bs4专题


爬虫的bs4、xpath、requests、selenium、scrapy的基本用法
在 Python 中,BeautifulSoup(简称 bs4)、XPath、Requests、Selenium 和 Scrapy 是五种常用于网页抓取和解析的工具。 1. BeautifulSoup (bs4) BeautifulSoup 是一个简单易用的 HTML 和 XML 解析库,常用于从网页中提取数据。 它的优点是易于学习和使用,适合处理静态页面的解析。 安装 BeautifulS

python bs4解析网页时 bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: l
Python小白,学习时候用到bs4解析网站,报错 bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library? 1 几经周折才知道是bs4调用了python自带的html解析器,我用的ma

python-14(BS4解析网页)
目录 课前案例 Beautiful Soup 什么是Beautiful Soup 解析器 安装与配置 快速入门 解析数据 标签 属性 标签内容 遍历文档树 子节点 父节点 兄弟节点 搜索文档树 find find_all css选择器 3.综合案例 课前案例 通过requests模块爬取指定网站中的图片并保存到本地目录中。 import rei

代码-功能-Python-运用bs4技术爬取汽车之家新闻信息
第三方库安装指令: pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simplepip install BeautifulSoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 运行代码: #这个代码并不完整,有很大的问题,但目前不知道怎么改,就先这样吧!import r
ImportError: 没有模块命名BS4
Just tagging onto Balthazar's answer. Runningpip install BeautifulSoup4did not work for me. Instead usepip install beautifulsoup4 详情
python爬虫-bs4
python爬虫-bs4 目录 python爬虫-bs4说明安装导入 基础用法解析对象获取文本Tag对象获取HTML中的标签内容find参数获取标签属性获取所有标签获取标签名嵌套获取子节点和父节点 说明 BeautifulSoup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 在爬虫项目中经常会遇到不规范、及其复杂的HTML代码

躲在被窝里偷偷学爬虫(3)---bs4
bs4使用 注:bs4是python里面独有的数据解析! 首先要安装两个第三方库bs4和lxml,在dos窗口分别输入pip install bs4和pip install lxml回车片刻即完成! 一, 基本使用讲解 小编在本地写好一个简短的html练习文件 <!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><ti
Python3.6爬虫集合 xpath bs4 re 爬51job前程无忧招聘信息 豆瓣音乐等等
总结一下这两天自己写的爬虫,之前一直用框架爬虫,感觉有必要熟练最基础的没有框架爬虫才能让我更好理解框架,代码在链接内,代码中都有详细的注释 1. 发送邮件,这里选择发送网页邮件,其他邮件发送可以看廖雪峰老师的教程 * 邮件协议为SMTP,端口为25 * 需要模块 email(构造邮件) smtplib(发送邮件) * 代码传送门 * 无具体

BS4提取chrome.webdriver方法和属性以及描述并输出到Excel
BS4网络提取selenium.chrome.WebDriver类的方法及属性 chrome.webdriver: selenium.webdriver.chrome.webdriver — Selenium 4.18.1 documentation class selenium.webdriver.chrome.webdriver.WebDriver 是 Selenium 中用于操作 Chro
Python爬虫从入门到精通:(6)数据解析2_使用bs4(BeautifulSoup)_Python涛哥
使用bs4(BeautifulSoup) 数据解析的作用? 用来实现聚焦爬虫 网页中显示的数据都是存储在那里的? 都是存储在html的标签中或者是标签的属性中 数据解析的通用原理是什么? 指定标签的定位取出标签中存储的数据或者标签属性中的数据 bs4解析原理 实例化一个BeautifulSoup对象,且待解析的页面源码数据加载到该对象中调用BeautifulSoup对象中相关方法或者属性
Python BS4解析库用法(超级详解)
一.BS4简介 Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解,因此可以快速地学习并掌握 BS4 的基本语法。 官网中文文档 二.BS4下载安装 pip install bs4pip install lxml
爬虫入门三(bs4模块、遍历文档树、搜索文档树、css选择器)
文章目录 一、bs4模块二、遍历文档树三、搜索文档树四、css选择器 一、bs4模块 beautifulsoup4从HTML或XML文件中提取数据的Python库,用它来解析爬取回来的xml。 1.安装pip install beautifulsoup4 # 下载bs4模块pip install lxml #解析库2. 用法'第一个参数,是要总的字符串''第二个参数,
python爬取豆瓣影评,涉及知识点:bs4,requests、time、random
页面源代码: <!DOCTYPE html><html lang="zh-CN" class="ua-windows ua-webkit"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"><meta name="renderer" content="webkit"><meta name="re
ubuntu/linux pyhton3.x 安装pip、requests、bs4 BeautifulSoup4
安装pip sudo apt-get install python3-pip 安装requests sudo pip3 install requests --upgrade 安装BeautifulSoup4 sudo pip install BeautifulSoup4
从零开始写Python爬虫 -1.2 BS4库的安装与使用
Beautiful Soup库一般称为bs4库,支持Python3,是我们写爬虫非常好的第三方库。 bs4库的简单使用 假设我们需要爬取的HTML是如下这么一段: <html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p clas
BeautifulSoup,from bs4 import BeautifulSoup遇到python版本错误的解决办法
问题由来 换了台Windows环境,准备搭建Python学习环境。 OS:Windows 10 Python:3.7,从官网下载安装包,安装目录"C:\Users\Username\AppData\Local\Programs\Python\Python37" 安装Python3.7正常,下载安装BeautifulSoup正常(从官网下载压缩包,解压到D盘根目录(D:\beautifulsoup
ModuleNotFoundError No module named ‘bs4‘ 问题处理
ModuleNotFoundError: No module named ‘bs4’ 问题处理 在使用Postgres数据库时,因为SQL脚本中使用到了xml_killer函数,导致直接报错: org.postgresql.util.PSQLException: ERROR: ModuleNotFoundError: No module named ‘bs4’ 后来在网上搜索了一下,是因为p

