dataguard专题

每日一记:Oracle Dataguard定时清理从库已归档日志
作为一个合格的DBA,每次部署完DG,都应该考虑到后果,想想如果从库的归档满了该怎么办? 如果可以每天登陆服务器检查,那也是可以的。往往很多时候都会因没有及时清理归档,导致数据库出错。 那么,你需要以下这个脚本来帮你解决这个问题: #!/bin/bashoracle_sid=$1applied_days=$2dest_id=$3export ORACLE_SID=${oracle_s
![[Dataguard]ORA-16191: Primary log shipping client not logged on standby问题解决](/front/images/it_default.gif)
[Dataguard]ORA-16191: Primary log shipping client not logged on standby问题解决
今天朋友Dataguard备库无法同步主库的问题,大概场景如下: 1.备库startup,日志同步语句执行都没问题,但是备库就是无法同步主库的内容 2.观察了下备库的归档同步情况,发现都是0表示未同步主库数据过来,然后看了下警告日志文件的内容,发现如下问题 <msg time='2016-01-20T00:57:57.734+08:00' org_id='oracle' comp_id='r
[DGMGRL]Dgmgrl管理Dataguard(3) 草稿
Data Guard主从库之间的角色切换分为以下两种: 1)Switchover Swithchover通常都是人为的有计划的进行角色互换,比如升级等。它通常都是无损的,即不会有数据丢失。其执行主要分为两个阶段: 1.Primary转为Standby 2.Standby之一转为Primary 2)Failover Failover是指由于Primary故障无法短时间恢复,Standby不得不充
[DGMGRL]Dgmgrl管理Dataguard(2)
1.通过SQLPLUS关闭Dataguard数据库,查看DGMGRL中备库的状态 SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. --发现备库状态为disabled DGMGRL> show configuration Configuration - or
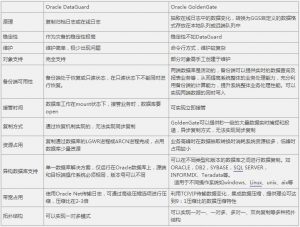
oracle ogg 和 DataGuard比较
一、复制方式 • Golden Gate 可提供秒一级的大量数据实时捕捉和投递,无法实现同步复制; • Data Guard 最大保护—Maximum protection 最大可用—Maximum availability 最大性能—Maximum performance 最大保护,最大可用模式都需要同步传输日志,此时会大大加重OracleLGWR或ARCH进程的工作量,严重影响源
Oracle双机/RAC/Dataguard的区别---来源于网上
DataGuard是Oracle的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,这是两套硬件配置可以不同的系统,但是这两套系统的软件结构保持一致,包括软件的版本,目录存储结构,以及数据的同步(其实也不是实时同步的),这两套系统之间只要网络是通的就可以了,是一种异地容灾的解决方案。而对于RAC,则是本地的高可用集群,每个节点用来分担不用或相同的应用,以解

DataGuard参数配置详解(转载)
DB_NAME 只需注意DataGuard的主备各节点instance使用相同的db_name即可。推荐与service_name一致。 Primary Site Standby Site*.DB_NAME='DB'*.DB_NAME='DB’ DB_UNIQUE_NAME Primary与Standby端数据库的唯一名字,设定后不可再更改。 注意: 如果主备db_unique_nam
rman备份搭建DataGuard
前期参数设置部分忽略,可参考其它文章介绍。1、从主库创建备库控制文件备份backup current controlfile for standby format '/home/oracle/standby_controlfile.bak';2、备份主库run{ allocate channel ch1 type disk;allocate channel ch2 type disk;

