lmm专题
通过语言大模型来学习LLM和LMM(四)
一、大模型学习 新的东西,学习的东西就是多,而且最简单最基础的都需要学习,仿佛一点基础知识都要细嚼慢咽,刨根问底,再加上一顿云里雾里的吹嘘,迷迷糊糊的感觉高大上。其实就是那么一回事。再过一段时日,发现如此简单,甚至不值得一提。从古到今,知识的学习都是如此,只有持续学习,奋力向前。 二、通过语言大模型来学习LLM LLM模型,即Large Language Model,是一种大语言模型,用于预

【多模态】35、TinyLLaVA | 3.1B 的 LMM 模型就可以实现 7B LMM 模型的效果
文章目录 一、背景二、方法2.1 模型结构2.2 训练 pipeline 三、模型设置3.1 模型结构3.2 训练数据3.3 训练策略3.4 评测 benchmark 四、效果 论文:TinyLLaVA: A Framework of Small-scale Large Multimodal Models 代码:https://github.com/TinyLLaVA/Ti
【多模态】34、LLaVA-v1.5 | 微软开源,用极简框架来实现高效的多模态 LMM 模型
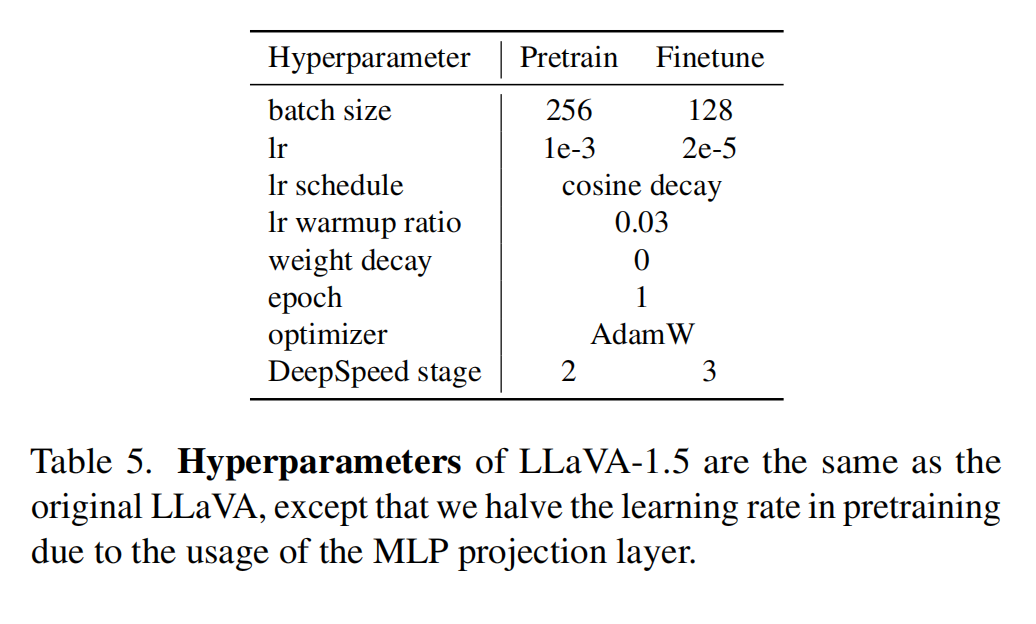
文章目录 一、背景二、方法2.1 提升点2.2 训练样本 三、效果3.1 整体效果对比3.2 模型对于 zero-shot 形式的指令的结果生成能力3.3 模型对于 zero-shot 多语言的能力3.4 限制 四、训练4.1 数据4.2 超参 五、代码 论文:Improved Baselines with Visual Instruction Tuning 代码:http
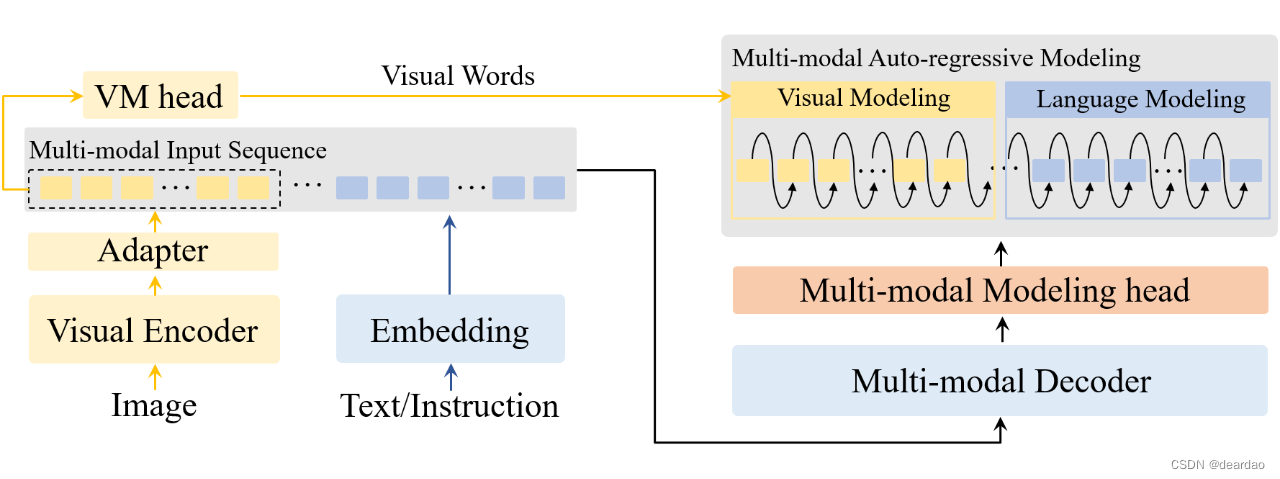
