本文主要是介绍HiveSQL面试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
手写HQL 第1题
表结构:uid,subject_id,score
求:找出所有科目成绩都大于某一学科平均成绩的学生
思路:求出所有科目的平均成绩,若都大于平均成绩则为0,否则为1;
求和都是0则都大于平均成绩
数据集如下
1001 01 90
1001 02 90
1001 03 90
1002 01 85
1002 02 85
1002 03 70
1003 01 70
1003 02 70
1003 03 85
1)建表语句
create table score(
uid string,
subject_id string,
score int)
row format delimited fields terminated by '\t';
2)求出每个学科平均成绩
select
uid,
score,
avg(score) over(partition by subject_id) avg_score ---按学号分组求出平均值
from
score;t1
3)根据是否大于平均成绩记录flag,大于则记为0,否则记为1
select
uid,
if(score>avg_score,0,1) flag
from
t1;t2
4)根据学生id进行分组统计flag的和,和为0则是所有学科都大于平均成绩
select
uid
from
t2
group by
uid
having ---在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
---HAVING 子句可以让我们筛选分组后的各组数据。
sum(flag)=0;
5)最终SQL
select
uid
from
(select
uid,
if(score>avg_score,0,1) flag
from
(select
uid,
score,
avg(score) over(partition by subject_id) avg_score
from
score) t1 ) t2
group by
uid --分组
having
sum(flag)=0; ---筛选
1)核心问题剖析
从最终的需求可以看出,我们计算的结果是随着行的变化而变化,我们把这类问题称为移动计算。在hivesql中其实解决此类问题我们是通过移动窗口来解决的,类似于spark中的滑动窗口。那么控制此类行的变化范围hive中给出了具体的方法--窗口子句。
窗口:over(),分析函数如:row_number(),max(),lag()等。
分析函数+窗口函数:窗口的本质就是指明了分析函数分析数据时要处理的数据范围(作用域)。
窗口分为静态窗口和移动窗口(也叫滑动窗口),静态窗口指分析数据的范围是固定不变的。滑动窗口指按照行的变化,窗口数据也随着变换,不同的行对应着不同的窗口数据(类似于与spark中的滑动窗口,随着时间的变化,窗口数据也发生着变化)。窗口也是SQL编程的思维本质,就是对范围内的数据进行处理。
窗口子句:窗口函数包括三个窗口子句。分组:partition by; 排序:order by; 窗口大小:rows.使用语法如下:
over(partition by xxx order by yyy rows between zzz)
窗口子句范围大小的控制:
rows或(range)子句往往来控制窗口边界范围的,其语法如下:
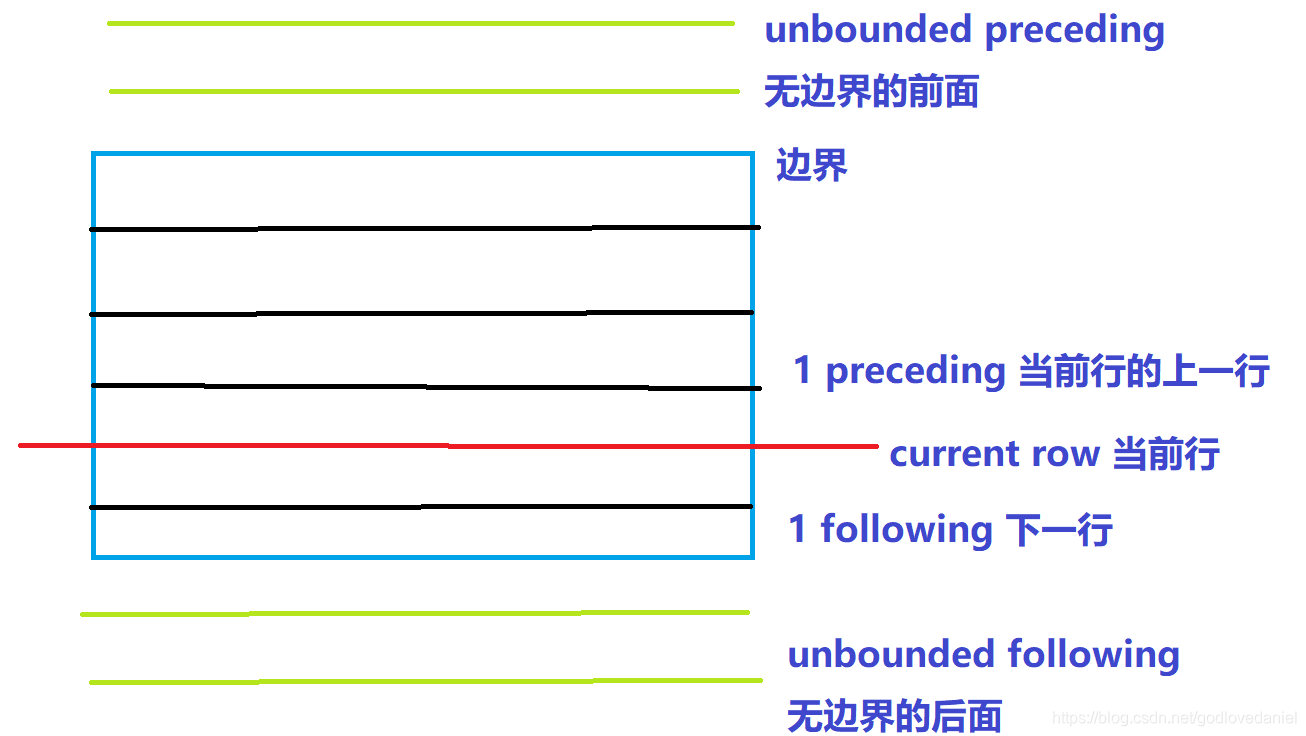
ROWS between CURRENT ROW | UNBOUNDED PRECEDING | [num] PRECEDING AND UNBOUNDED FOLLOWING | [num] FOLLOWING| CURRENT ROW
或
RANGE between [num] PRECEDING AND [num]FOLLOWING
CURRENT ROW:当前行;
n PRECEDING:往前n行数据;
n FOLLOWING:往后n行数据;
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
注意:
rows:rows是真实的行数,也就是我们实际中所说的1,2,3...连续的行数。
range:range是逻辑上的行数,所谓的逻辑行指的就是需要通过计算才能知道是哪一行。range后面跟计算表达式,对order by后面的某个字段值进行计算,计算后的结果表示其真正的范围。(逻辑偏移量构成)。
id 列
1
1
3
6
6
6
7
8
9
分析下面两个语句:
SUM(ID) over(ORDER BY ID ROWS BETWEEN 1 preceding AND 2 following) rows_sum
SUM(ID) over(ORDER BY ID RANGE BETWEEN 1 preceding AND 2 following) range_sum
1.物理上的rows:表示从当前行为参考点,数据范围为前一行与后两行范围内求得的结果。数据范围为:
当前行为第一行时:数据范围如下图所示
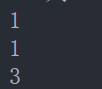
sum(id)=1+1+3=5
当前行为第二行时:数据范围如下图所示

sun(id)=1+1+3+6=11
当前行为第三行时:数据范围如下图所示
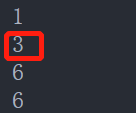
sum(id) = 1+3 +6 +6=16
......
整个过程如下图所示:
整个窗口的变化过程就像按照每一行进行移动,移动的数据范围由窗口子句指定

2.逻辑上的range:数据的范围需要按照id进行计算。
计算公式为:RANGE BETWEEN 1 preceding AND 2 following。
翻译为:当前行的值(此处为id的值,具体是以order by 后字段进行计算的)id-1=<id<=id +2。简单的说就是到当前行为止,id的值在[id-1,id-2]范围内的所有行的统计值。
当为第一行时:id=1,计算公式为id-1=<id<=id +2 范围为:0~3的id值,注意此处不是0到3行,而是id值为0到3的所有行。具体如下图所示:
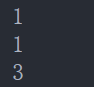
sum(id)=1+1+3=5
当为第四行时:id=6, 计算公式为id-1=<id<=id +2,范围为:[5,8]。即id值包含在5~8之间的所有行,id值大于5小于8的行。具体如下图所示
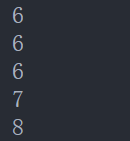
sum(id) = 6+6+6+7+8=33
range的应用场景:比如有一张员工薪资表。我想知道比当前员工薪资高1000元的员工总数。此时range就很好用。
窗口函数几点认识如下:
a 当窗口函数over()出现分组(partition by)子句时:
unbounded preceding即第一行是指表中一个分组里的第一行, unbounded following即最后一行是指表中一个分组里的最后一行;
b 当开窗函数over()无分组(partition by)子句时
unbounded preceding即第一行是指表中的第一行, unbounded following即最后一行是指表中的最后一行。
c 而无论是否省略分组子句,以下结论都是成立的:
1、窗口子句不能单独出现,必须有order by子句时才能出现。
2、当省略窗口子句时:
a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前
行,即在当前组中,第一行到当前行
b) 如果没有order by则默认的窗口是unbounded preceding and unbounded following --整个组
总结如下:
有分组有order by 则为分组中第一行到当前行
有分组无order by 则为整个分组
无分组有order by 则为整个表中第一行到当前行
无分组无order by 则为整个表。即over()
d.窗口函数中的分组与group by的区别1
1.group by 分组返回值只有一个,一组中只返回一个结果。窗口函数中partition by分组,每组每行中都会有一个分析结果。
select 中的字段必须出现在group by中,而窗口函数中partition by分组则无此限制,其分析的结果可以与表中的其他字段并列,其相当于在原表每个分组中添加了一列。
2.如果开窗函数在 group by后的结果集中使用时,那么窗口中无其他限定时,一般把一组看成一条记录,相当于先进行分组后,分组后这一组内整体的记录数被作为一条记录。窗口函数也是基于整个group by后的查询结果,而不是基于每组组内的查询结果。
3.group by 汇总后行数减少,partition by汇总后原表中的行数没变。这个也是为什么使用窗口函数分组而不使用group by的原因。具体如下所示:


e 窗口函数执行顺序及使用规则
(1)先看sql的执行顺序
1 from
2 on
3 join
4 where
5 group by
6 with
7 having
8 select
9 distinct
10 order by
11 limit
(2) 窗口函数执行顺序:窗口函数只能在select命令中和select命令之后使用,不能在where中使用,其执行顺序是和select同级别的,位于distinct顺序之前,可以把窗口函数与分析函数结合后形成的看成select中字段一样,也是可以取别名的,是select的一部分。和聚合函数不能在where语句中使用是一个道理。
f.窗口函数与group by的区别2
通过e,HiveSQL的执行顺序我们知道,窗口函数的执行是在group by,having之后进行,是与select同级别的,所以我们可以得出窗口函数的partition by与group by的一个重要区别就是,如果SQL中既使用了group by又使用了partition by,那么此时partition by的分组是基于group by分组之后的再次分组,分析的数据范围也是基于group by后的数据。一定要注意分析函数如count(*)只是针对over()中的数据进行分析。例如:先进行了group by XXX 后使用了count(*) over(partition by XXX),此时count只是对group by 后的数据再进行partition by后进行统计。
窗口中的partition by不进行去重,而group by进行去重
例子:
name orderdate cost
jack 2017-01-01 10
jack 2017-02-03 23
jack 2017-01-05 46
jack 2017-04-06 42
jack 2017-01-08 55
mart 2017-04-08 62
mart 2017-04-09 68
mart 2017-04-11 75
mart 2017-04-13 94
(1)实验1:用group by及partiton by进行分组。
=======================gruop by=======================
select
name,
count(*)
from
overdemo
where
date_format(orderdate,'yyyy-MM')='2017-04'
group by
name;
--------结果---------
name _c1
jack 1
mart 4
=======================partition by========================
select
name,
count(*) over(partition by name)
from
overdemo
where
date_format(orderdate,'yyyy-MM')='2017-04';
--------结果---------
name count_window_0
jack 1
mart 4
mart 4
mart 4
mart 4
- 实验结果:group by去重,partition by不去重
(2)实验2:在group by基础上再进行partiton by
=====先group by name后over(partition by name)=====
select
name,
count(*) over(partition by name)
from
overdemo
where
date_format(orderdate,'yyyy-MM')='2017-04'
group by
name;
---------结果--------
name count_window_0
jack 1
mart 1
对比实验
=======================只有gruop by的情况=======================
select
name,
count(*)
from
overdemo
where
date_format(orderdate,'yyyy-MM')='2017-04'
group by
name;
--------结果---------
name _c1
jack 1
mart 4
===
这篇关于HiveSQL面试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








