codellama专题
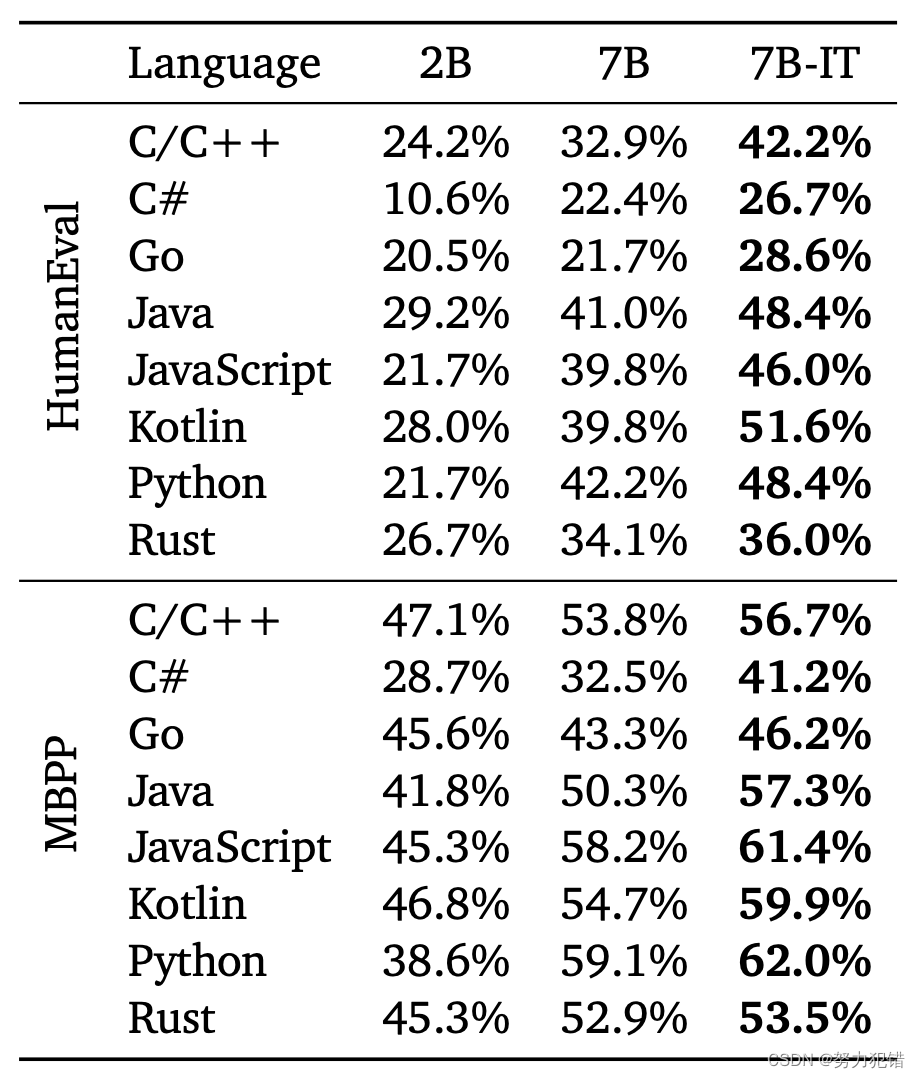
Google 发布 CodeGemma 7B,8K上下文,性能超CodeLlama 13B
CodeGemma简介 CodeGemma模型是谷歌的社区开放编程模型,专门针对代码领域进行优化。一系列功能强大的轻量级模型,能够执行多种编程任务,如中间代码填充、代码生成、自然语言理解、数学推理和指令遵循。CodeGemma模型是在大约500B个主要为英语、数学和代码的数据上进行了进一步训练,以提高逻辑和数学推理能力,适用于代码补全和代码生成编程任务。 Huggingface模型下载:ht

Google 发布 CodeGemma:7B 力压 CodeLLaMa-13B
刚刚发布!Google 带来了新的 Gemma 家族成员,CodeGemma,这是基于预训练的 Gemma-2B 和 Gemma-7B 的代码生成模型。 其上下文窗口长度为8K,在另外 500 B 个主要由英语、数学和代码组成的 token 上进行了训练,改进了逻辑和数学推理能力,适合代码生成任务。 GPT-3.5研究测试: https://hujiaoai.cn GPT-4研究测试: ht

多张卡部署一个codellama实例
