bloomberg专题

Bloomberg python API 获取历史数据
Bloomberg python API 获取历史数据 https://www.bloomberg.com/professional/support/api-library/ 把这个路径加入到环境变量的Path中。 然后安装下面的包 python -m pip install –index-url=https://bloomberg.bintray.com/pip/simple blpa
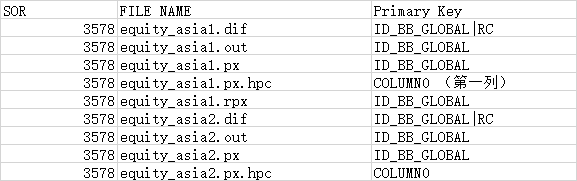
bloomberg bulkfile 在oracle的存储
文章导航 bloomberg bulkfile 的分类bloomberg bulkfile 在oracle的存储 一 表名和字段名称的命名规则 1.1. 表名以文件名称直接命名,将文件名中的"."用“_"代替。 如《fundamentals_namr_af_history.out》对应表名为:FUNDAMENTALS_NAMR_AF_HISTORY_OUT 1.2. 字段中特殊字段的处理规

python爬虫爬取Bloomberg新闻
最近在爬取bloomberg上的新闻,所以在这里记录一下过程。 思路 通过网站的sitemap获取链接,解析链接通过scrapy框架爬取。 网站链接的获取: https://www.bloomberg.com/robots.txt 这是网站的robots.txt,如下: # Bot rules:# 1. A bot may not injure a human being
Extract Mass Data Via Bloomberg API
个人博客地址 https://mengjiexu.com/post/bloomberg-api/ Motivation Bloomberg has integrated massive data from various of data vendors. However, as a typical finance terminal designed for traders, it’s tech