il专题

org.slf4j.impl.JDK14LoggerAdapter.log(Lorg/slf4j/Marker;Ljava/lang/String;ILjava/lang/String;[Ljava/
背景描述:将weblogic工程打成war包在weblogic控制台发布启动时,提示org.slf4j.impl.JDK14LoggerAdapter.log(Lorg/slf4j/Marker;Ljava/lang/String;ILjava/lang/String;[Ljava/ 分析weblogic控制台日志,发现在启动日志的时候提示:slf4j-api-1.6.2.jar版本需要1
unity反编译由IL生成的dll文件
本文由博主SunboyL原创,转载请注明出处:http://www.cnblogs.com/xsln/p/DLL_DeCompilation.html 在Unity实际开发过程中,我们可能会用到大量的插件,而很多插件有可能并非开源,而是封装成dll文件。 使用免费非开源插件时,插件往往缺少维护,这对我们的开发是非常不利的。例如dll暴露的诸多接口,我们并不知道这些接口背后干了

Online RL + IL : TGRL: An Algorithm for Teacher Guided Reinforcement Learning
ICML 2023 Poster paper Intro 文章设定一个专家策略,给出两种优化目标。一个是基于专家策略正则的累计回报,一个是原始累计回报。通过比较二者动态的衡量专家策略对智能体在线学习的影响程度,进而实现在线引导过程。 Method 原始的RL目标是最大化累计奖励: π ∗ = arg max π J R ( π ) : = E [ ∑ t = 0 ∞ γ t r t

com.microsoft.jdbc.base.BasePreparedStatement.setBinaryStream(ILjava/io/InputStr
当数据库字段为blob类型时 ,我们如果使用PreparedStatement中的setBinaryStream(int,InputStream,int)方法需要注意 在向blob字段类型中插入数据时,要使用javaio的inputstream,读入文件。 而相反从blob字段中读出数据时,同样使用javaio的inputstream,再用javaio的outputstream写入文件。

离子液体功能化修饰聚酰胺-胺型树枝状高分子微球/脯氨酸前驱体(IL-Pro)/MIL-101金属有机骨架材料/石墨烯/碳纳米管
离子液体功能化修饰聚酰胺-胺型树枝状高分子微球/脯氨酸前驱体(IL-Pro)/MIL-101金属有机骨架材料/石墨烯/碳纳米管 金属有机骨架因其具有高比表面积和大孔容、有序的孔道结构等优势成为新材料领域的研究热点。本文通过后合成修饰的方法将咪唑型离子液体与金属有机骨架MIL-101结合(图1),制备出一种新型的多功能催化剂用于CO2与环氧化物的环加成反应。通过XRD,FT-IR,SEM,N2吸附
C#面:简述 CTS , CLS , CLR , IL
CTS通用类型系统(Commom Type System): 它定义了在.NET平台上所有类型的规范和行为。CTS确保了不同语言编写的代码可以相互交互操作,并且可以在运行时进行类型安全的检查。 CTS主要包括以下几个方面: 数据类型:CTS定义了一组基本数据类型,如整数、浮点数、布尔值等,以及引用类型(类、接口、委托等)。这些数据类型在不同的编程语言中都有相应的表示方式。类型转换:CTS提供

揭开IL代码的神秘面纱--进阶篇(一)
系列文章目录 揭开IL代码的神秘面纱--基础篇(一) 揭开IL代码的神秘面纱--基础篇(二) 揭开IL代码的神秘面纱--进阶篇(一) 持续更新中...... 工具 IL指令大全 IL指令分类 IL代码编译器 ILDasm 前言 一般我们遍历List的时候,常用的会有三种写法,这三种写法的优缺点大家应该都知道,今天我们就通过IL代码
[你必须知道的.NET]第二十六回:认识元数据和IL(下)
说在,开篇之前书接上回: 第二十四回:认识元数据和IL(上), 第二十五回:认识元数据和IL(中) 我们继续。 终于到了,说说元数据和IL在JIT编译时的角色了,虽然两个回合的铺垫未免铺张,但是却丝毫不为过,因为只有充分的认知才有足够的体会,技术也是如此。那么,我们就开始沿着方法调用的轨迹,追随元数据和IL在那个神秘瞬间所贡献的力量吧。
什么是.Net, IL, CLI, BCL, FCL, CTS, CLS, CLR, JIT
什么是.NET? 起源:比尔盖茨在2000年的Professional Developers Conference介绍了一个崭新的平台叫作Next Generation Windows Service,也就是后来的.NET。 软件层:.NET可以被看作是介于操作系统和编程语言之间的软件层,它可以支持多种编程语言,包括C#,VB.NET,C++,F#,等等。 用来产生托管代码的框架、平台

