m3e专题

LLM大语言模型调用本地知识库+faiss+m3e-base或是bge-m3 超级简单教程本地存储
LLM大语言模型调用本地知识库+faiss超级简单教程本地存储: 1、新建数据集./data/dz.json: [{"id": "0","text": "你的名字","answer": "张三"}, {"id": "1","text": "你是哪个公司开发的","answer": "xxxxxxxxx公司"},.......更多知识库] 2、下载模型如: moka-ai/m3e-ba
部署接入 M3E和chatglm2-m3e文本向量模型
前言 FastGPT 默认使用了 openai 的 embedding 向量模型,如果你想私有部署的话,可以使用 M3E 向量模型进行替换。M3E 向量模型属于小模型,资源使用不高,CPU 也可以运行。下面教程是基于 “睡大觉” 同学提供的一个的镜像。 部署镜像 m3e-large-api 镜像名: stawky/m3e-large-api:latest 国内镜像: registry.cn

一文通透Text Embedding模型:从text2vec、openai-ada-002到m3e、bge
前言 如果说半年之前写博客,更多是出于个人兴趣 + 读者需要,那自我司于23年Q3组建LLM项目团队之后,写博客就成了:个人兴趣 + 读者需要 + 项目需要,如此兼备三者,实在是写博客之幸运矣 我和我司更非常高兴通过博客、课程、内训、项目,与大家共同探讨如何把先进的大模型技术更好、更快的落地到各个行业的业务场景中,赋能千千万万公司的实际业务 而本文一开始是属于:因我司第三项目组「知识库问答项
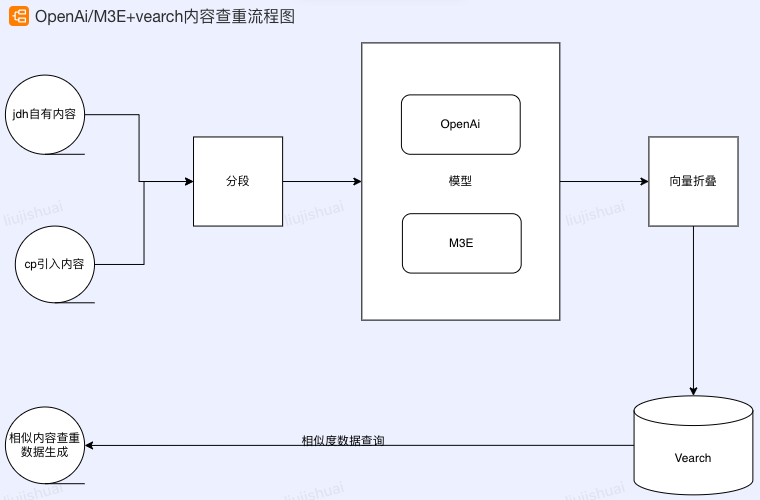
M3E/OpenAi+vearch内容查重实践 | 京东云技术团队
一、实践背景介绍 1、业务背景 京东健康内容中台H2有一个目标就是需要替换两家CP内容(总体内容体量百万级),我们现在的逻辑是想按照PV热度优先高热去新生产和替换。替换后可以极大的节省cp内容引入的成本。 第一步:这么多内容,我们的生产逻辑需要按照学科和索引归类和分配,进而批量生产,靠人工一篇篇补索引,效率会很低。希望借助算法的能力,如果现在还不是非常准确,也可以算法+人工修正, 第二步: