gemm专题
发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解
文章目录 [发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解](https://cyj666.blog.csdn.net/article/details/138514145)先来看一下最简单的`struct GemmIdentityThreadblockSwizzle`结构体 发表博客之:gemm/thr
Tensor Core 基本原理 CUDA Core Tensor Core RT CoreAI 工作负载 线程束(Warp) CNN GEMM 混合精度训练
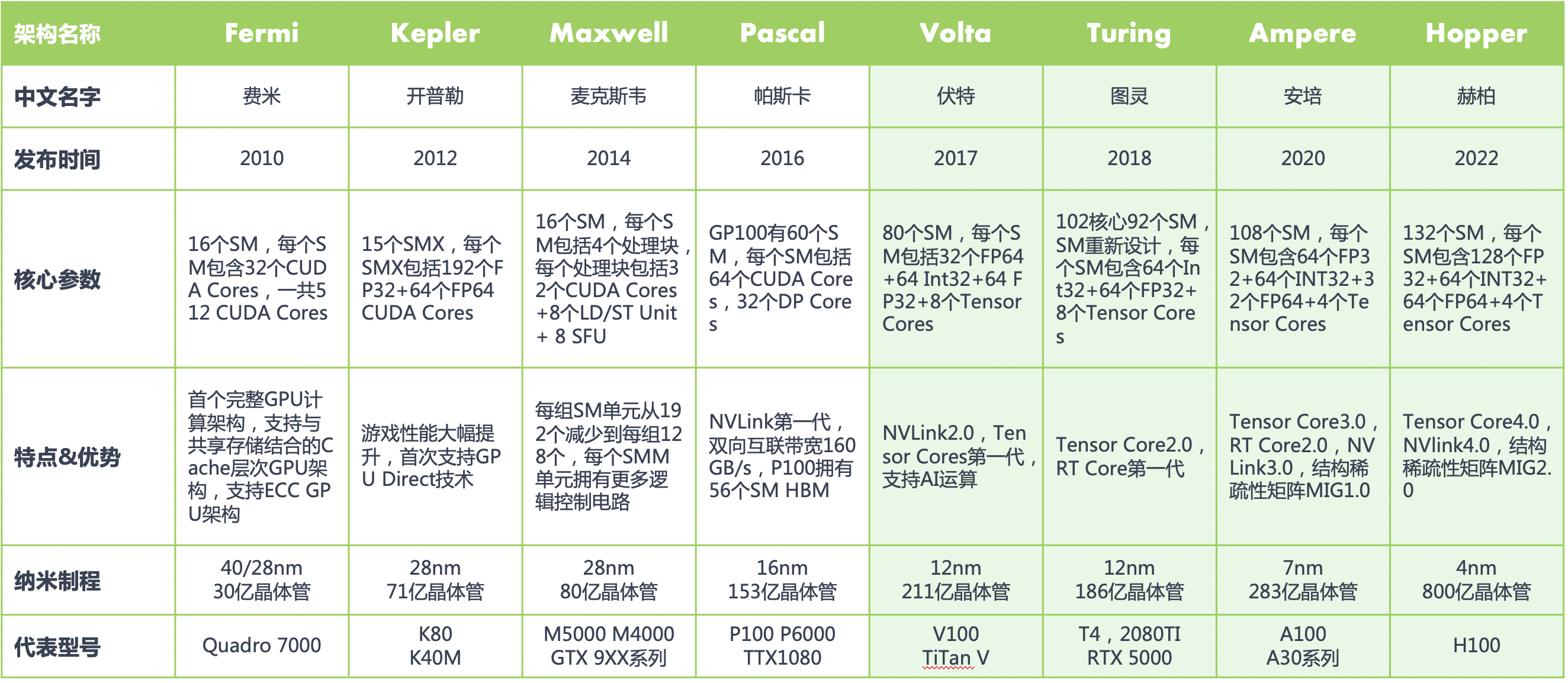
Tensor Core 基本原理 在 NVIDIA 的通用 GPU 架构中,存在三种主要的核心类型:CUDA Core、Tensor Core 以及 RT Core。其中,Tensor Core 扮演着极其关键的角色。 Tensor Core 是针对深度学习和 AI 工作负载而设计的专用核心,可以实现混合精度计算并加速矩阵运算,尤其擅长处理半精度(FP16)和全精度(FP32)的矩阵乘法和累加

八. 实战:CUDA-BEVFusion部署分析-学习spconv的优化方案(Implicit GEMM conv)
目录 前言0. 简述1. 什么是Implicit GEMM Conv2. Explicit GEMM Conv3. Implicit GEMM Conv4. Implicit GEMM Conv优化5. spconv和Implicit GEMM Conv总结下载链接参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参

训练模型时Interal Error:Blas GEMM launch failed.
