mergetree专题

ClickHouse实战处理(一):MergeTree表引擎
MergeTree作为家族系列最基础的表引擎,主要有以下特点: 存储的数据按照主键排序:创建稀疏索引加快数据查询速度。支持数据分区,可以通过PARTITION BY语句指定分区字段。支持数据副本。支持数据采样。 一、MergeTree分类和建表参数 MergeTree系列表引擎包含:MergeTree、ReplacingMergeTree、ReplicatedMergeTree(复制表)、S

Clickhouse MergeTree异常数据处理
作者:俊达 说明 clickhouse mergetree的数据文件如果遇到数据损坏,可能会导致clickhouse无法启动。 本文章说明如何处理这类问题。 测试 我们先人为模拟破坏mergetree数据文件: detach table: ck01 :) detach table metrics;DETACH TABLE metricsQuery id: bb7f334b-5203-

Clickhouse MergeTree 原理(一)
作者:俊达 MergeTree是Clickhouse里最核心的存储引擎。Clickhouse里有一系列以MergeTree为基础的引擎(见下图),理解了基础MergeTree,就能理解整个系列的MergeTree引擎的核心原理。 本文对MergeTree的基本原理进行介绍。 1 MergeTree引擎表创建 1、基本语法: CREATE TABLE [IF NOT EXISTS] [db
ClickHouse--06--其他扩展MergeTree系列表引擎
其他扩展MergeTree系列 MergeTree 系列表引擎 --种类 MergeTree 系 列 表 引 擎 包 含 : MergeTreeReplacingMergeTreeSummingMergeTree(汇总求和功能)AggregatingMergeTree(聚合功能)CollapsingMergeTree(折叠删除功能)VersionedCollapsingMergeTre