【基础】【Python网络爬虫】【5.数据解析】bs4、Xpath、Parsel模块、正则表达式(附大量案例代码)(建议收藏)
Python网络爬虫基础 数据解析1. 为何数据解析2. 常见的数据类型结构化数据半结构化数据非结构化数据 3. 爬虫项目实现步骤 数据解析模块1. Bs4环境安装bs4解析流程案例 - bs4碧血剑文本爬取 2. Xpath环境安装xpath解析的编码流程xpath表达式如何理解?案例 - 简历模板下载案例 - 爬取空气质量数据网案例 - (彼岸图)图片数据爬取 3. Parsel 模
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: html5lib
使用BeautifulSoup的时候提示以下错误: bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: html5lib. Do you need to install a parser library? 解决方案: pip install html5lib
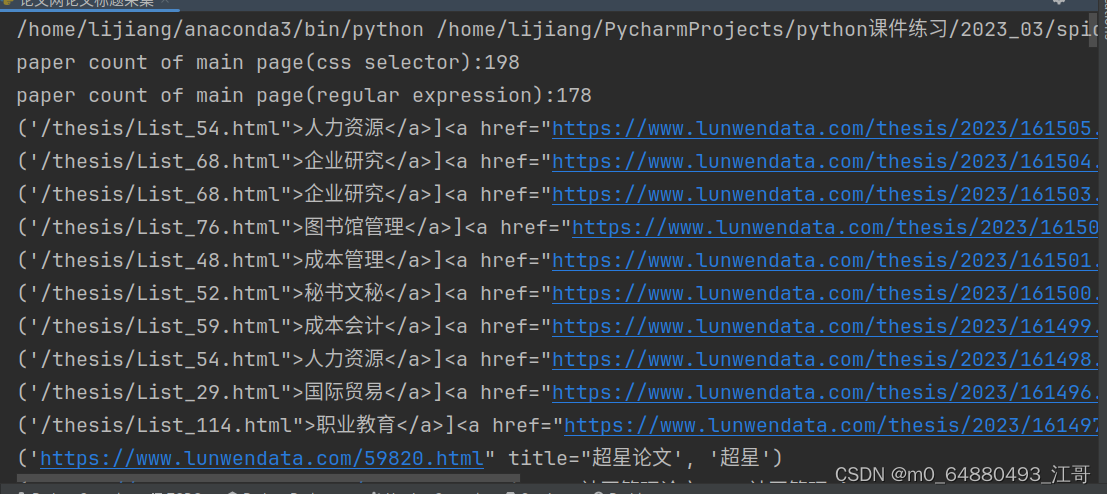
正则表达式与bs4选择器筛选论文数准确率之比较
一、正则爬取论文网首页论文标题的示例 import requestsimport refrom bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/83.0.4103

可狱可囚的爬虫系列课程 07:BeautifulSoup4(bs4)库的使用
前面一直在讲 Requests 模块如何使用,那都是在请求阶段要做的事情,相信很多网友都在等一个能够开始爬网站信息的教程,今天它来了,今天我要给大家讲一个很简单易懂的库:BeautifulSoup4。 一、概述&安装 BeautifulSoup4 属于 BeautifulSoup 系列的第四代版本,BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python

Python爬虫抓取气象_bs4+定时器+mysql+对象_一蓑烟雨任平生
文章目录 前言说啥呢?直接扔代码吧看不懂的话你细品 留言也可以 进群也可以 总结 前言 麻雀虽小 五脏俱全 这篇爬虫文章涉及的技术不少 bs4抓取数据 (之前一直用xpath感觉一种东西吃多了会腻) 定时器(一次执行终身执行 懒人必备) mysql(数据库 存数据的地方) 对象(面向对象编程) 说啥呢?直接扔代码吧 看不懂的话你细品 留言也可以 进群也可以 # -
爬虫解析-BeautifulSoup-bs4(七)
目录 1.bs4的安装 2.bs4的语法 (1)查找节点 (2)查找结点信息 3.bs4的操作 (1)对本地文件进行操作 (2)对服务器响应文件进行操作 4.实战 beautifulsoup:和lxml一样,是一个html的解析器,主要功能也是解析和提取数据。 优缺点: 缺点:没有lxml效率高 优点:接口更加人性化,使用方便 1
Python爬取京东评论(多线程+队列+bs4+pymysql)
1、 概述 本博客纯属原创,如有转载,请注明作者 运行环境:python3.5 所需模块:bs4 ,queue.thread,pymysql,requests,大家如果想运行此代码,只需要将我标粗的部分修改即可。 2、具体内容 2、1导入具体模块 ###导入具体模块import requestsfrom bs4 import BeautifulSoupimport refro
python解析html (bs4 lxml)
1. bs4 import bs4fp = open("test.html")#创建soup对象soup = bs4.BeautifulSoup(fp.read(),"lxml")#获取元素文本ele1 = soup.select("#site-name")print(ele1[0].getText())print(ele1[0].string)#将元素转为字符串print(str