模型推理过程 使用Transformers框架进行文本生成类任务会经过以下步骤: 加载预训练模型和tokenizer 主要涉及到网络传输(下载模型参数)、解压缩以及模型参数的初始化,这些过程通常是在 CPU 上执行 文本编码 对输入文本进行分词、转换为 token ID,并最终将 token ID 转换为 PyTorch 张量。这个过程不涉及模型参数的加载,也不需要进行模型的推理或训练,因
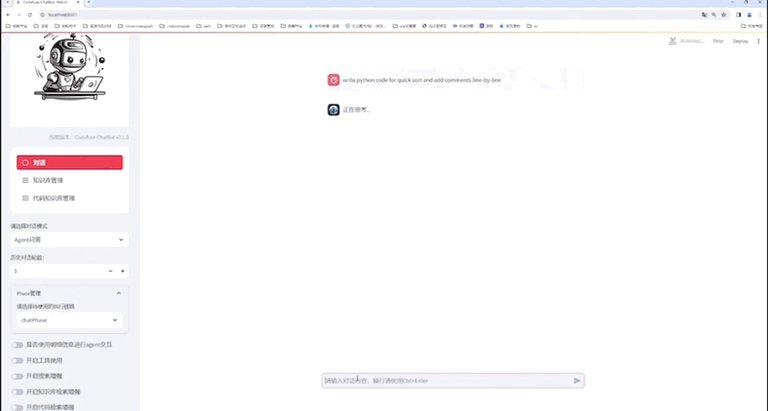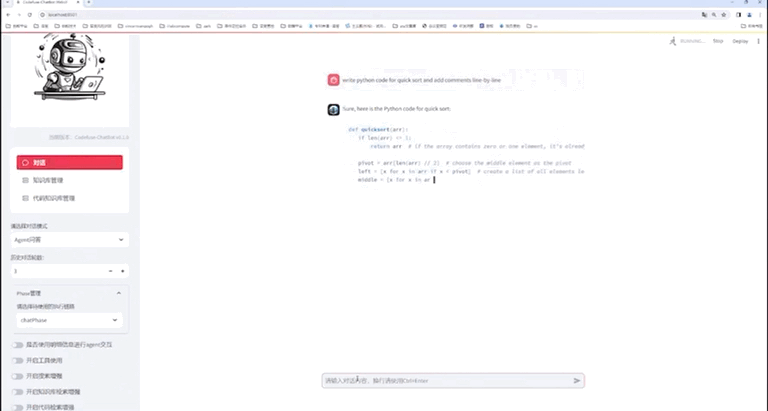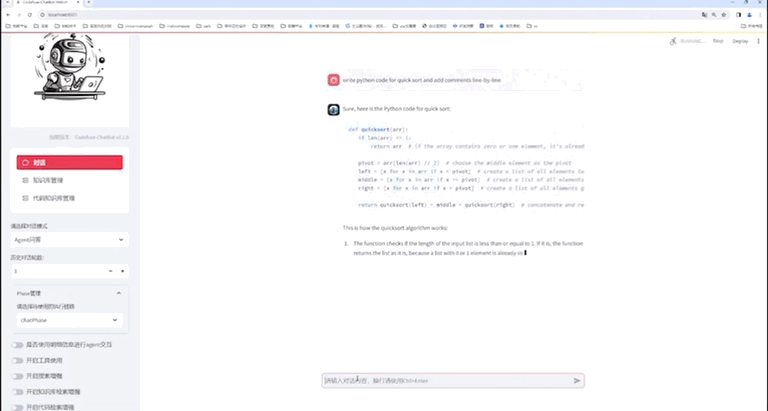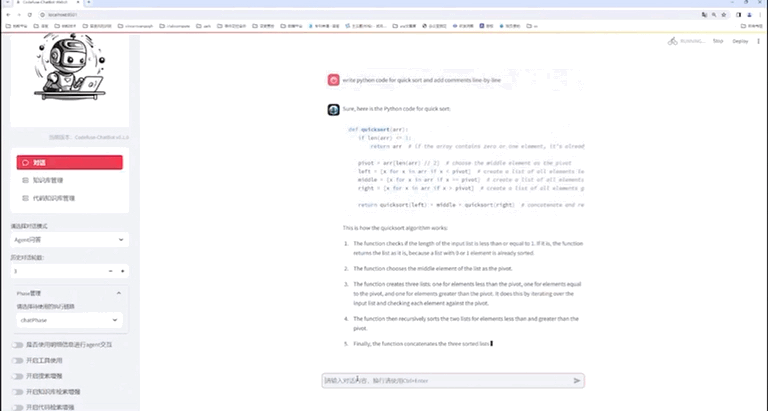
使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践
本文首发于 NVIDIA 一、概述 CodeFuse(https://github.com/codefuse-ai)是由蚂蚁集团开发的代码语言大模型,旨在支持整个软件开发生命周期,涵盖设计、需求、编码、测试、部署、运维等关键阶段。 为了在下游任务上获得更好的精度,CodeFuse 提出了多任务微调框架(MFTCoder),能够解决数据不平衡和不同收敛速度的问题。 通过
代码生成的原理解析:从Codex、GitHub Copliot到CodeLlama、CodeGeex
前言 本文精讲代码生成的发展史与其背后的技术原理,总计4个部分 第一部分 GitHub copilot的起源:Codex第二部分 微软GitHub copilot第三部分 Code Llama第四部分 