efficientvit专题
4.18.2 EfficientViT:具有级联组注意力的内存高效Vision Transformer
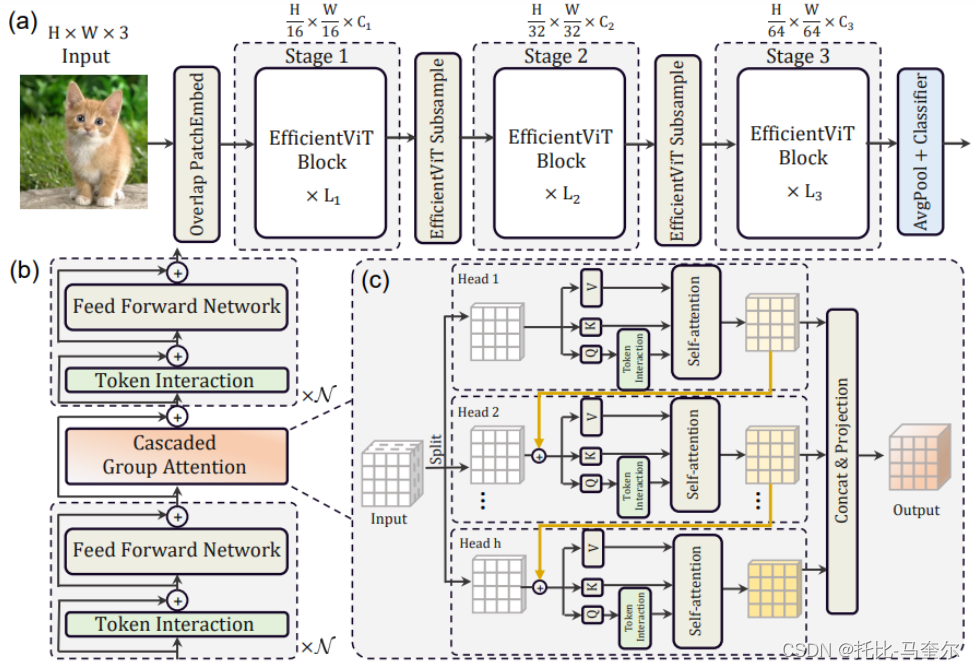
现有Transformer模型的速度通常受到内存低效操作的限制,尤其是MHSA(多头自注意力)中的张量整形和逐元素函数。 设计了一种具有三明治布局的新构建块,即在高效FFN(前馈)层之间使用单个内存绑定的MHSA,从而提高内存效率,同时增强通道通信。 注意力图在头部之间具有高度相似性,导致计算冗余。 为了解决这个问题,提出了一个级联的组注意力模块,为注意力头提供完整特征的不同分割。
YOLOv5改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍 本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是'EfficientViT: Multi-Scale Linear Attention for High-