最近在跑毕业实验,遇到上述问题 原因: 30系显卡不支持 tensorflow 1.x,所以要使用 Nvidia 维护的 [nvidia-tensorflow] NVIDIA/tensorflow: An Open Source Machine Learning Framework for Everyone (github.com) 需要运行下列命令 pip install --us
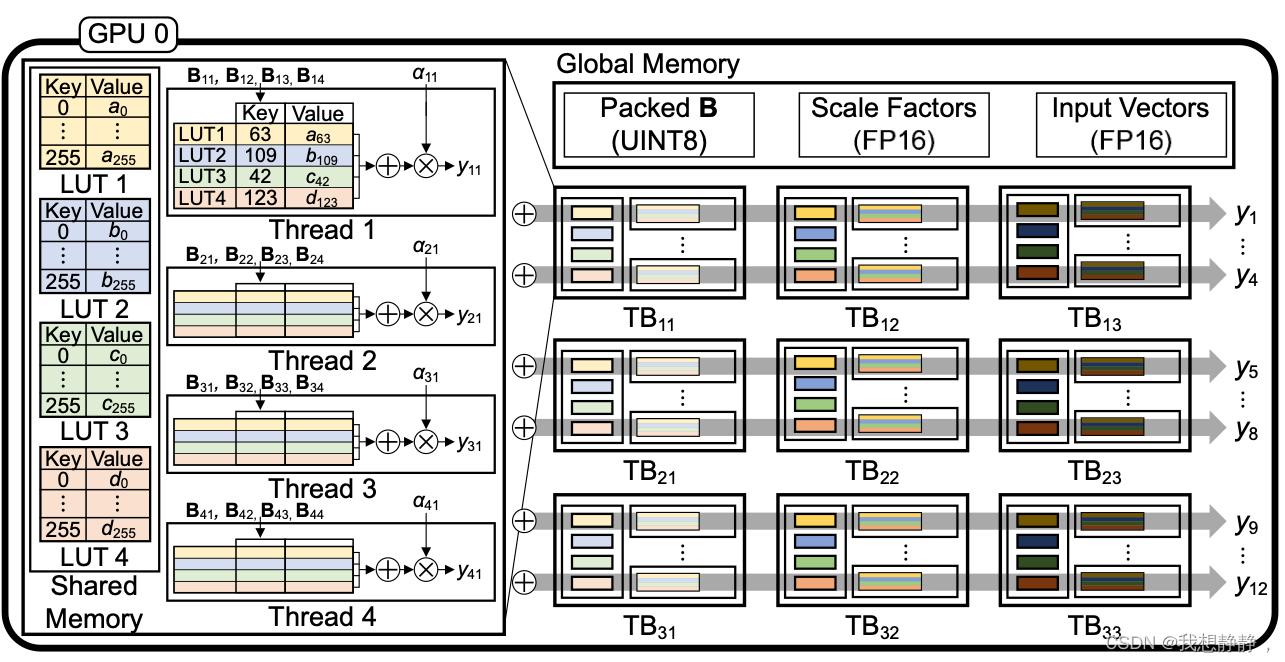
LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Gener
文章目录 abstractintroduction背景量化二值量化BCQ LUT-GEMM二值量化扩展Group-wise 𝛼分配基于LUT的量化矩阵乘法LUT-GEMM内存占用 实验Simple Comparisons with Various KernelsComparison with FP16 Tensor ParallelismExploration of Compressio