bpe专题

自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词
BPE_tokenizer代码实现
import refrom collections import Counter# 导入 Counter 的示例(如果需要的话)class BytePairEncoder:def __init__(self):self.ws_token = "_"self.unk_token = "<UNK>"self.corpus = {}self.word_count = {}self.vocab = C
从零实现GPT【1】——BPE
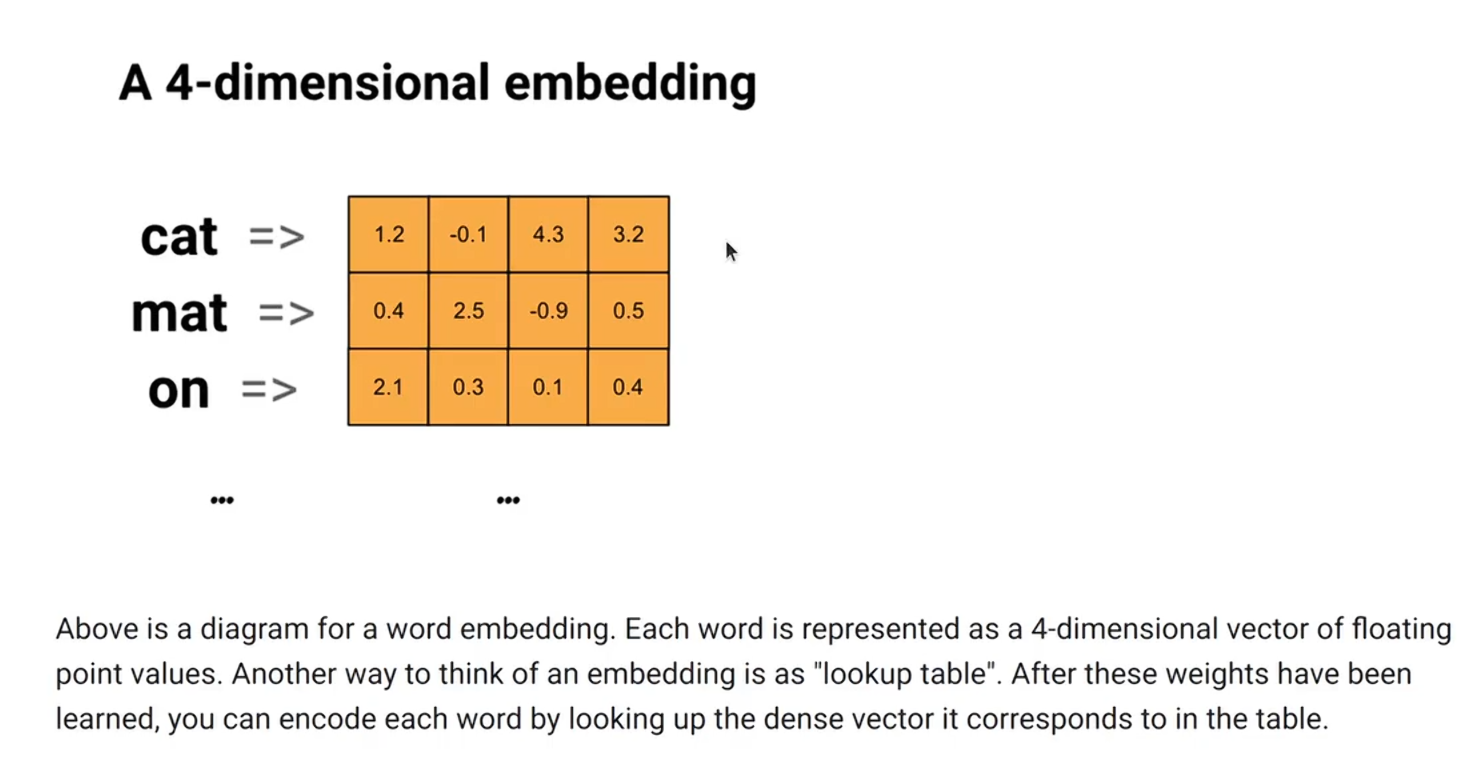
文章目录 Embedding 的原理训练特殊 token 处理和保存编码解码完整代码 BPE,字节对编码 Embedding 的原理 简单来说就是查表 # 解释embeddingfrom torch.nn import Embeddingimport torch# 标准的正态分布初始化 也可以用均匀分布初始化emb = Embedding(10, 32)res

Byte Pair Encoding(BPE)算法及代码笔记
Byte Pair Encoding(BPE)算法 BPE算法是Transformer中构建词表的方法,大致分为如下几个步骤: 将语料中的文本切分为字符统计高频共现二元组将共现频率最高的二元组合并加入词表重复上述第二和第三直到词表规模达到预先设置的数量,或没有可以合并的二元组为止 以GPT-2中BPE相关的代码为例对代码进行整理 完整代码如下所示 """BPE算法:字节对编码算法,将任

适合多种语言的BPE(Byte-Pair Encoding)编码
文章目录 前言BPE参考 前言 因为最近在看T5,里面讲到一些分词的方法如BEP,因为现在都是在玩大模型,那么语料也就都很大,而且还需要适配不同的语言,而不同的语言又不一定像英文那样按空格切分就行,例如咱们的中文,所以就需要一些适用性更广的方法了。 不仅如此,当我们遇到未知词汇时,如果使用常规的词汇表,那么未知词汇通常为 < UNK >,此时未知词汇之间就没有任何区分,而如果我

随机分词与tokenizer(BPE->BBPE->Wordpiece->Unigram->sentencepiece->bytepiece)
0 tokenizer综述 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后

【深度学习】sentencepiece工具之BPE训练使用
为什么要使用BPE,BPE是什么 BPE:迭代的将字符串里出现频率最高的子串进行合并 训练过程 使用教程 代码使用的语料在这里 # -*- coding: utf-8 -*-#/usr/bin/python3import osimport errnoimport sentencepiece as spmimport reimport logginglogging.basicC
[nlp] RuntimeError: Llama is supposed to be a BPE model!报错解决
# tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL) 改成这个legacy=False, use_fast=False: tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL, legacy=False, use_fast=False)