deterministic专题

torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms总结学习记录
经常使用PyTorch框架的应该对于torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms这两个语句并不陌生,在以往开发项目的时候可能专门化花时间去了解过,也可能只是浅尝辄止简单有关注过,正好今天再次遇到了就想着总结梳理一下。 torch.backends.cudnn.benchmark 是 PyTorch 中的一个设置
(转)This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its de 错误解决办法
【转载原因:mysql创建函数,报错,参考可以解决】 【转载原文:https://www.cnblogs.com/kiko2014551511/p/11527423.html】 1. 创建函数时报错信息 执行创建函数的sql语句时,提示:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its dec

【PyTorch】torch.backends.cudnn.benchmark 和 torch.backends.cudnn.deterministic
1. torch.backends.cudnn.benchmark 在 PyTorch 中,torch.backends.cudnn.benchmark 是一个配置选项,用于在运行时自动选择最优的卷积算法,以提高计算效率。这个设置特别针对使用 CUDA 和 cuDNN 库进行的运算,并在使用具有变化输入尺寸的网络时有很大帮助。让我们更详细地解释这个设置的功能和应用场景。 什么是 cuDNN?
函数索引 ORA-30553: The function is not deterministic 解决方法
建函数索引的时候报错:ORA-30553: The function is not deterministic, 这个函数是自定义的。 SQL>create index mobileIndex on mobile(getmobilearea (callerno)); Google 一下: ORA-30553: The function is not deterministi

强化学习(五)-Deterministic Policy Gradient (DPG) 算法及公式推导
针对连续动作空间,策略函数没法预测出每个动作选择的概率。因此使用确定性策略梯度方法。 0 概览 1 actor输出确定动作2 模型目标: actor目标:使critic值最大 critic目标: 使TD error最大3 改进: 使用两个target 网络减少TD error自举估计。 1 actor 和 critic 网络 确定性策略网络 actor: a= π ( s ; θ ) \p

mysql还原备份库函数报错:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration
报错信息: This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variab
sqlite3.NotSupportedError: deterministic=True requires SQLite 3.8.3 or higher
问题描述 sqlite3.NotSupportedError: deterministic=True requires SQLite 3.8.3 or higher 解决方法 A kind of solution is changing the database from sqlite3 to pysqlite3. After acticate the virtualenv, instal
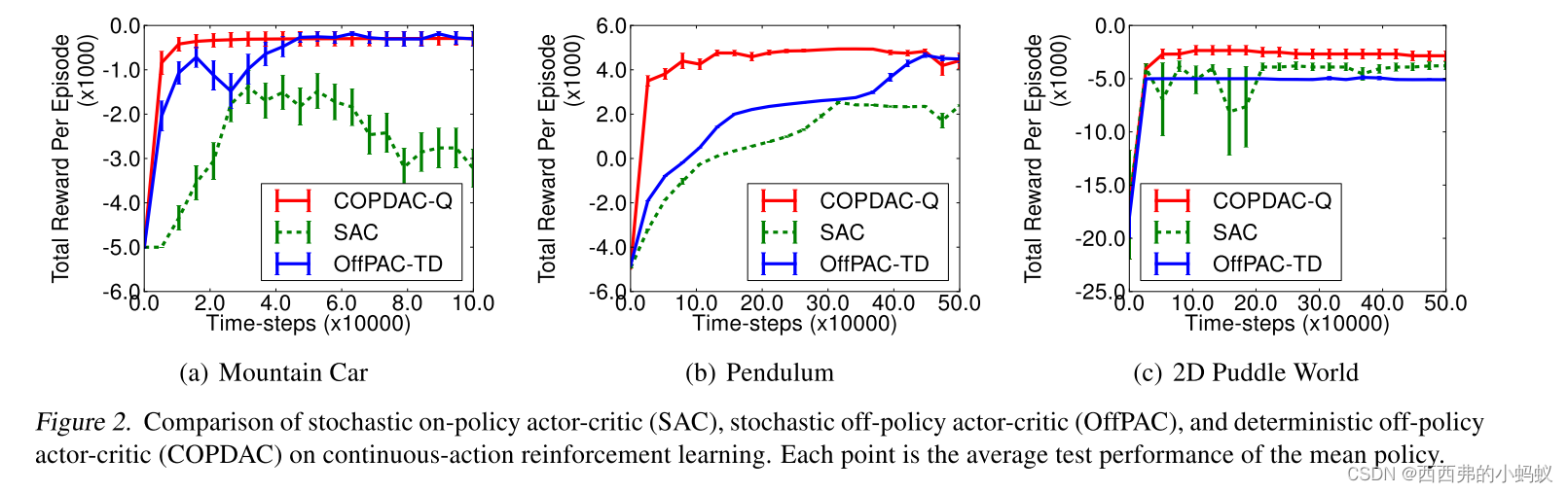
Deterministic Policy Gradient Algorithms
本文研究具有连续动作的确定性策略梯度算法。确定性策略梯度有一种特别吸引人的形式:它是行动-价值函数的期望梯度。这种简单的形式意味着确定性策略梯度的估计比一般的随机政策梯度的估计要有效得多。为了确保充分的探索,我们引入了一种非策略行为-批评算法,该算法从探索行为策略中学习确定的目标策略。我们证明了确定性策略梯度算法在高维行为空间中可以显著优于随机算法。 背景: 1)策略梯度算法通常通过对该随机策

mysql 报错This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and
出错信息: Last_SQL_Error: Error 'This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_f