本文主要是介绍发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- [发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解](https://cyj666.blog.csdn.net/article/details/138514145)
- 先来看一下最简单的`struct GemmIdentityThreadblockSwizzle`结构体
发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解
- 在CSDN著名文章发表博客之:cutlass demo讲解,在sm75机器上用cuda core计算fp32矩阵乘!深入理解cutlass::gemm::device::Gemm类 ,感兴趣的老乡别走开!!里面我们介绍了
cutlass::gemm::device::Gemm的使用方式,以及这个模版类的一些参数,里面有一个模版参数叫ThreadblockSwizzle,并且当时他还有一个默认值typename threadblock::GemmIdentityThreadblockSwizzle<>,,不知道各位看官是否还记得,现在我要告诉你这个模版参数的准确作用!开心吗?
- 首先这个文件的github地址是cutlass/gemm/threadblock/threadblock_swizzle.h
- 我们知道,cuda 处理问题都是将一个很大规模的问题分成很多个小问题,每个小问题由一个ThreadBlock来处理,而
ThreadblockSwizzle就是负责将逻辑上的小问题映射到cuda上的ThreadBlock上。 - 或者直接引用这个文件上的注释吧!
Implements several possible threadblock-swizzling functions mapping blockIdx to GEMM problems.
先来看一下最简单的struct GemmIdentityThreadblockSwizzle结构体
- 这个结构体有一个默认参数是1。
template <int N = 1>
struct GemmIdentityThreadblockSwizzle {CUTLASS_HOST_DEVICEGemmIdentityThreadblockSwizzle() { }/// Returns the shape of the problem in units of logical tiles/// *Gemm* problem size: gemm(M, N, K)/// 这个函数的作用是简单的。/// 就是以tile_size为逻辑单元,整个问题的逻辑shape!CUTLASS_HOST_DEVICEstatic GemmCoord get_tiled_shape(GemmCoord problem_size,GemmCoord tile_size,int split_k_slices) {return GemmCoord((problem_size.m() + tile_size.m() - 1) / tile_size.m(),(problem_size.n() + tile_size.n() - 1) / tile_size.n(),split_k_slices);}/// Returns the shape of the problem in units of logical tiles/// *ImplicitGemm* Conv2d problem size: conv_operator(NPQK, NHWC, KRSC)CUTLASS_HOST_DEVICEstatic GemmCoord get_tiled_shape(cutlass::conv::Operator conv_operator,cutlass::conv::Conv2dProblemSize const &problem_size,GemmCoord tile_size,int split_k_slices) {gemm::GemmCoord implicit_gemm_problem_size = cutlass::conv::implicit_gemm_problem_size(conv_operator, problem_size);return get_tiled_shape(implicit_gemm_problem_size, tile_size, split_k_slices);}/// Returns the shape of the problem in units of logical tiles/// *ImplicitGemm* Conv3d problem size: conv_operator(NZPQK, NDHWC, KTRSC)CUTLASS_HOST_DEVICEstatic GemmCoord get_tiled_shape(cutlass::conv::Operator conv_operator,cutlass::conv::Conv3dProblemSize const &problem_size,GemmCoord tile_size,int split_k_slices) {gemm::GemmCoord implicit_gemm_problem_size = cutlass::conv::implicit_gemm_problem_size(conv_operator, problem_size);return get_tiled_shape(implicit_gemm_problem_size, tile_size, split_k_slices);}/// 这个函数是获得物理shape!也就是三对三对<<<>>>下的grid_shape!/// Computes CUDA grid dimensions given a size in units of logical tilesCUTLASS_HOST_DEVICEstatic dim3 get_grid_shape(GemmCoord tiled_shape) {int tile = 1 << get_log_tile(tiled_shape);return dim3(tiled_shape.m() * tile, (tiled_shape.n() + tile - 1) / tile, tiled_shape.k());}
- 下面的这个函数来获得最好的
get_log_tile!