CodeGeex 第一部分 GitHub copilot的起源:Codex 我们在这篇文章《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》中

国产DeepSeek Coder 33B开源:创新代码AI,性能优于CodeLlama
引言 近日,国产AI领域迎来了一项重大突破:DeepSeek团队正式发布了DeepSeek Coder 33B模型,这一基于最新人工智能技术的代码生成模型不仅完全开源,而且在多项评测中显示出优于同类产品CodeLlama的卓越性能。 Huggingface模型下载: https://huggingface.co/deepseek-ai AI快站模型免费加速下载: https://aifas
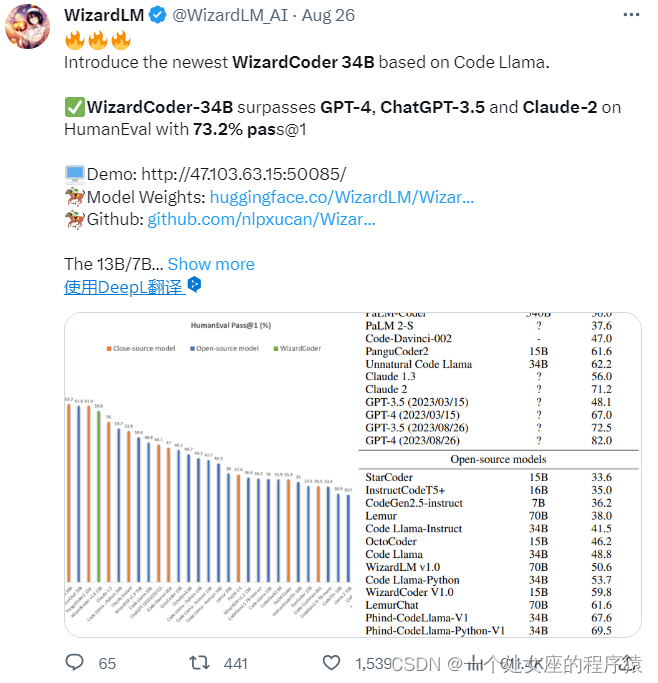
LLMs之Code:Code Llama的简介(衍生模型如Phind-CodeLlama/WizardCoder)、安装、使用方法之详细攻略
LLMs之Code:Code Llama的简介(衍生模型如Phind-CodeLlama/WizardCoder)、安装、使用方法之详细攻略 导读:2023年08月25日(北京时间),Meta发布了Code Llama,一个可以使用文本提示生成代码的大型语言模型(LLM)。Code Llama是最先进的公开可用的LLM代码任务,并有潜力使工作流程更快,更有效的为当前的开发人员和降低进入门槛