lzo专题

hadoop平台gz、lzo压缩对比
压缩比: rcfile: 1.04 rcfile+snappy: 0.27 rcfile+lzo: 0.25 sequencefile: 0.83 sequencefile+snappy:0.84 sequencefile+lzo: 0.79 单列读取速度: select count(distinct product_no) rc

lzo压缩之配置文件与程序对应关系
lzo压缩之配置文件与程序对应关系 1.core-site.xml中的: <property> <name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compr
pyspark ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library
使用pyspark出现问题: 14/10/24 14:51:40 ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path cp /usr/lib/hadoo
DoNotRetryIOException: Compression algorithm 'lzo' previously failed test
Hbase 建表报错: Exception in thread "main" org.apache.hadoop.hbase.DoNotRetryIOException: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'lzo' previously failed test. Set hbase.tabl

lzo格式作为输入时调整map个数
普通文本文件作为mapreduce的输入时调整map个数需调整 mapred.min.split.size和 mapred.max.split.size mapred.min.split.size是每个map的大小的最小值,而map的大小不能超过 mapred.max.split.size且不超过blocksize,因此map的大小是 Math.max(minSize, Math.
Hive set hive.lzo.paralle.read.index.thread = 1000;
set hive.lzo.paralle.read.index.thread = 1000; 应该是读lzo文件的时候起多个进程去读数据,如果来源表是lzo而且小文件比较多,加这个可以加快速度。 查看默认值: set hive.lzo.paralle.read.index.thread ; -- hive.lzo.paralle.read.index.thread is undefined
Hive之配置和使用LZO压缩
前言 OS:CentOS 7 Hive:2.3.0 Hadoop:2.7.7 MySQL Server:5.7.10 Hive官方手册:LanguageManual LZO 在配置Hive使用lzo压缩功能之前,需要保证Hadoop集群中lzo依赖库的正确安装,以及hadoop-lzo依赖的正确配置,可以参考:Hadoop配置lzo压缩 温馨提示:Hive自定义组件打包时,不要同时
emr+hadoop2.4+spark1.2 class not found com.hadoop.compression.lzo.LzoCodec
aws 云上的 spark standalone 模式下,hadoop集群的core-site.xml有: <property><name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value></property> spark on yarn会默认使用集群
spark取得lzo压缩文件报错 java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec
恩,这个问题,反正是我从来没有注意的问题,但今天还是写出来吧 配置信息 hadoop core-site.xml配置 <property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.
安装hadoop-lzo
最近我们部门在测试云计算平台hadoop,我被lzo折腾了三四天,累了个够呛。在此总结一下,也给大家做个参考。 操作系统:CentOS 5.5,Hadoop版本:hadoop-0.20.2-CDH3B4 安装lzo所需要软件包:gcc、ant、lzo、lzo编码/解码器,另外,还需要lzo-devel依赖 配置lzo的文件:core-site.xml、m
hadoop lzo安装
最近我们部门在测试云计算平台hadoop,我被lzo折腾了三四天,累了个够呛。在此总结一下,也给大家做个参考。 操作系统:CentOS 5.5,Hadoop版本:hadoop-0.20.2-CDH3B4 安装lzo所需要软件包:gcc、ant、lzo、lzo编码/解码器,另外,还需要lzo-devel依赖 配置lzo的文件:core-site.xml、m

Hadoop-之配置LZO压缩完整手册
Hadoop-之配置LZO压缩完整手册 1 前言 HADOOP本身除了GIP、DEFLATE、BZIP2等压缩之外是不支持LZO压缩的,所以我们加入需要让HDFS支持LZO(一种可切分的压缩形式,压缩率也很低)压缩,我们需要引入Twitter的Hadoop-LZO,参考地址为:https://github.com/twitter/hadoop-lzo/ 2 hadoop-lzo的编译-构建与

Hive数仓建表时选用ORC还是PARQUET,压缩选Lzo还是snappy?
目录 1 文件存储格式1.1 ORC1.1.1 ORC的存储结构1.1.2 关于ORC的hive配置 1.2 Parquet1.2.1 Parquet的存储结构1.2.2 Parquet的表配置属性 1.3 ORC和Parquet对比 2 压缩方式3 存储和压缩结合该如何选择?3.1 ORC格式存储,Snappy压缩3.2 Parquet格式存储,Lzo压缩3.3 Parquet格式存储,S

Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'存储模式,但是遇到了count(*) 统计结果与select
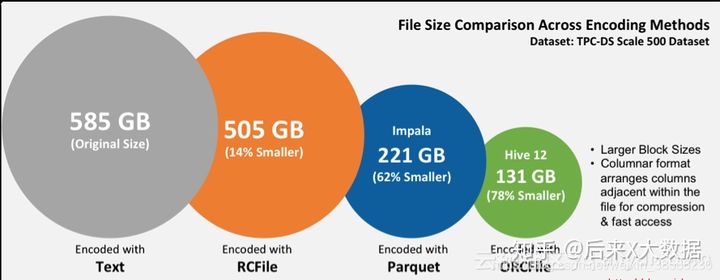
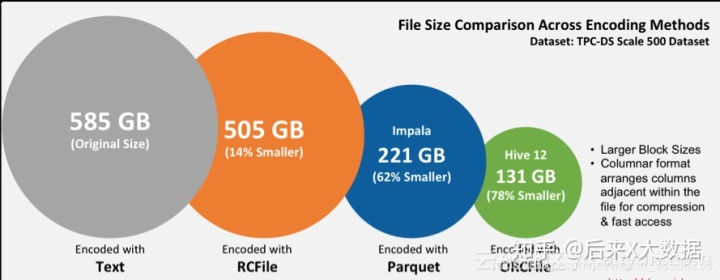
Hive数仓中存储格式ORC和Parquet,压缩方式LZO和Snappy
自我总结: LZO支持切片,Snappy不支持切片。 ORC和Parquet都是列式存储。 ORC和Parquet 两种存储格式都是不能直接读取的,一般与压缩一起使用,可大大节省磁盘空间。 选择:ORC文件支持Snappy压缩,但不支持lzo压缩,所以在实际生产中,使用Parquet存储 + lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数
hive 修改cluster by算法_Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
欢迎大家微信搜索:后来X大数据,更多精彩文章都会在公众号准时更新。 大家好,我是后来,周末理个发,赶脚人都精神了不少,哈哈。 因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.h