hivesql专题

面试必备技能-HiveSQL优化
Hive SQL基本上适用大数据领域离线数据处理的大部分场景。Hive SQL的优化也是我们必须掌握的技能,而且,面试一定会问。那么,我希望面试者能答出其中的80%优化点,在这个问题上才算过关。 Hive优化目标 在有限的资源下,执行效率更高常见问题 数据倾斜map数设置reduce数设置其他 Hive执行 HQL --> Job --> Map/Reduce执行计划 explain [ex

Hive/HiveSQL常用优化方法全面总结
Hive作为大数据领域常用的数据仓库组件,在平时设计和查询时要特别注意效率。影响Hive效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、job或I/O过多、MapReduce分配不合理等等。对Hive的调优既包含对HiveSQL语句本身的优化,也包含Hive配置项和MR方面的调整。 《2021年最新版大数据面试题全面开启更新》 《2021年最新版大数据面试题全面开启更新》 目录 列

大数据-数仓-数仓工具:Hive(离线数据分析框架)【替代MapReduce编程;插入、查询、分析HDFS中的大规模数据;机制是将HiveSQL转化成MR程序;不支持修改、删除操作;执行延迟较高】
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。 Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。 Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单

HiveSQL解析原理
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用。美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析。Hive的稳定性和性能对我们的数据分析非常关键。 在几次升级Hive的过程中,我们遇到了一些大大小小的问题。通过向社区的 咨询和自己的努力,在解决这些问题的同时我们对Hive将SQL编译为MapReduce的过

SQL用户观看时长问题分析--HiveSQL面试题19
0 题目 1 数据准备 2 数据分析 4 小结 0 题目 数据如下: date user_id age programid Playtime 20190421 u1 30 a 4 20190421 u1 30 b 10 20190421 u1 30 a 2 20190421 u2

HiveSQL基础Day03
回顾总结 hive表的类型 :内部表和外部表 删除内部表会删除表的所有数据 删除外部表只会删除表的元数据,hdfs上的行数据会保留 表的分区和分桶 本质都是对表数据的拆分存储 分区的方式 是通过创建不同的目录来拆分数据 ,根据数据本身的内容最为目录名 分桶的方式 是通过创建不同的文件来拆分数据 文件名时hash取余的名字 数据拆分后可以提升数据的查询效率 分桶还有特殊使用场景 分桶

HiveSQL如何生成连续日期剖析
HiveSQL如何生成连续日期剖析 情景假设: 有一结果表,表中有start_dt和end_dt两个字段,,想要根据开始和结束时间生成连续日期的多条数据,应该怎么做?直接上结果sql。(为了便于演示和测试这里通过SELECT '2024-03-01' AS start_dt,'2024-03-06' AS end_dt模拟一个结果表数据) SELECT t1.start_dt,t1.end_

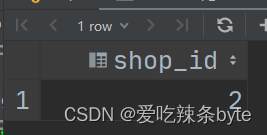
HiveSQL——连续增长问题
注:参考文章: SQL连续增长问题--HQL面试题35_sql判断一个列是否连续增长-CSDN博客文章浏览阅读2.6k次,点赞6次,收藏30次。目录0 需求分析1 数据准备3 小结0 需求分析假设我们有一张订单表shop_order shop_id,order_id,order_time,order_amt 我们需要计算过去至少3天销售金额连续增长的商户shop_id。数据如下:shop_ido
HiveSQL——用户行为路径分析
注:参考文档: SQL之用户行为路径分析--HQL面试题46【拼多多面试题】_路径分析 sql-CSDN博客文章浏览阅读2k次,点赞6次,收藏19次。目录0 问题描述1 数据分析2 小结0 问题描述已知用户行为表 tracking_log, 大概字段有:(user_id 用户编号, op_id 操作编号, op_time 操作时间)要求:(1)统计每天符合以下条件的用户数:A操作之后是B操作,A

