本文主要是介绍Milvus 一,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、引言
Milvus是一款云原生向量数据库,具备高可用、高性能、易拓展的特点,主要用于海量向量数据的实时召回。它基于FAISS、Annoy、HNSW等向量搜索库构建,专注于解决稠密向量相似度检索的问题。
二、主要特点
- 高性能:Milvus在万亿矢量数据集上实现惊人的搜索速度,平均延迟可达毫秒级。
- 易用性:Milvus拥有专为数据科学工作流程设计的丰富API,支持数据分区分片、数据持久化、增量数据摄取等功能。
- 可靠性:内置复制和故障转移/故障恢复功能,确保数据和应用程序始终保持业务连续性。
- 可扩展性:高度可扩展和弹性,支持水平扩展,通过增加节点数量可以轻松扩展系统容量。
- 混合搜索:支持向量、布尔、字符串、整数、浮点数等数据类型,标量和向量可以混合过滤。
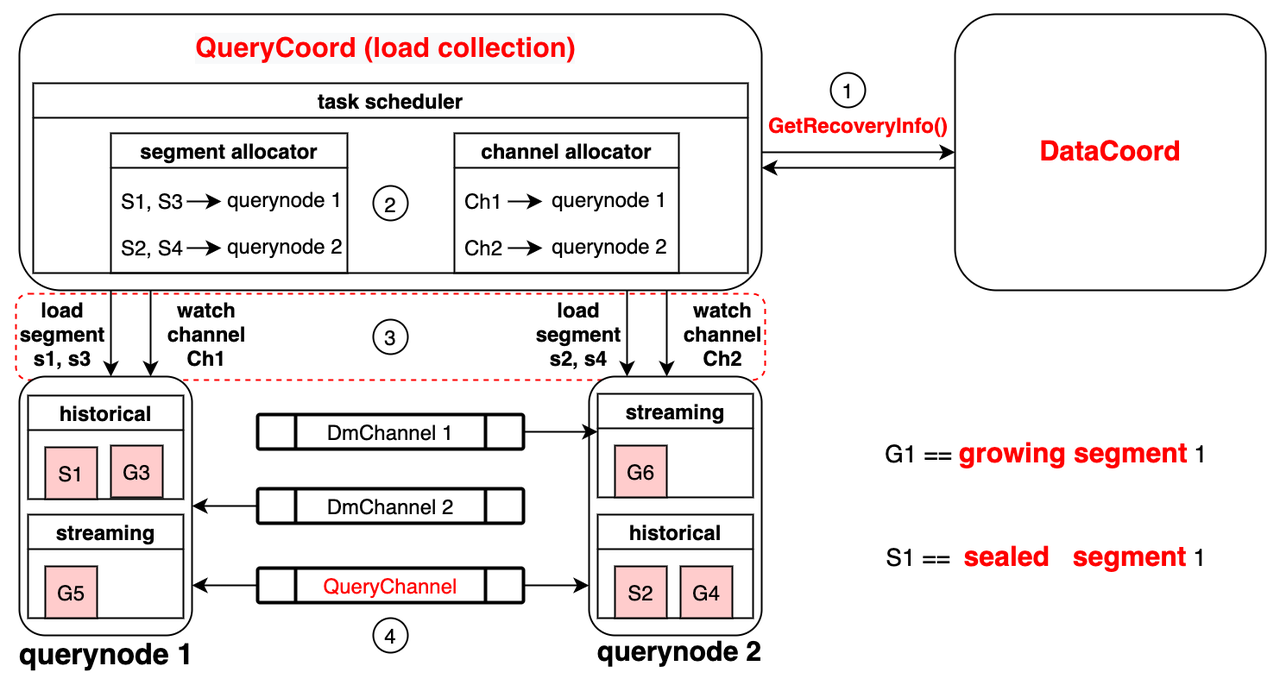
三、系统架构
Milvus采用共享存储架构,实现存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus整体分为四个层次:
- 接入层(Access Layer):负责用户请求的接收和响应。
- 协调服务(Coordinator Service):处理数据定义语言(DDL)和数据控制语言(DCL)请求,管理时间戳服务(TSO)等。
- 执行节点(Worker Node):负责对增量数据和历史数据执行向量和标量数据的混合搜索。
- 存储层(Storage):负责数据的持久化存储,确保数据的可靠性和可用性。
四、应用场景
- 智能客服:利用Milvus的向量相似度搜索功能,快速匹配用户问题并给出准确的答案。
- 语义分析:对文本数据进行语义匹配和聚类分析,帮助企业进行智能决策。
- 图像识别:通过Milvus的分布式向量检索框架,对图像数据进行高效检索和匹配。
五、分布式技术介绍
Milvus分布式向量检索基于分布式系统架构,具有以下特点:
- 高效性:利用分布式计算和大规模索引技术,快速处理海量数据,提供高效的向量检索服务。
- 可扩展性:支持水平扩展,通过增加节点数量可以轻松扩展系统容量。
- 准确性:采用先进的向量相似度计算方法,确保在海量数据中准确找到相似度最高的结果。
六、优缺点
优点:
- 高性能:利用分布式计算的优势,实现高效的向量运算和查询。
- 易用性:具有简单的API接口和易于使用的管理工具。
缺点:
间
七、总结
Milvus作为一款云原生向量数据库,凭借其高性能、可扩展性和易用性等特点,在海量向量数据的实时召回场景中展现出强大的能力。无论是智能客服、语义分析还是图像识别等领域,Milvus都能提供有效的解决方案。
这篇关于Milvus 一的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!