ClickHouse--05--MergeTree 表引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 MergeTree 系列表引擎前言MergeTree 系列表引擎 --功能MergeTree 系列表引擎 --种类 1.MergeTree1.1MergeTree 建表语句:1.2 MergeTree 引擎表目录解析查询过程 
【ClickHouse为什么这么快?】MergeTree 表存储引擎图文实例详解
前言 ClickHouse 是俄罗斯最大的搜索引擎Yandex在2016年开源的数据库管理系统(DBMS),主要用于联机分析处理(OLAP)。其采用了面向列的存储方式,性能远超传统面向行的DBMS,近几年受到广泛关注。 本文综合介绍(东拼西凑)了 ClickHouse MergeTree系列表引擎的相关知识,并通过示例分析MergeTree存储引擎的数据存储结构。 MergeTr
聊聊ClickHouse MergeTree引擎的固定/自适应索引粒度
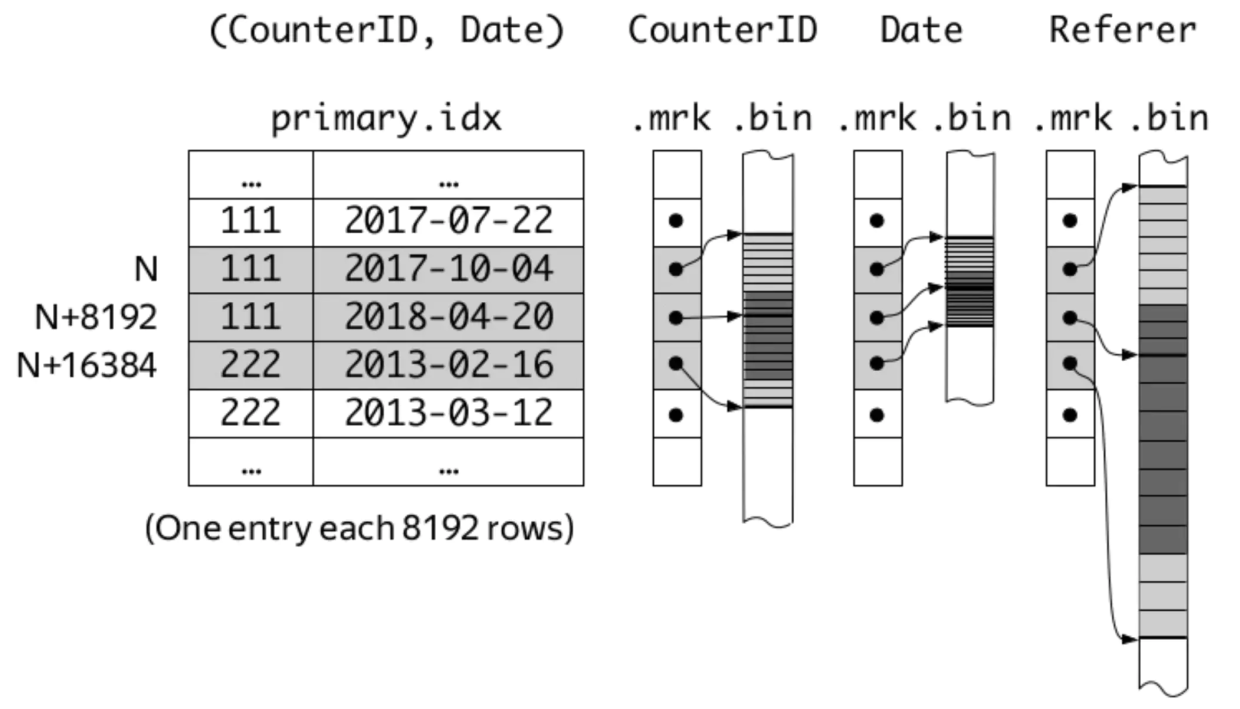
前言 我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity = 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二: 每隔index_granularity行对主键组的数据进行采样,形成稀疏索引,并存储在primary.idx文件中; 每隔i
Clickhouse_6_原理解析 - MergeTree
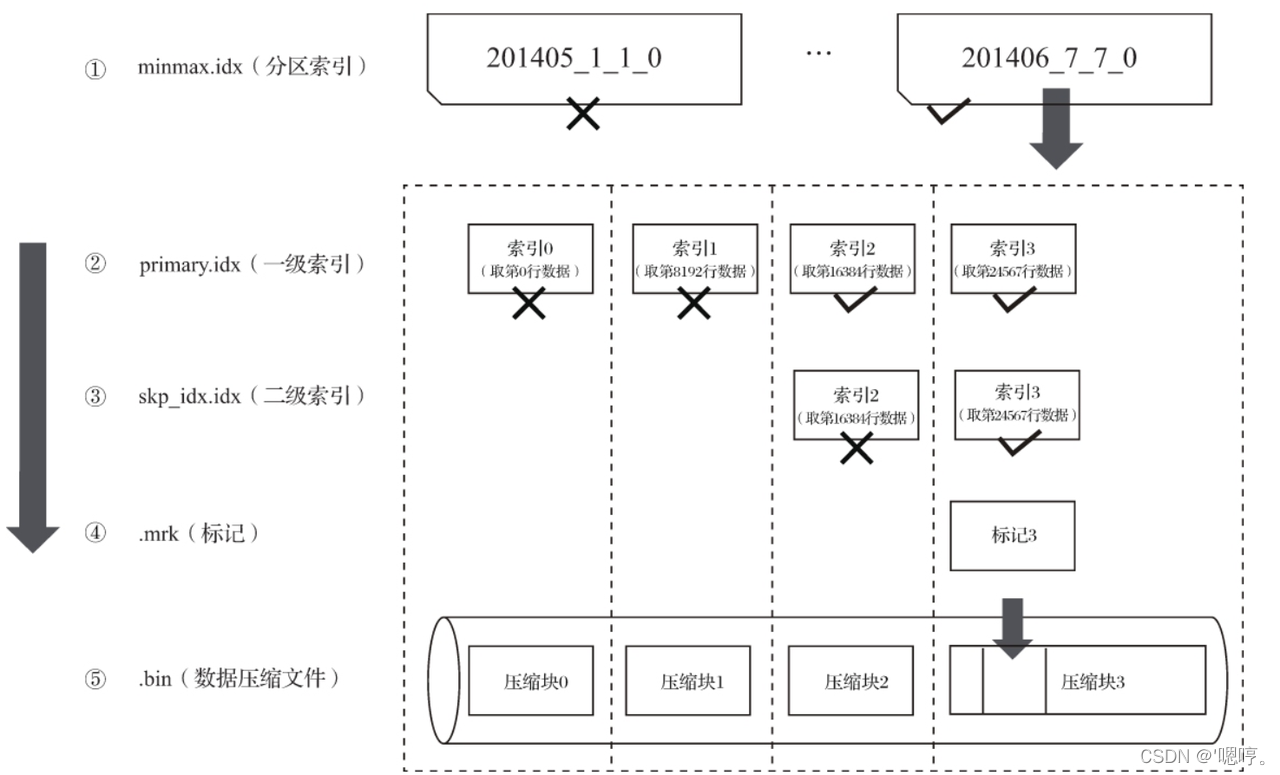
生生不息,“折腾”不止;Java晋升指北,让天下没有难学的技术;视频教程资源共享,学习不难,坚持不难,坚持学习很难; >>>> 表引擎决定了一张数据表最终的性格,比如,数据表拥有何种特性、数据以何种形式被存储以及如何被加载; ClickHouse拥有非常庞大的表引擎体系,其中 MergeTree 表引擎及其家族系列最为强>大,在生产环境下,大部分情况,都会使用该系列表引擎 支持主键