fp32专题
人工智能算力FP32、FP16、TF32、BF16、混合精度解读
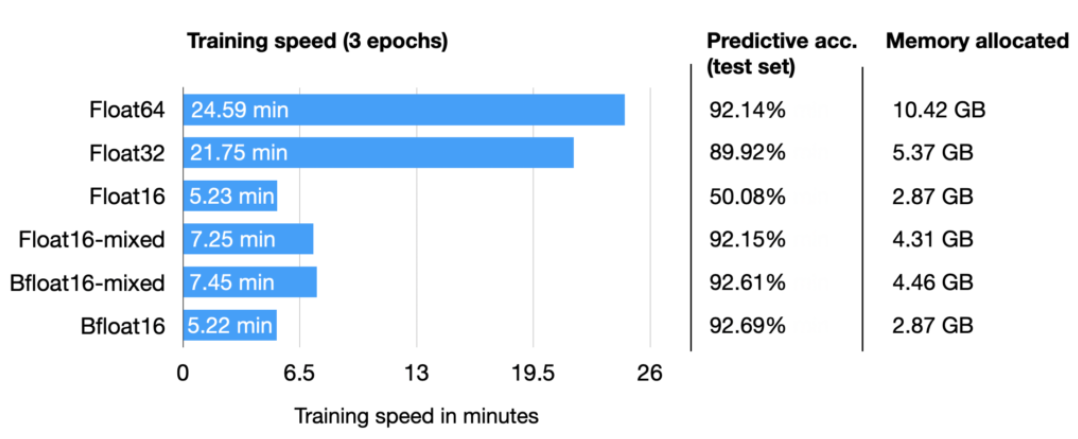
彻底理解系列之:FP32、FP16、TF32、BF16、混合精度 随着大模型的涌现,训练和推理速度成为关键。为提升速度,需减小数据长度以降低存储和带宽消耗。为此,我专注学习并整理了各种精度细节,确保深入理解而非浅尝辄止。 1 从FP32说起 计算机处理数字类型包括整数类型和浮点类型,IEEE 754号标准定义了浮点类型数据的存储结构。

train_gpt2_fp32.cu - layernorm_forward_kernel3
源码 __global__ void layernorm_forward_kernel3(float* __restrict__ out, float* __restrict__ mean, float* __restrict__ rstd,const float* __restrict__ inp, const float* __restrict__ weight,const float*

train_gpt2_fp32.cu
源程序 llm.c/test_gpt2_fp32.cu at master · karpathy/llm.c (github.com) #include <stdio.h>#include <stdlib.h>#include <math.h>#include <time.h>#include <assert.h>#include <float.h>#include <string

TensorRT custom_op注册 fp16及fp32相关问题
为什么fp16比fp32慢? 根据nvidia官方的说法,正好我的显卡是1070,所以出现了该问题.找不到正确的重载函数 这个问题没有找到原因,个人感觉还是跟编译器有关,因为同样的代码在Tx2上可以正常编译,在这里还请知道的朋友不吝指教.根据我的经验有两种解决思路: 1).改变写法,避开重载函数.2).指定重载函数类型,但这样会略微影响速度.记得确认自己的GPU_ARCHS,很多时候莫名奇妙的cu

模型精度fp16和fp32
FP16和FP32是两种不同的浮点数精度格式,在计算机科学特别是深度学习领域中广泛应用。 FP32(单精度浮点数): FP32代表32位(4字节)单精度浮点数格式,这是传统上大多数深度学习模型训练和推理的标准精度格式。它提供了大约7个有效数字的精度,并具有较大的动态范围(从约1.2e-38到约3.4e38)。由于更高的精度,它能够更好地捕捉较小的数值变化,对于复杂的深度学习模型中的梯度计算非常

nvidia tf32格式的意义是啥?和fp32的区别
nvidia tf32格式的意义是啥?:https://www.zhihu.com/question/545977619 作者:丽台科技 链接:https://www.zhihu.com/question/545977619/answer/2629134304 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 TF32(TensorFloat32)是NVIDIA
Onnx精度转换 FP32->FP16
Onnx精度转换 FP32->FP16 1、依赖包 onnxonnxmltools 2、转换 from onnxmltools.utils.float16_converter import convert_float_to_float16from onnxmltools.utils import load_model,save_modelonnx_model = load_model("