HiveSQL——sum(if()) 条件累加
注:参考文章: HiveSql面试题10--sum(if)统计问题_hive sum if-CSDN博客文章浏览阅读5.8k次,点赞6次,收藏19次。0 需求分析t_order表结构字段名含义oid订单编号uid用户idotime订单时间(yyyy-MM-dd)oamount订单金额(元)所有在2018年1月下过单并且在2月没有下过单的用户,在3月份的下单情况:目标字段名含义_hive sum
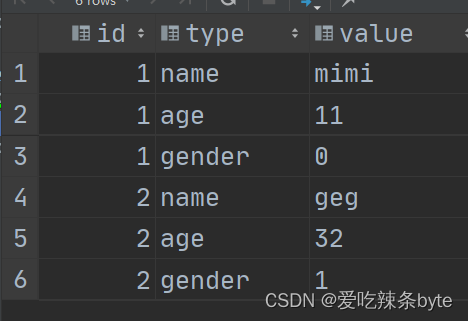
HiveSQL——不使用union all的情况下进行列转行
参考文章: HiveSql一天一个小技巧:如何不使用union all 进行列转行_不 union all-CSDN博客文章浏览阅读881次,点赞5次,收藏10次。本文给出一种不使用传统UNION ALL方法进行 行转列的方法,其中方法一采用了concat_ws+posexplode()方法,利用posexplode的位置索引实现key-value之间的一一对应,方法二采用explode()+c
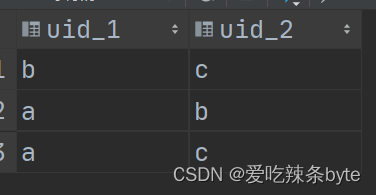
HiveSQL——共同使用ip的用户检测问题【自关联问题】
注:参考文章: SQL 之共同使用ip用户检测问题【自关联问题】-HQL面试题48【拼多多面试题】_hive sql 自关联-CSDN博客文章浏览阅读810次。0 问题描述create table log( uid char(10), ip char(15), time timestamp);insert into log valuesinsert into log values('a', '1
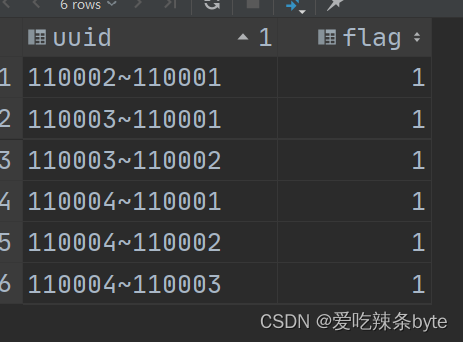
HiveSQL——用户中两人一定认识的组合数
注:参考文章: SQL之用户中两人一定认识的组合数--HQL面试题36【快手数仓面试题】_sql面试题-快手-CSDN博客文章浏览阅读1.2k次,点赞3次,收藏12次。目录0 需求分析1 数据准备2 数据分析3 小结0 需求分析设表名:table0现有城市网吧访问数据,字段:网吧id,访客id(身份证号),上线时间,下线时间规则1、如果有两个用户在一家网吧的前后上下线时间在10分钟以内,则两人可
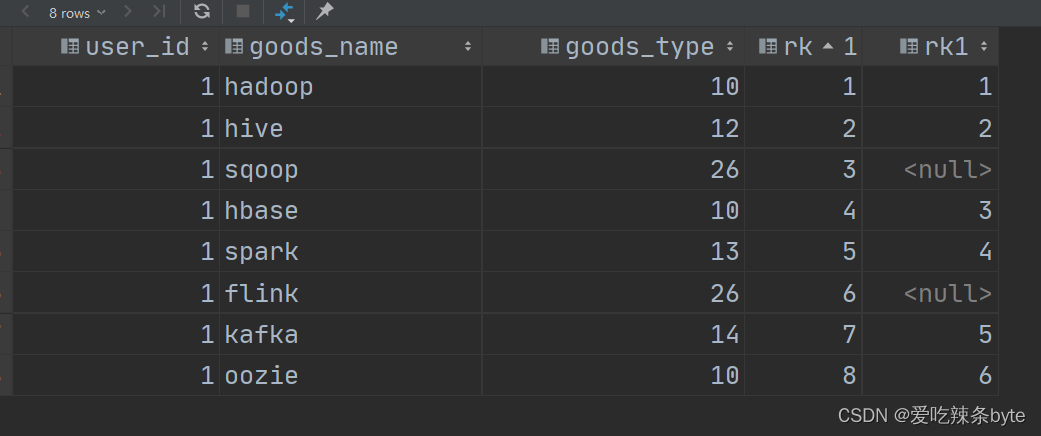
HiveSQL——条件判断语句嵌套windows子句的应用
注:参考文章: SQL条件判断语句嵌套window子句的应用【易错点】--HiveSql面试题25_sql剁成嵌套判断-CSDN博客文章浏览阅读920次,点赞4次,收藏4次。0 需求分析需求:表如下user_idgood_namegoods_typerk1hadoop1011hive1221sqoop2631hbase1041spark1351flink2661kafka1471oozie108
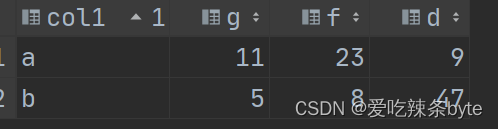
HiveSQL——借助聚合函数与case when行转列
一、条件函数 if 条件函数 if函数是最常用到的条件函数,其写法是if(x=n,a,b), x=n代表判断条件,如果x=n时,那么结果返回a ,否则返回b。 selectif(age < 25 or age is null, '25岁以下', '25岁以上') as age_cnt,count(1) as numberfrom table1group by age_cn
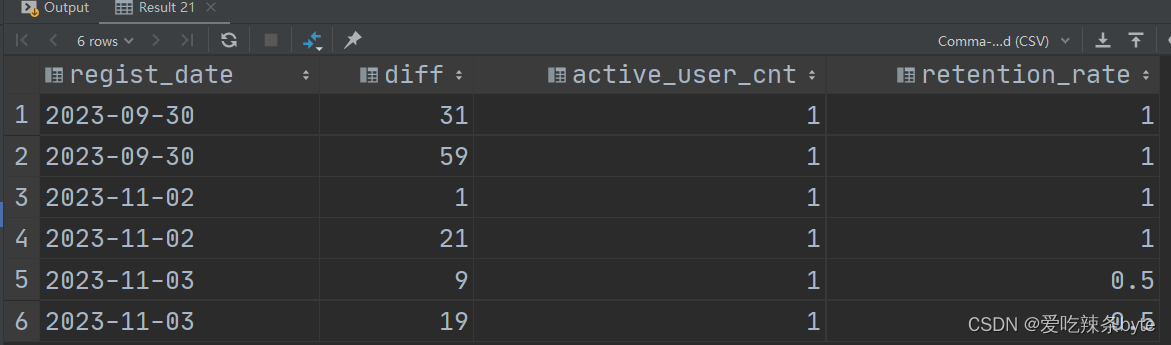
HiveSQL——设计一张最近180天的注册、活跃留存表
0 问题描述 现有一个用户活跃表user_active(user_id,active_date)、 用户注册表user_regist(user_id,regist_date),表中分区字段都为dt(yyyy-MM-dd),用户字段均为user_id; 设计一张 1-180天的注册活跃留存表;表结构如下: 1 数据分析 完整的代码如下: selectregist_date,dif