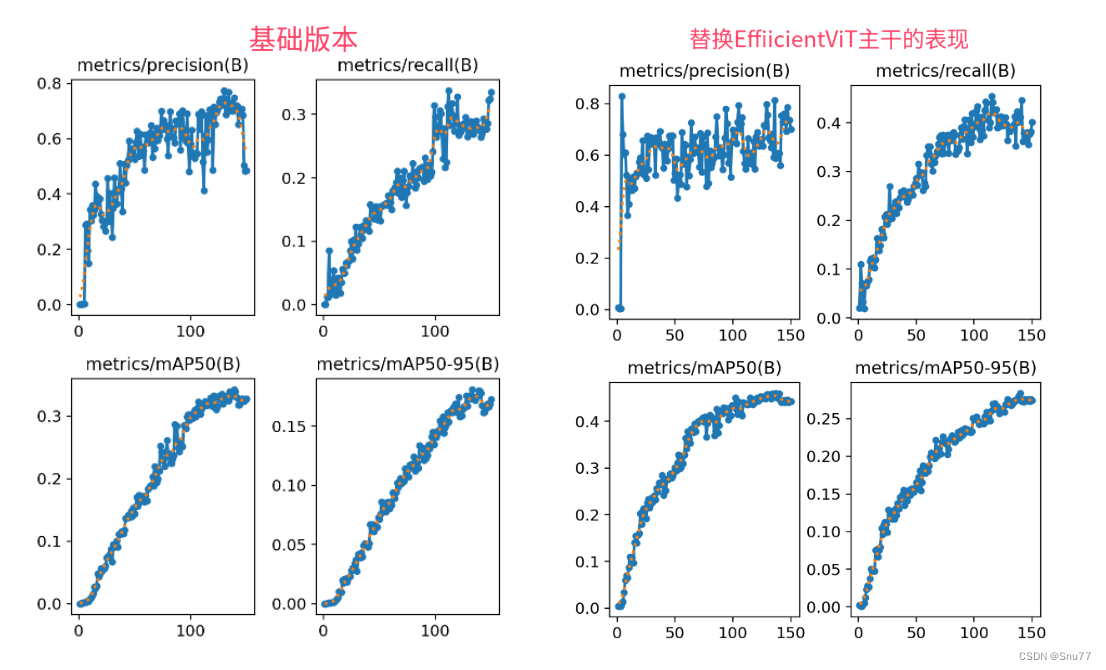
YOLOv8算法改进【NO.86】将主干特征网络替换为2023年顶会CVPR的EfficientViT,助力SCI论文发表
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具有有需求可以私信我沟通: 第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,

YOLOv8改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍 本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是'EfficientViT: Multi-Scale Linear Attention for High-R
EfficientViT: 高效视觉transformer与级联组注意力
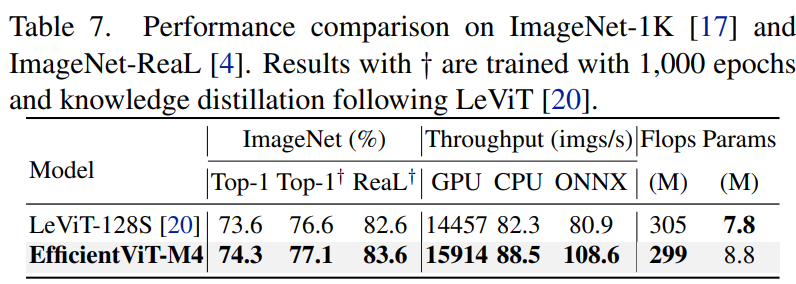
文章目录 摘要1、简介2、用视觉transformer加速2.1. 内存效率2.2. 计算效率2.3. 参数效率 3、高效视觉Transformer3.1、EfficientViT的构建块3.2、EfficientViT网络架构 4、实验4.1、实现细节4.2、ImageNet上的结果4.3、迁移学习结果4.4、 消融实验 5、相关工作6、结论 摘要 2305.07027.pdf

YOLOV8改进:CVPR2023:加入EfficientViT主干:具级联组注意力的访存高效ViT
1.该文章属于YOLOV5/YOLOV7/YOLOV8改进专栏,包含大量的改进方式,主要以2023年的最新文章和2022年的文章提出改进方式。 2.提供更加详细的改进方法,如将注意力机制添加到网络的不同位置,便于做实验,也可以当做论文的创新点。 2.涨点效果:添加EfficientViT,有效涨点。 论文地址 视觉变压器由于其高模型能力而取得了巨大的成功。然而,它们卓越的性能伴随着沉重的
EfficientViT: 高效视觉transformer与级联组注意力
文章目录 摘要1、简介2、用视觉transformer加速2.1. 内存效率2.2. 计算效率2.3. 参数效率 3、高效视觉Transformer3.1、EfficientViT的构建块3.2、EfficientViT网络架构 4、实验4.1、实现细节4.2、ImageNet上的结果4.3、迁移学习结果4.4、 消融实验 5、相关工作6、结论 摘要 2305.07027.pdf