mhsa专题

BERT or Transformer中,MHSA中为什么要分多个Head?
之前面试被问过的一道题,这里整理一下~ 结论:模型的表达学习能力增强了 输入到MHSA中的数据的shape应该为B × L × Embedding,B是Batch,L是序列长度 而在MHSA中,数据的shape会被拆分为多个Head,所以shape会进一步变为: B × L × Head × Little_Embedding 以Transformer为例,原始论文中Embedding为
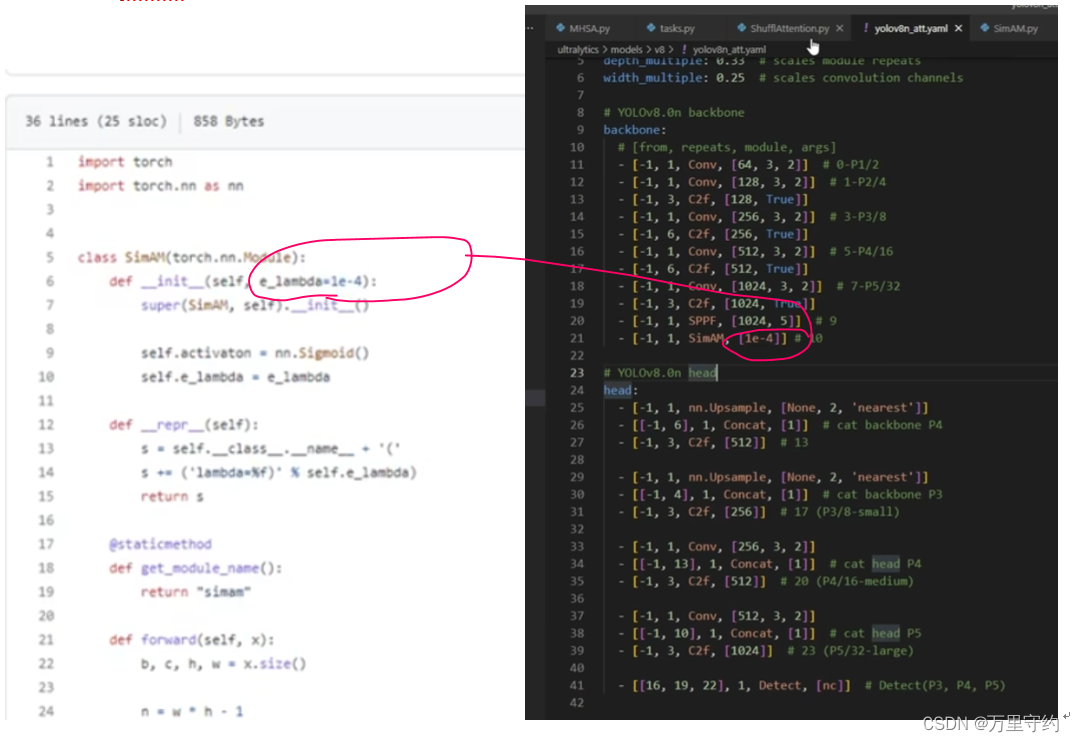
YOLOv8添加注意力机制方法【MHSA、ShuffleAttention、SiAM】
YOLOv8添加注意力机制方法 文章目录 注意力机制示例1:MHSA注意力机制示例2:ShuffleAttention注意力机制示例3:SiAM 注意力机制示例1:MHSA 1、 注意力机制文件放在nn文件夹下 2、 task.py文件导入注意力机制文件 3、 task.py中parse_model函数添加elif语句: 注意是in 4、 改模型配置文件 原模型(左图)和

即插即用篇 | YOLOv8 引入 MHSA 注意力机制 | 《Bottleneck Transformers for Visual Recognition》
论文名称:《Bottleneck Transformers for Visual Recognition》 论文地址:https://arxiv.org/pdf/2101.11605.pdf 文章目录 1 原理2 源代码3 添加方式4 模型 yaml 文件template-backbone.yamltemplate-small.yamltemplate-large.yamltem

YOLOv7独家改进:Multi-Dconv Head Transposed Attention注意力,效果优于MHSA| CVPR2022
💡💡💡本文独家改进:Multi-Dconv Head Transposed Attention注意力,可以高效的进行高分辨率图像处理,从而提升检测精度 MDTA | 亲测在多个数据集能够实现大幅涨点 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.cn/tYI0c ✨✨✨前沿最新计算机顶会复现 🚀🚀🚀YOLOv7自研创新结合,轻松搞定科研