VW-LMM 统一多模态自回归建模框架
将自回归建模扩展到多模态场景以构建大型多模态模型(LMMs)时,存在一个很大的困难,即图像信息在 LMM 中被处理为连续的视觉嵌入,无法获得离散的监督标签用于进行分类损失计算。 该文首次成功地进行了采用统一目标的多模态自回归建模,并且进一步探讨了 LLMs 内部语义空间中视觉特征的分布以及使用文本嵌入来表示视觉信息的可能性。 论文题目:Multi-modal Auto-regressive

【LMM 012】TinyGPT-V:24G显存训练,8G显存推理的高效多模态大模型
论文标题:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones 论文作者:Zhengqing Yuan, Zhaoxu Li, Lichao Sun 作者单位:Anhui Polytechnic University, Nanyang Technological University, Lehigh Un
【LMM 012】TinyGPT-V:24G显存训练,8G显存推理的高效多模态大模型
论文标题:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones 论文作者:Zhengqing Yuan, Zhaoxu Li, Lichao Sun 作者单位:Anhui Polytechnic University, Nanyang Technological University, Lehigh Un

【LMM 008】Instruction Tuning with GPT-4
论文标题:Instruction Tuning with GPT-4 论文作者:Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao 作者单位:Microsoft Research 论文原文:https://arxiv.org/abs/2304.03277 论文出处:– 论文被引:254(12/31/2023) 论
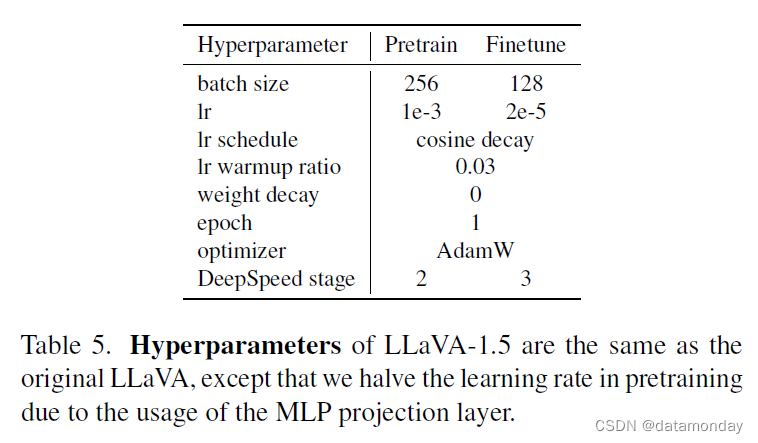
【LMM 002】大型语言和视觉助手 LLaVA-1.5
论文标题:Improved Baselines with Visual Instruction Tuning 论文作者:Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee 作者单位:University of Wisconsin-Madison, Microsoft Research, Columbia University 论文原文:https:
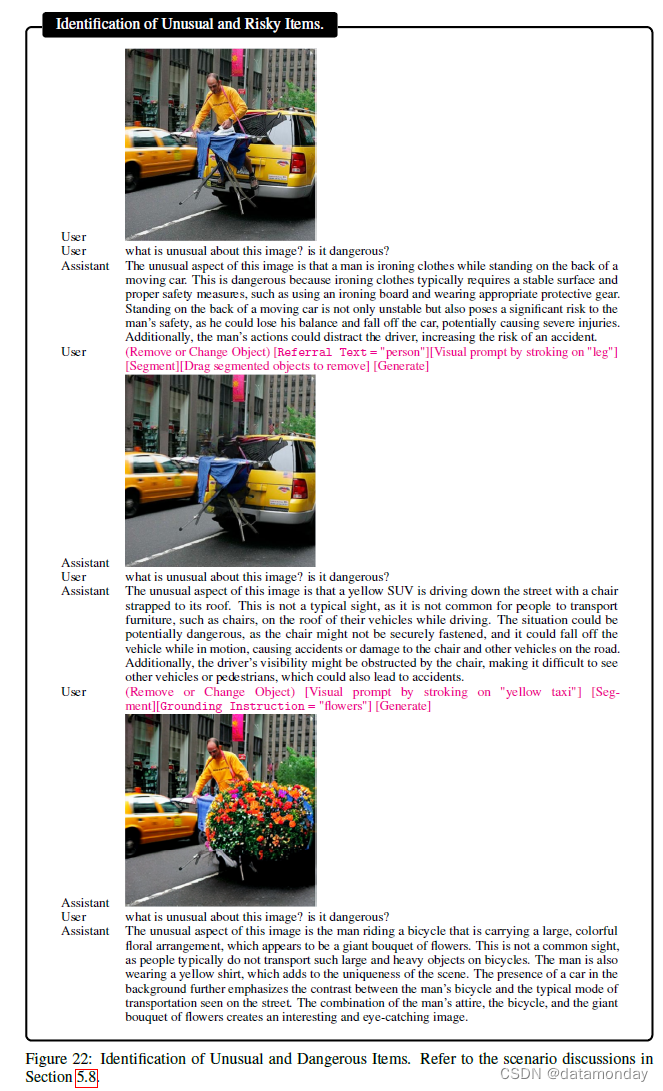
【LMM 005】LLaVA-Interactive:集图像聊天,分割,生成和编辑三种多模态技能于一体的Demo
论文标题:LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing 论文作者:Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, Jianfeng Gao, Chunyuan Li 作者单位:Microsoft Research, R
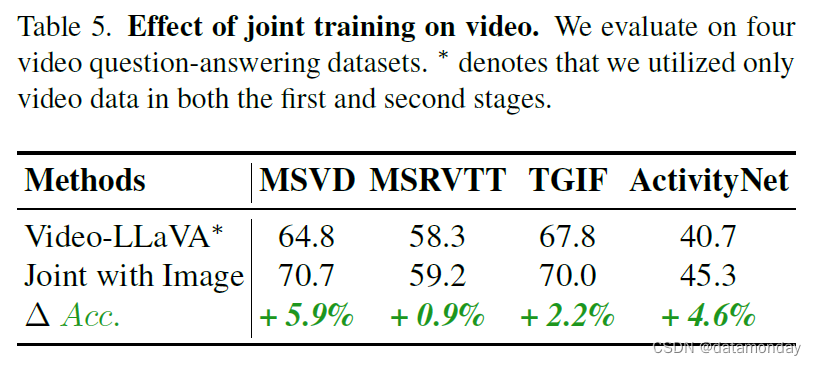
【LMM 007】Video-LLaVA:通过投影前对齐以学习联合视觉表征的视频多模态大模型