揭开IL代码的神秘面纱--基础篇(一)
本文阅读时长几分钟,让我们一起揭开IL代码的神秘面纱吧。 前言 偶然一次心血来潮,想要了解更深层次的代码运行逻辑,然后就触碰到了IL代码,对于IL代码没了解之前总感觉很神奇,初一看完全不知所云,但是了解IL代码后你能更加清楚的知道你的代码是如何运行的。 1.1 什么是IL IL是.NET框架中中间语言(Intermediate Language)的缩写。使用.NET框架提供的编译器可以

低损耗MPO光纤连接器的IL值是多少?
随着FTTH的广泛应用,光纤通信对于数据传输容量和速度的要求越来越高,因此产生了对高密度和低损耗的光纤连接器的高需求。 前面有一篇文章我们介绍了什么是插入损耗(Insertion Loss)和回波损耗(Return Loss)?这两个参数是反映光纤连接器光学性能指标的关键。 影响光纤连接损耗的三个因素是纤芯的横向偏移、光纤倾斜和空隙。其中横向偏移是最重要的因素。 对于MPO连接器来说,影响横向

CANoe: IL层的简单理解
目录 问题背景 问题提出 What:IL是什么 How:交互层的作用 推理IL功能:从DBC创建模板 推理IL功能:从DBC配置Node属性 推理IL功能:从CAPL函数 AutoSar中的IL 问题背景 在CAN总线仿真案例中, 创建DBC时,使用了模板文件Vector_IL_Basic Template.dbcDBC配置节点属性时,NodeLayerModules均采

OpenMAX/IL: OMX IL 学习笔记【1】- 结构框架
本篇文章对OpenMAX做了一个整体的介绍与概述,说明OpenMAX是什么?可以解决什么问题?用在什么地方?以及为什么要用OpenMAX?这里并不对OpenMAX进行深入介绍(放到接下来的几篇文章里面),希望通过这篇文章可以对OpenMAX有一个大体的了解。 一、OpenMax简介 (1)什么是OpenMAX? OpenMAX(Open Media Acceleration的缩写,开放


.Net .Net Core 反编译 IL Spy
下载软件 : https://pan.baidu.com/s/1VsOMZGAGg2pgqWUmXCSlqA 反编译 Redis 和 Dapper

OpenMax IL层设计分析总结
文章目录 一、OpenMax的设计理念与特性点设计理念---媒体框架的抽象/可移植性/异步处理/组件组合设计特性---组件化API/方便新增解码器/方便扩展/支持动态链接/可配置 二、OpenMax的设计点分析2.1 【兼容性】版本兼容性设计---组件版本号\指针函数\入参void指针2.2 【扩展性】新增组件设计---动态库新增组件2.3 【扩展性】新增组件新增私有功能 设计---扩展参数

氨基功能化离子液体修饰SBA-15(NH2-IL-SBA)|含有烯丙基的离子液体氯化1-烯丙基-3-甲基咪唑(AMIMCl)
氨基功能化离子液体修饰SBA-15(NH2-IL-SBA)|含有烯丙基的离子液体氯化1-烯丙基-3-甲基咪唑(AMIMCl) 氨基功能化离子液体修饰SBA-15(NH2-IL-SBA)的描述 合成了氨基以及氨基功能化离子液体修饰的介孔材料SBA-15(NH2-SBA和NH2-IL-SBA),并以戊二醛为活化剂对NH2-IL-SBA进行活化处理(CA-NH2-IL-SBA),通过元素分析,N2吸
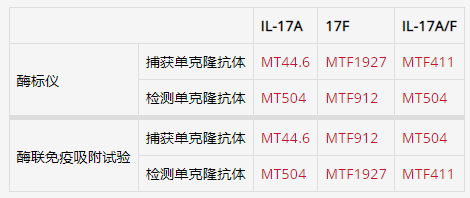
艾美捷抗人IL-17A单抗MT504说明书来啦
艾美捷抗人IL-17A单抗MT504分析物信息: IL-17A/F 白介素-17F(IL-17F,IL17F)属于IL-17A蛋白家族。IL-17A/F 是由一个 A 亚基和一个 F 亚基组成的异二聚体。它是由活化的 Th17(T 辅助 17)细胞和某些属于先天免疫系统的细胞产生的促炎细胞因子。 IL-17A IL-17A (IL-17A, IL17A) 是一种有效的促炎细胞因子,由活