longlora专题
七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到微调Mistral、LongLora Llama
前言 如此前这篇文章《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1版》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣 原因在哪呢?本质原因在于无论什么功能,它们基本都是基于API实现的,而关键是API毕竟不是万能

LongLoRA 介绍
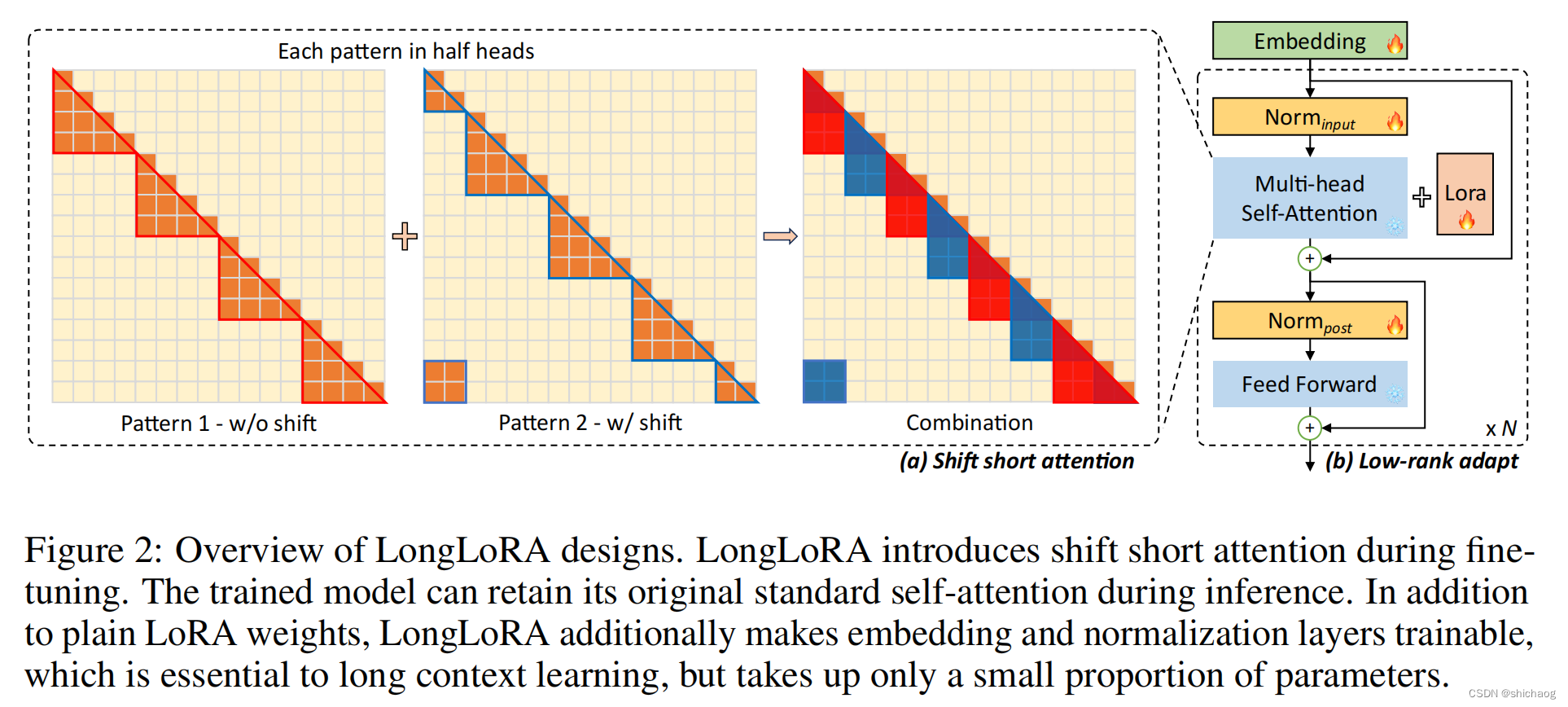
本文将介绍一篇关于使用局部注意力来微调长上下文 LLM 的文章。文章的要点如下: 提出了一种新的局部注意力机制,称为 Shift Short Attention,它可以有效地减少 LLM 处理长上下文所需的计算量。在 LongQA 数据集上对 LongLoRA 进行了评估,结果表明 LongLoRA 在处理长上下文任务上的性能优于其他方法。LongLoRA 的代码和模型已开源。 正文 一、背

七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora
前言 如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣 原因在哪呢?本质原因在于无论什么功能,它们基本都是基于API实现的,而关键
七月论文审稿GPT第二版:从Meta Nougat、GPT4审稿到LongLora版LLaMA、Mistral
前言 如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣 原因在哪呢?本质原因在于无论什么功能,它们基本都是基于API实现的,而关键

LONGLORA: EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS
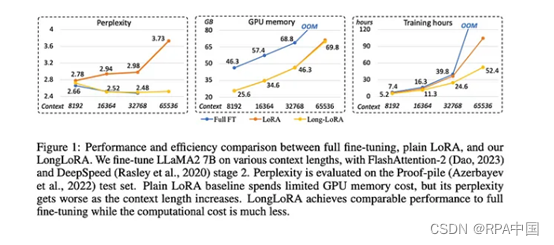
本文是LLM系列文章,针对《LONGLORA: EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS》的翻译。 Longlora:长上下文大型语言模型的高效微调 摘要1 引言2 相关工作3 LongLoRA4 实验5 结论 摘要 我们提出了LongLoRA,一种有效的微调方法,以有限的计算成本扩展预训练的大型语言模型
大语言模型之十六-基于LongLoRA的长文本上下文微调Llama-2
增加LLM上下文长度可以提升大语言模型在一些任务上的表现,这包括多轮长对话、长文本摘要、视觉-语言Transformer模型的高分辨4k模型的理解力以及代码生成、图像以及音频生成等。 对长上下文场景,在解码阶段,缓存先前token的Key和Value(KV)需要巨大的内存开销,其次主流的LLM模型在推理的时候上下文长度都小于等于训练时的上下文长度。为了约束长文本时缓存先前KV的内存和计算量,很容
LongLoRA:超长上下文,大语言模型高效微调方法
麻省理工学院和香港中文大学联合发布了LongLoRA,这是一种全新的微调方法,可以增强大语言模型的上下文能力,而无需消耗大量算力资源。 通常,想增加大语言模型的上下文处理能力,需要更多的算力支持。例如,将上下文长度从2048扩展至8192,需要多消耗16倍算力。 LongLoRA在开源模型LLaMA2 7B/13B/70B上进行了试验,将上下文原始长度扩展至32K、64K、100K,所需要的算