leveldb专题

在netbeans下编译leveldb源码
第一步:# git clone https://code.google.com/p/leveldb 下载leveldb源码 #cd leveldb #sudo chmod +x build_platform 修改为可执行文件 第二步:下载netbeans8.1 sh xxxxxx.sh 即可安装 第三步:将leveldb源码导入netbeans

【AI】caffe使用步骤(一):将标注数据生成lmdb或leveldb
1、简述 caffe使用工具 convert_imageset 将标注数据转换成lmdb或leveldb格式,convert_imageset 使用方法可以参考脚本examples/imagenet/create_imagenet.sh。 convert_imageset 在./build/tools/中。 2、convert_imageset命令行参数 ./build/tools/conv
leveldb 键值数据库
#git clone --recurse-submodules https://github.com/google/leveldb.git拉取子模块 及第三方库#mkdir -p build && cd build#cmake -DCMAKE_BUILD_TYPE=Releas .. && make 测试demo #include <assert.h>#include <string.h

ActiveMQ高可用集群安装、配置(zookeeper + LevelDB)
从ActiveMQ5.9开始,ActiveMQ的集群实现方式取消了传统的Master-Slave方式,增加了基于zookeeper + LevelDB的Master-Slave实现方式,其他两种方式“目录共享”和“数据库共享”依然存在。 三种集群方式的对比: (1)基于共享文件系统(KahaDB,默认) <persistenceAdapter> <kahaDB directory="
分布式专题——详解Google levelDB底层原理
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是分布式专题的第10篇文章,我们继续来聊聊LSMT这个数据结构。 LSMT是一个在分布式系统当中应用非常广泛,并且原理直观简单的数据结构。在上一篇文章当中我们进行了详细的讨论,有所遗忘或者是新关注的同学可以点击下方的链接回顾一下上一讲的内容。 分布式——吞吐量巨强、Hbase的承载者 LSMT leveldb简介 上一篇的内容
ios-leveldb
http://blog.devzeng.com/blog/ios-leveldb.html http://www.code4app.com/thread-11657-1-1.html 去掉armv6,armv7,以及模拟器的架构。

leveldb源码阅读-memtable
memtable在leveldb中扮演着及其重要的地位,用于存储最新的数据修改信息,当数据的规模达到一定的上限之后,就会将数据转存储为immutable memtable,这时候就会被存储到sstale中;因此总的来说,所有在内存的数据都是以memtable进行存储的; memtable的接口如下: void Ref() { ++refs_; }//引用次数// Drop referenc

leveldb阅读-Skiplist
Skiplist是一种随机化的链表,通过并联链表,可以实现数据的快速插入和查找,同时能够取得比较好的时间开销和空间开销。详细的实现原理可以参照http://blog.csdn.net/haidao2009/article/details/8206856。leveldb采用skiplist来实现k-value的处理应该也是综合考虑到空间开销和时间开销的成本。 在介绍leveldb中的Skiplis

leveldb阅读-Status
LevelDB中,使用Status用来统一处理返回状态,其设计业是遵循了之前的一贯设计风格,简单明了。为了节省空间,Status采用了const char* state_;来存储数据,利用 state_[0..3] == length of message来表示状态的长度,state_[4] == code表示状态的类型,state_[5..] == message表示详细信息; Sta
大白话解析LevelDB: TwoLevelIterator
文章目录 TwoLevelIteratorIterator 接口TwoLevelIterator 的实现TwoLevelIterator 的构造函数TwoLevelIterator::InitDataBlock TwoLevelIterator::Seek(const Slice& target)TwoLevelIterator::SeekToFirstTwoLevelIterator::S
大白话解析LevelDB: Block Iterator
文章目录 Block IteratorIterator 接口Block Iterator 的实现Block Iterator 的私有成员Block Iterator 的构造函数Block::Iter::Valid()Block::Iter::status()Block::Iter::key()Block::Iter::value()Block::Iter::Next()Block::Iter

NoSQL 数据库管理工具,搭载强大支持:Redis、Memcached、SSDB、LevelDB、RocksDB,为您的数据存储提供无与伦比的灵活性与性能!
NoSQL 数据库管理工具,搭载强大支持:Redis、Memcached、SSDB、LevelDB、RocksDB,为您的数据存储提供无与伦比的灵活性与性能! 【官网地址】:http://www.redisant.cn/nosql 介绍 直观的用户界面 从单一应用程序中同时连接 Redis、Memcached、SSDB、LevelDB、RocksDB,你可以快速轻松地创建、管理和维护数据库
LevelDB源码阅读笔记(0、下载编译leveldb)
LevelDB源码阅读笔记(0、下载编译leveldb) LeveDB源码笔记系列: LevelDB源码阅读笔记(0、下载编译leveldb) 本博客环境如下 [root@localhost build]# cat /etc/redhat-releaseCentOS Linux release 7.9.2009 (Core) 简介 LevelDB是由Google使用C++开发的磁盘
windows vs 自己编译源码 leveldb 然后使用自己编译的文件
1 准备源码文件 1.1 第一种方法 git下载源码 vs项目中git leveldb源码和git third_party googletest-CSDN博客 1.2 第二种方法 手动下载 然后把第三方的源码下载 复制到 third_party 对应的文件夹中 没有文件夹 third_party -> powershell mkdir third_party 2 编译lev
levelDB中的LRU
https://www.jianshu.com/p/9e7773432772 在诸多的Cache策略中,LRUCache(Least Recently Used,最近最少被使用)因为完美地契合了局部性原理,故而成为最常见的Cache策略。而Cache算法的设计与实现,也是面试中经常会遇到的问题。 下面,让我们来看一下LevelDB中的LRUCache实现。 单条缓存记录:LRUHandle