论文标题:Video-LLaVA: Learning United Visual Representation by Alignment Before Projection 论文作者:Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan 作者单位:Peking University, Peng Cheng Labo

【LMM 006】LLaVA-Plus:可以学习如何使用工具的多模态Agent
论文标题:LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents 论文作者:Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang,
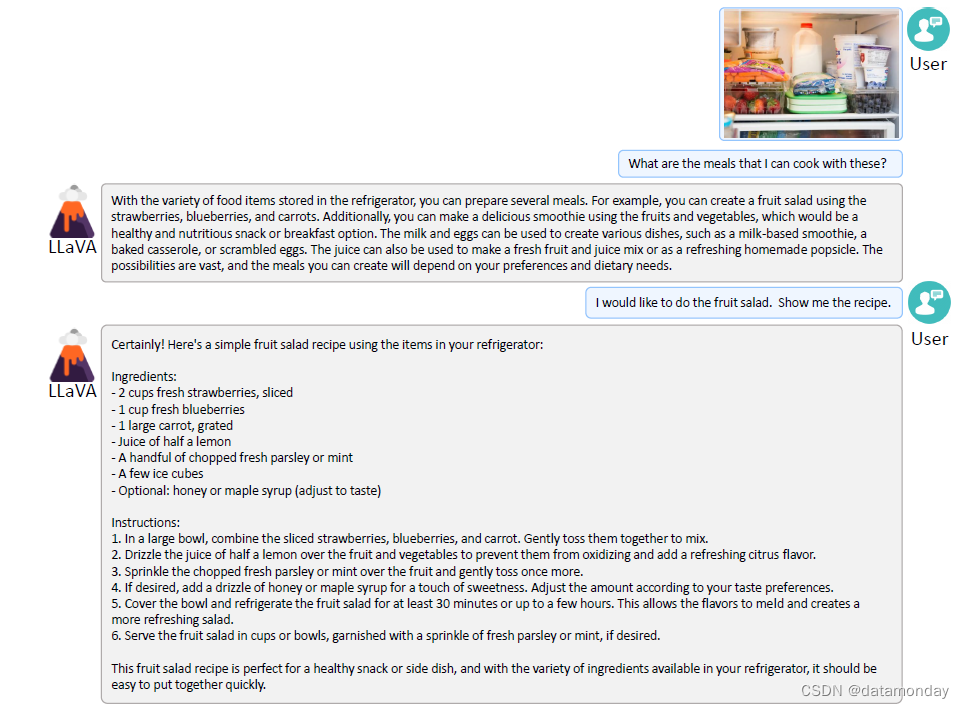
【LMM 001】大型语言和视觉助手 LLaVA
论文标题:Visual Instruction Tuning 论文作者:Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee 作者单位:University of Wisconsin-Madison, Microsoft Research, Columbia University 论文原文:https://arxiv.org/abs/2304.0
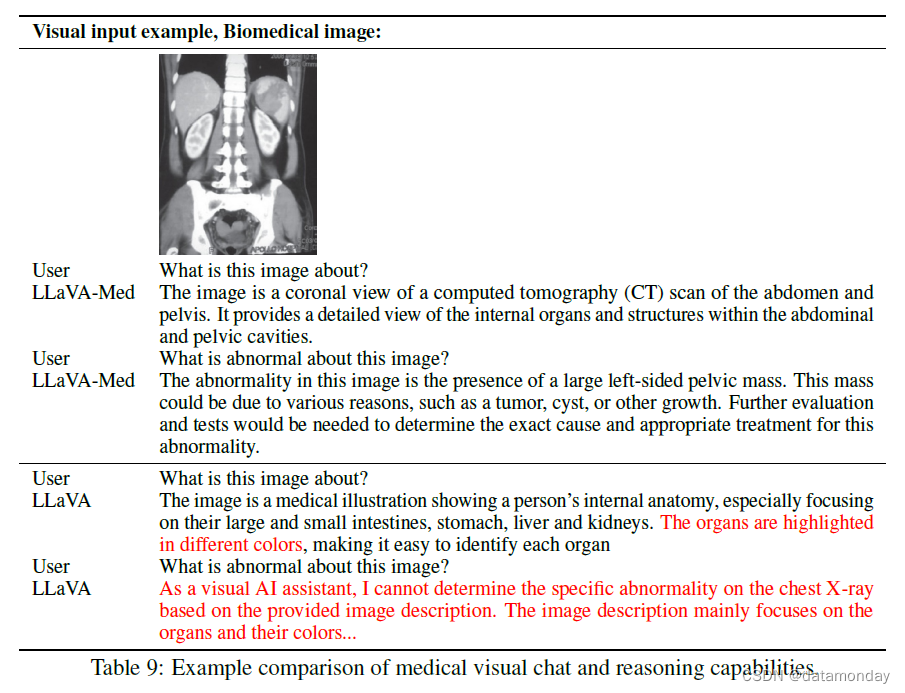
【LMM 003】生物医学领域的垂直类大型多模态模型 LLaVA-Med
论文标题:LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day 论文作者:Chunyuan Li∗, Cliff Wong∗, Sheng Zhang∗, Naoto Usuyama, Haotian Liu, Jianwei Yang Tristan Naumann, Hoifu