Oracle 11g dataguard介绍
最近没什么事,翻来Oracle Data Guard 的官方文档,借此将自己get到的信息做简单的翻译,鉴于Oracle专业知识以及英文水平有限,难免有误,欢迎批评指正 Oracle Data Guard主要用于企业数据的高可用、数据保护以及灾难恢复, Oracle Data Guard提供一套包括创建,维护、管理和监控一个或多个standby数据库的完整的服务,
ORACLE 11G 之DATAGUARD搭建物理standby
1 安装环境 在Primary库上安装数据库软件,并建监听和实例,在Standby库上安装数据库软件,并建监听,但不建实例。 Primary库 Standby库 操作系统 CentOS release 6.4 64位 CentOS release 6.4 64位 IP/主机名 192.183.3.17/nn 192.183.3.145/kk 数据库软件版本
Oracle DataGuard中的一些坑
Oracle DataGuard中的一些坑 知识0:SQL> 中alter set 设置变量值时注意用引号 '' , 否则会自动设置为大写。 知识1:Oracle数据库DB_NAME、SERVICE_NAME、SID、INSTANCE_NAME等区别 DB_NAME: ①是数据库名,长度不能超过8个字符,记录在datafile、redolog和control file中 ②在DataGu
DataGuard主备之间解决gap的步骤
DataGuard主备之间可能由于网络等原因,造成备库和主库之间的归档日志不一致,这样就产生了gap。 解决gap的步骤: 1.在备库获得gap的详细信息 2.将需要的归档日志从主库拷贝到备库 3.备库将归档日志注册,然后应用。 --备库alert日志提示gap详情 Media Recovery Waiting for thread 1 seque
DataGuard主备归档存在gap的处理办法
DataGuard主备之间可能由于网络等原因,造成备库和主库之间的归档日志不一致,这样就产生了gap。 解决gap的步骤: 1.在备库获得gap的详细信息 2.将需要的归档日志从主库拷贝到备库 3.备库将归档日志注册,然后应用。 --备库alert日志提示gap详情 Media Recovery Waiting for thread 1 seque
oracle11g dataguard完全手册3-failover active dataguard(完)
一般情况下执行failover都是主库已经game over。故障转移将备库转换为主库,但不把原主库(有故障,无法正常工作)切换为备库。当故障转移发生后,你必须重建主库,或者使用闪回数据库功能将主库回退到故障发生前,然后转换其为备库并启用日志应用。 执行failover有几个前提条件如下 1.执行failover的前提 (1)检查归档文件是否连续 查询待转换
Oracle dataguard failover实战
Oracle dataguard failover实战 操作步骤 备库: SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE FINISH FORCE; SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY; SQL> SHUTDOWN IMMEDIATE;
Dataguard中日志传输服务
Dataguard中日志传输服务 之前,原本已经尝试过配置oracle实例的逻辑和物理standby结构,并且做个一些role交换操作,可是由于昨天学习rman的部分命令时没留意,误删掉了primary DB上的所有归档日志,因为原来是在maximum protection模式下,standby DB上还存在archivel gap,结果之前搭建的standby实验环境彻底挂了,prima
insert append nologging 对Dataguard 影响 DG的同步修复
----Force Logging 对dataguard 没有影响,所以日志大小也没有多大影响 若是该库在有备库的状况下,由于主库的 nologging 插入操做不会生成 redo ,因此不会在备库上传输和应用,这会致使备库的数据出现问题。 在一个具备主备关系的主库上将 force_logging 设置为 nologging 模式,随后建立一张表,设置为 nologging 模式
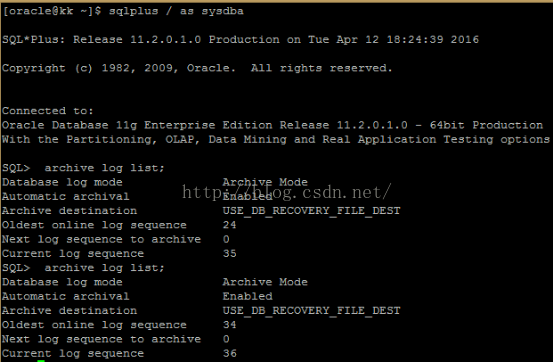
Oracle 12c dataguard查看主备库同步情况的新变化
导读 本文介绍Oracle 12c dataguard在维护方面的新变化 前提:主库备库的同步是正常的。 1、主库上查看archive Log list SYS@cdb1> archive log list;Database log mode Archive ModeAutomatic archival EnabledArchive

人大金仓 解决了金仓 KingbaseFlysync(KFS) 源端Oracle DataGuard备机解析update操作时,kufl中没有key值或key值不全的问题
关键字 KingbaseFlysync,KFS,Oracle,DataGuard,DG,redo,备机,有主键,无主键,update,没有key值,key值不全 问题描述 源端Oracle DataGuard在备机以redo的方式部署KFS,当源端对有主键的表执行update操作后,kufl中没有key值。 当源端对无主键表执行update操作后,kufl中的key值不全 问题分
mark: Oracle11gR2 RAC_primary+Single_standby dataguard部署
http://blog.csdn.net/lichangzai/article/details/7942422
使用rman duplicate创建物理active standby dataguard
11g的rman提供duplicate可以快速创建物理dataguard。简单方便,dataguard要求主库和备库的db_name一致,db_unique_name不同,下面是具体步骤 基本环境如下: 主库: hostname:11g1 ip:192.168.56.35 db_name:squan sid=squan db_unique_name=squan 备库:
手动搭建Dataguard步骤(同一服务器上physic standby)
(1)建立对应standby数据库的目录,如$ORACLE_BASE/admin,$ORACL_EBASE/oradata下的对应目录以及相关子目录,归档日志存放目录,闪回区存放路径等;创建密码文件。 mkdir /opt/oracle/admin/standbycd /opt/oracle/admin/standbymkdir adump bdump cdump udump dpdump m
Oracle 10gR2 (10.2.0.5) 3-Nodes RAC to Single Dataguard Switchover
Step By Step Configuring Oracle 10gR2 (10.2.0.5) 3-Nodes RAC to Single Dataguard DG配置参考上面链接。主库环境是3-nodes的 RAC,保证实例racdb1正常运行,关闭racdb2和racdb3实例。 备库至于mount状态。 [oracle@standby arch]$ sqlplus / as
Configuring Oracle 11.2.0.3 3-Nodes RAC Primary to 2-Nodes RAC Physical Standby DataGuard on OL
操作环境 Primary Standby Clusterware 11.2.0.3 Grid Infrastructure 11.2.0.3 Grid Infrastructure Cluster Nodes vzwc1,vzwc2,vzwc3(3-Nodes) sd-vzwc1,sd-vzwc2(2-Nodes) SCAN vzwc-cluster-scan sd
Oracle10g Logical DataGuard 详细搭建过程
logical standby是在physical standby基础上搭建 Oracle10g Physical DataGuard 详细搭建过程 --停止standby上的日志应用 SQL> alter database recover managed standby database cancel; Database altered. --修改主库log_a
DataGuard相关参数
DB_UNIQUE_NAME 定义数据库唯一名称,因为DB_NAME参数对于物理数据库是必须相同,对于逻辑数据库必须不同,所以在Oracle 10g中引入DB_UNIQUE_NAME参数来确定DataGuard配置中的每个数据库,如果未定义该参数,默认使用DB_NAME参数值。 LOG_ARCHIVE_CONFIG 定义DataGuard配置的有效DB_UNIQUE_NAME参数列表,