/// 这个是防止函数是防止逻辑shape上的n过大,导致grid的第2维过大!/// Calculates optimal swizzle widthCUTLASS_HOST_DEVICEstatic int get_log_tile(GemmCoord tiled_shape) {auto n = tiled_shape.n();// Thresholds picked so that it doesn't cause too many no-op CTAsif (N >= 8 && n >= 6)return 3;else if (N >= 4 && n >= 3)return 2;else if (N >= 2 && n >= 2)return 1;elsereturn 0;}
- 下面两个函数是同一个名字,get_tile_offset,但是参数不同。
- 他们的共同作用根据物理id是获取
逻辑上Tile的偏移量!
- 他们的共同作用根据物理id是获取
- 但是第二个函数好像很少用到的样子!
/// Obtains the threadblock offset (in units of threadblock-scoped tiles)CUTLASS_DEVICEstatic GemmCoord get_tile_offset(int log_tile) {int block_idx_x = RematerializeBlockIdxX();int block_idx_y = RematerializeBlockIdxY();int block_idx_z = RematerializeBlockIdxZ();return GemmCoord{(block_idx_x >> log_tile), //(block_idx_y << log_tile) + ((block_idx_x) & ((1 << (log_tile)) - 1)),block_idx_z};}/// Obtains the threadblock offset (in units of threadblock-scoped tiles)CUTLASS_DEVICEstatic GemmCoord get_tile_offset(GemmCoord tiled_shape) {int const kTile = N;int block_idx_x = RematerializeBlockIdxX();int block_idx_y = RematerializeBlockIdxY();if ((tiled_shape.m() < kTile) || (tiled_shape.n() < kTile))return GemmCoord{block_idx_x, block_idx_y, RematerializeBlockIdxZ()};return GemmCoord{(block_idx_x / kTile),(block_idx_y * kTile) + (block_idx_x % kTile),RematerializeBlockIdxZ()};}
};
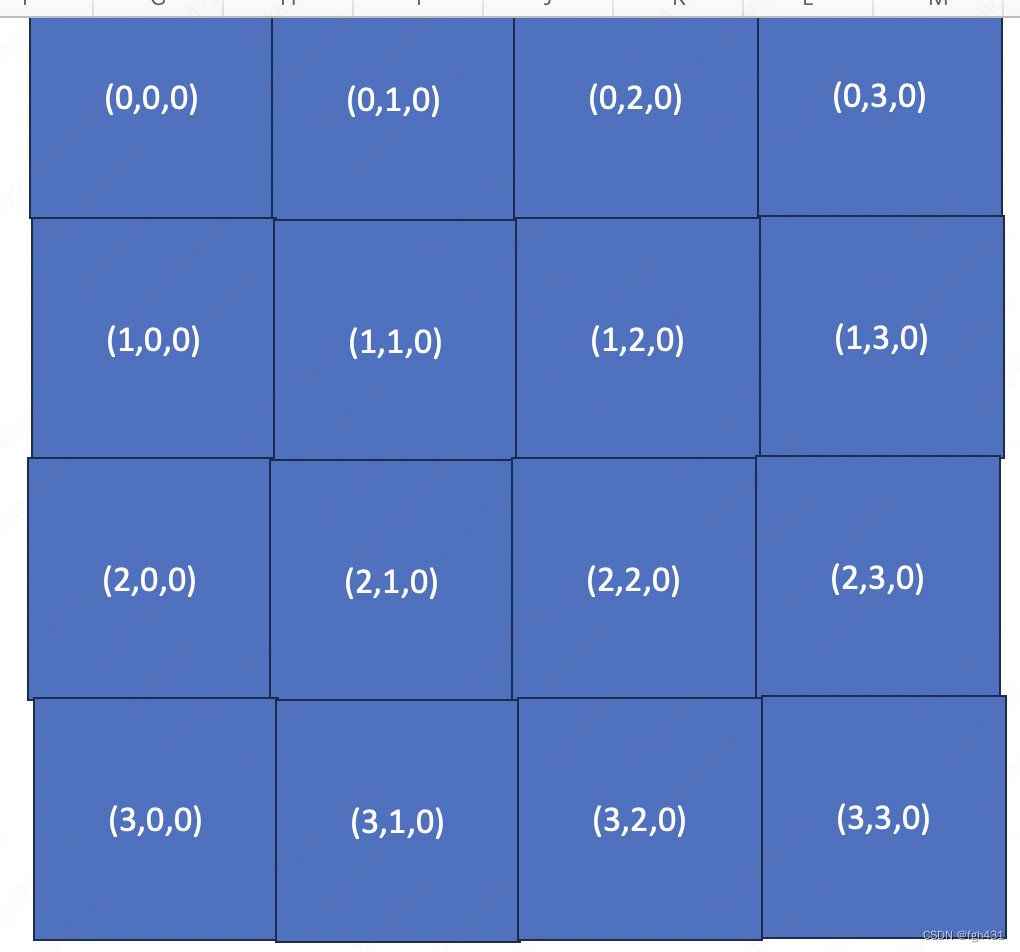
- 举个例子,假设N=1,并且 C C C输出矩阵被分成下面这样的逻辑shape,
- 那么三对<<<>>>发射的grid就是(4,4,1)!
- 那么每个Tile被映射到的ThreadBlock id如下图所示。
-
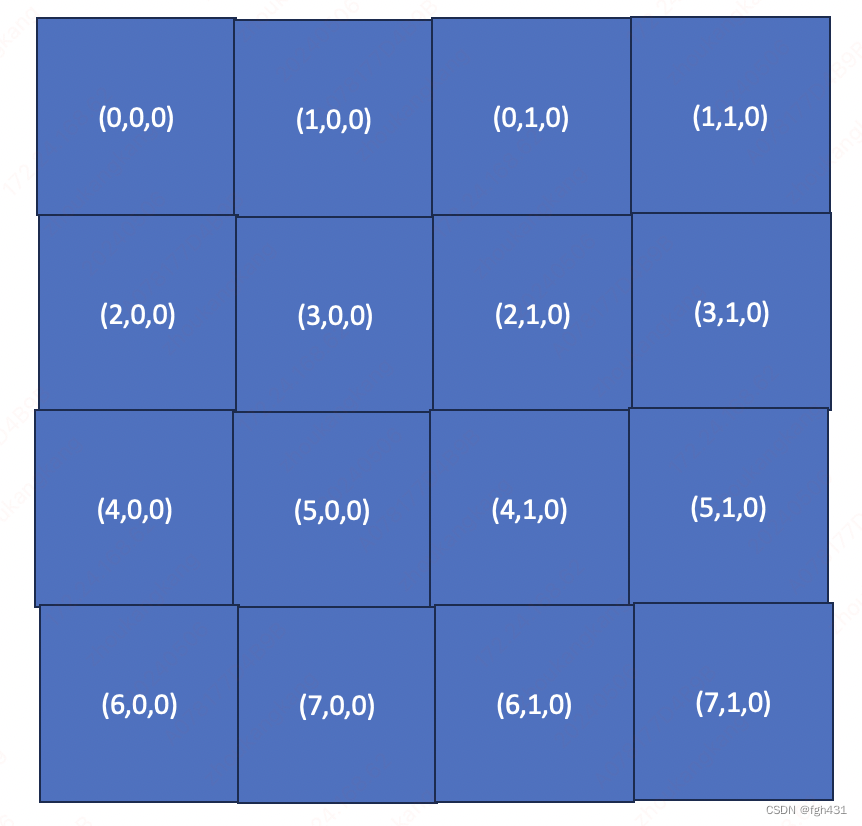
如果 N = 2 N=2 N=2,
-
那么三对<<<>>>发射的grid就是(8,2,1)!
-
那么每个Tile被映射到的ThreadBlock id如下图所示。
这篇关于发表博客之:gemm/threadblock/threadblock_swizzle.h 文件夹讲解,cutlass深入讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



