disagreement专题
Self-Supervised Exploration via Disagreement论文笔记
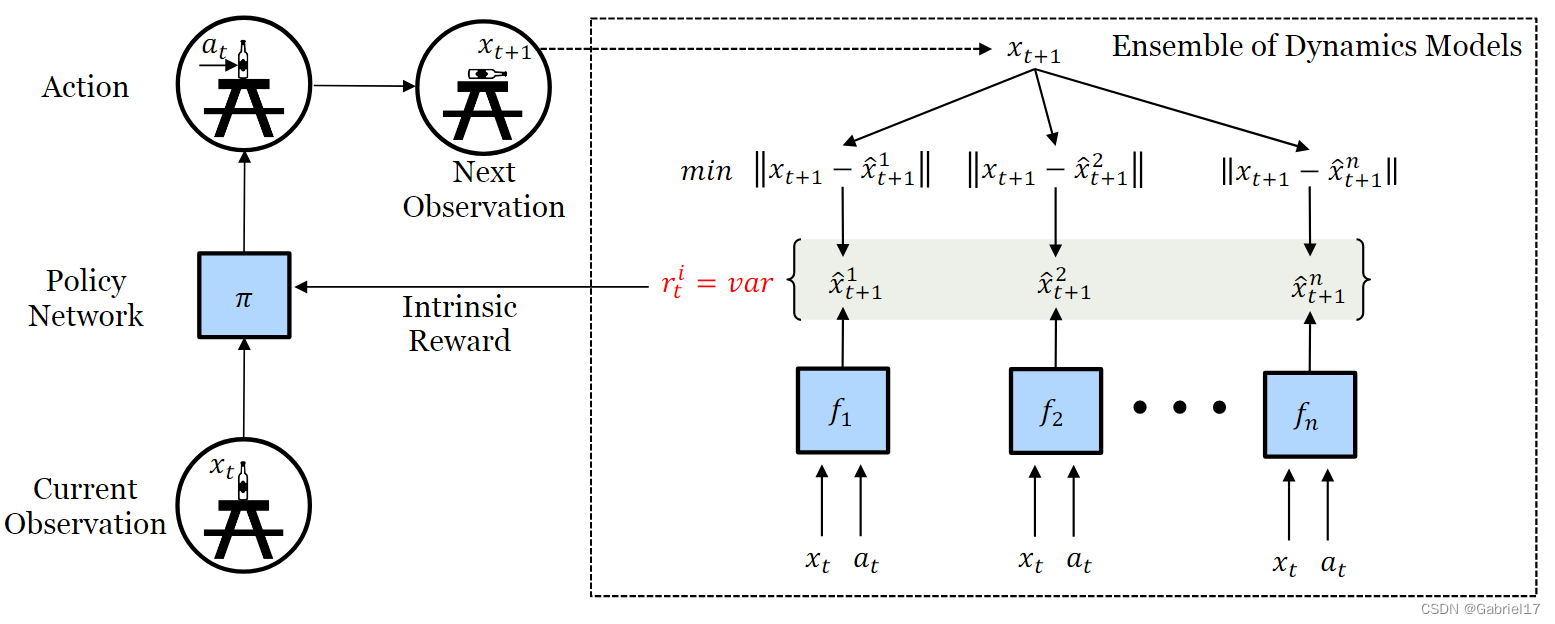
通过分歧进行自我监督探索 0、问题 使用可微的ri直接去更新动作策略的参数的,那是不是就不需要去计算价值函数或者critic网络了? 1、Motivation 高效的探索是RL中长期存在的问题。以前的大多数方式要么陷入具有随机动力学的环境,要么效率太低,无法扩展到真正的机器人设置。 2、Introduction 然而,在学习无噪声模拟环境之外的预测模型时,有一个关键的挑战:如何处理代理