性能的向量相似性搜索库,支持大量向量数据的实时插
Milvus基本概念及其应用场景
Milvus是一款云原生向量数据库,具备高可用、高性能、易拓展的特点,主要用于海量向量数据的实时召回。以下是关于Milvus的基本概念解释: 向量数据库:Milvus是一个向量数据库,用于存储、索引和管理通过深度神经网络和机器学习模型产生的海量向量数据。这里的“向量”又称为embedding vector,是指由embedding技术从离散变量(如文本、图像等各种非结构化数据)转变而来的连续向量