HiveSQL题——collect_set()/collect_list()聚合函数
一、collect_set() /collect_list()介绍 collect_set()函数与collect_list()函数属于高级聚合函数(行转列),将分组中的某列转换成一个数组返回,常与concat_ws()函数连用实现字段拼接效果。 collect_list:收集并形成list集合,结果不去重 collect_set:收集并形成set集合,结果去重 二、coll
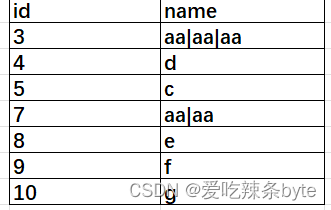
HiveSQL题——数据炸裂和数据合并
目录 一、数据炸裂 0 问题描述 1 数据准备 2 数据分析 3 小结 二、数据合并 0 问题描述 1 数据准备 2 数据分析 3 小结 一、数据炸裂 0 问题描述 如何将字符串1-5,16,11-13,9" 扩展成 "1,2,3,4,5,16,11,12,13,9" 且顺序不变。 1 数据准备 with data as (select '1-5,16,11-
HiveSQL题——炸裂函数(explode/posexplode)
目录 一、炸裂函数的知识点 1.1 炸裂函数 explode posexplode 1.2 lateral view 侧写视图 二、实际案例 2.1 每个学生及其成绩 0 问题描述 1 数据准备 2 数据分析 3 小结 2.2 日期交叉问题 0 问题描述 1 数据准备 2 数据分析 3 小结 2.3 用户消费金额 0 问题描述 1 数据准备 2 数据分析
HiveSQL题——聚合函数(sum/count/max/min/avg)
目录 一、窗口函数的知识点 1.1 窗户函数的定义 1.2 窗户函数的语法 1.3 窗口函数分类 聚合函数 排序函数 前后函数 头尾函数 1.4 聚合函数 二、实际案例 2.1 每个用户累积访问次数 0 问题描述 1 数据准备 2 数据分析 3 小结 2.2 各直播间最大的同时在线人数 0 问题描述 1 数据准备 2 数据分析 3 小结 2.3 历史至今
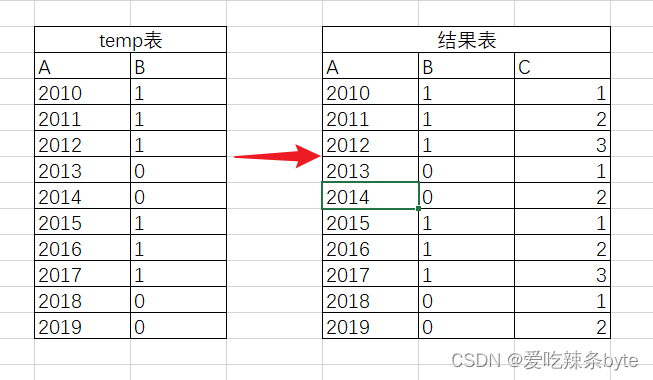
HiveSQL题——窗口函数(lag/lead)
目录 一、窗口函数的知识点 1.1 窗户函数的定义 1.2 窗户函数的语法 1.3 窗口函数分类 1.4 前后函数:lag/lead 二、实际案例 2.1 股票的波峰波谷 0 问题描述 1 数据准备 2 数据分析 3 小结 2.2 前后列转换(面试题) 0 问题描述 1 数据准备 2 数据分析 3 小结 一、窗口函数的知识点 1.1 窗户函数的定义
HiveSQL题——排序函数(row_number/rank/dense_rank)
一、窗口函数的知识点 1.1 窗户函数的定义 窗口函数可以拆分为【窗口+函数】。窗口函数官网指路: LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageMan

HiveSQL题——用户连续登陆
目录 一、连续登陆 1.1 连续登陆3天以上的用户 0 问题描述 1 数据准备 2 数据分析 3 小结 1.2 每个用户历史至今连续登录的最大天数 0 问题描述 1 数据准备 2 数据分析 3 小结 1.3 每个用户连续登录的最大天数(间断也算) 0 问题描述 1 数据准备 2 数据分析 3 小结 一、连续登陆 1.1 连续登陆3天以上的用户 0 问题
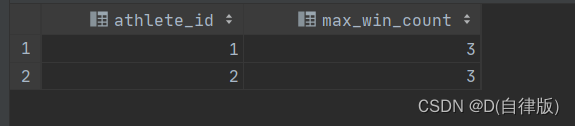
每日HiveSQL_求解运动员最大连胜的次数_15
1.现需要从运动员比赛结果表中统计每个运动员最大连胜的次数 需求结果: 2.所用到的表和数据 --表创建CREATE TABLE athlete_results(athlete_id INT,match_time TIMESTAMP,result VARCHAR(10) -- 'win', 'lose', 'draw');--数据装载INSERT INTO athle
HiveSQL实战 -- 电子商务消费行为分析(附源码和数据)
一、前言 Hive 学习过程中的一个练习项目,如果不妥的地方或者更好的建议,欢迎指出!我们主要进行一下一些练习: 数据结构数据清洗基于Hive的数据分析 二、项目需求 首先和大家讲一下这个项目的需求: 「对某零售企业最近1年门店收集的数据进行数据分析」 潜在客户画像用户消费统计门店的资源利用率消费的特征人群定位数据的可视化展现 三、数据结构 本次练习一共用到四张表,如下:「文末有获取方式」 Cu