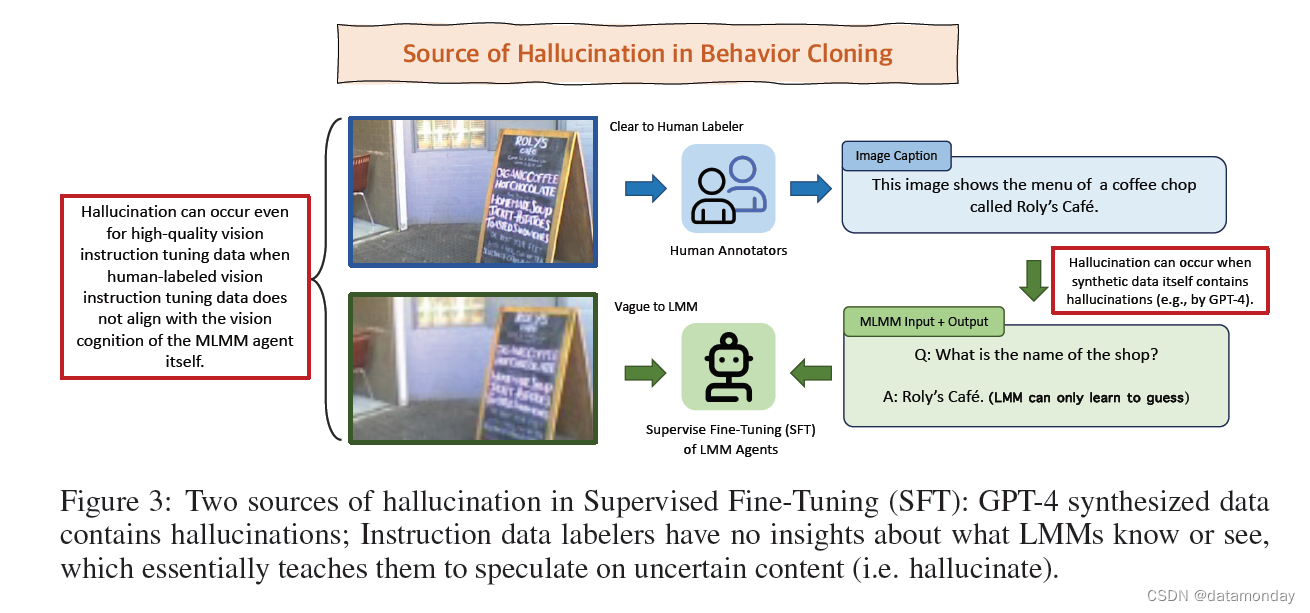
【LMM 004】LLaVA-RLHF:用事实增强的 RLHF 对齐大型多模态模型
论文标题:Aligning Large Multimodal Models with Factually Augmented RLHF 论文作者:Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming

多模态GPT-V出世!36种场景分析ChatGPT Vision能力,LMM将全面替代大语言模型? | 京东云技术团队
LMM将会全面替代大语言模型?人工智能新里程碑GPT-V美国预先公测,医疗领域/OCR实践+166页GPT-V试用报告首发解读 ChatGPT Vision,亦被广泛称为GPT-V或GPT-4V,代表了人工智能技术的新里程碑。作为LMM (Large Multimodal Model) 的代表,它不仅继承了LLM (Large Language Model) 的文本处理能力,还加入了图像处理
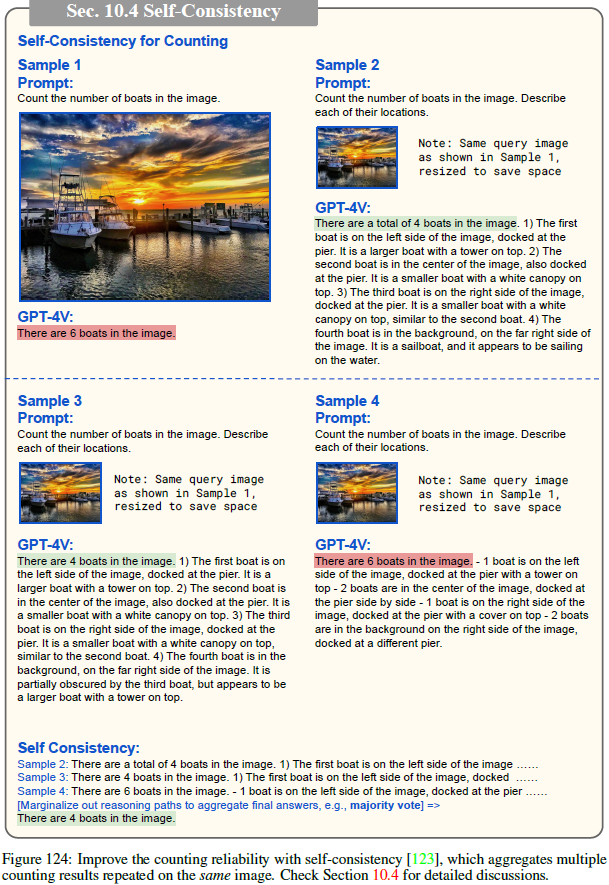
(2023,GPT-4V,LLM,LMM,功能和应用)大型多模态模型的黎明:GPT-4V(ision) 的初步探索
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) 公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 1.1 动机和概述 1.2 我们探索 GPT-4V 的方法 1.3 如何阅读本报告? 2. GPT-4V 的输入模式 2.1