LevelDb日知录
目录 LevelDb日知录之一:LevelDb 简介 LevelDb日知录之二:整体架构 LevelDb日知录之三:log文件 LevelDb日知录之四:SSTable文件 LevelDb日知录之五:MemTable详解 LevelDb日知录之六 写入与删除记录 LevelDb日知录之七:读取记录 LevelDb日知录之八:Compaction操作 LevelDb日知录之九
LevelDB之Leveled-Compaction
https://github.com/imjoey/blog/issues/6 https://www.jianshu.com/p/99cc0df8ed21 https://juejin.im/post/5c99f0556fb9a070e82c1fcf 目录 一、前言 二、LSM 1、MemTable 2、ImmutableMemTable 3、SSTable 4、SSTable
leveldb源码剖析---缓存系统
通过前面的分析可以知道,leveldb为了提高写的性能,牺牲了部分的读性能。最差的情况可能需要遍历各个level中的每个文件。为了缓解读性能,leveldb引入了缓存机制,当然,版本信息中包含各个level的文件元信息在一定程度上也可以提高读性能。 leveldb提供的缓存系统的底层数据结构是一个开链哈希 class ShardedLRUCache : public Cache :LRUCac
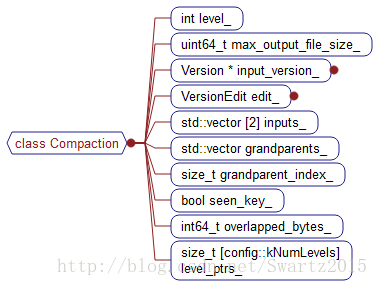
leveldb源码剖析----compaction
根据前面的分析,背景线程的主体工作在BackgroundCompaction函数中完成。这个函数主要完成以下两个工作: 如果imm_非空,则将imm_写入到磁盘中生成新的sstable文件对level中的文件进行合并。合并的目的主要是避免某个level中sstable文件过多,并且可以通过合并的过程删除掉过期的key-value和被用户删除的key-value。 这篇文章主要是从Backgro
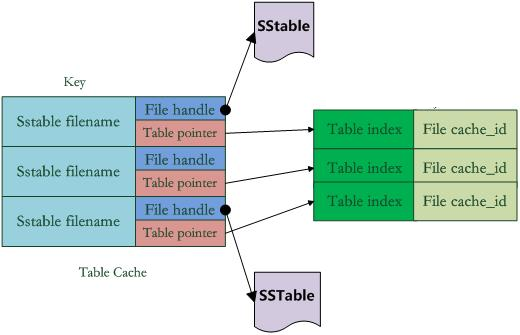
LevelDB原理分析
郑重声明:本篇博客是自己学习 Leveldb 实现原理时参考了郎格科技系列博客整理的,原文地址:http://www.samecity.com/blog/Index.asp?SortID=12,只是为了加深印象,本文的配图是自己重新绘制的,大部分内容与原文相似,大家可以浏览原始页面 :-),感兴趣的话可以一起讨论 Leveldb 的实现原理! LevelDb日知录之一:LevelDb 101
庖丁解LevelDB之概览
LevelDB是Google传奇工程师Jeff Dean和Sanjay Ghemawat开源的KV存储引擎,无论从设计还是代码上都可以用精致优雅来形容,非常值得细细品味。接下来就将用几篇博客来由表及里的介绍LevelDB的设计和代码细节。本文将从设计思路、整体结构、读写流程、压缩流程几个方面来进行介绍,从而能够对LevelDB有一个整体的感知。 设计思路 LevelDB的数据是存储在磁盘上的,

windows 下ActiveMQ集群搭建(ActiveMq+zookeeper+levelDB)
参考文章:Zookeeper的两种安装和配置(Windows) 参考文章:ActiveMQ之集群(主从)搭建 已成功配置伪集群,高可用 启动zookeeper,启动报错正常,等3个服务都启动了,即完全启动了 启动3个activemq服务 如上截图,端口8161服务自动分配为master;另外2个服务为slave;3个服务的话允许一个服务挂断,具体参考说明请查阅zookeepe

LevelDB 源码层次上看读取过程
文章目录 读取流程1)memtable查找2) immutable查找3)SSTable查找 参考文献 读取流程 LevelDB的读取流程相对简单,从其中读取一个数据,会按照从上而下memtable->immutable->sstable的顺序读取,读不到就从下一个层级读取,因此LevelDB更适合读取新写入的数据。流程如下图: Level0中的文件直接由Immutable通过

LevelDB 源码层次看写数据时的过程
文章目录 Write写入流程1)封装WriteBatch和Writer对象2)Writer串行化入队3)确认写入空间足够4)批量取任务,进行合并写批量取任务写入日志数据写入Memtable 5)唤醒正在等待的线程 总结参考文献 Write写入流程 LevelDB对外提供的写入接口有Put、Delete两种,这两种操作都会向Memtable和Log文件中追加一条新纪录。 同时Le