文章导航
- bloomberg bulkfile 的分类
- bloomberg bulkfile 在oracle的存储
一 表名和字段名称的命名规则
1.1. 表名以文件名称直接命名,将文件名中的"."用“_"代替。
如《fundamentals_namr_af_history.out》对应表名为:FUNDAMENTALS_NAMR_AF_HISTORY_OUT
1.2. 字段中特殊字段的处理规则
去接去除字段中的"&","%","/" 例外情况:对于最后一个"%" 用"PRE"替换.因为它代表百分比的含义,bb文件中会同时有xxx和xxx_%这样的field它们是不同的字段。
将"-" 替换为"_"
1.3. 以数字开头字段的字段处理规则
在字段前面加上”H_"
1.4.将连续的"_"只保留一个,且去除开头和结尾的"_"
如 "__ab__cd_" 替换为:"ab_cd"
1.5.长度截取,前24位+后6位
当表名或字段名称处理后长度仍超出30(oracle的最大限制).按规则截取:前面取24位,后面取6位。
如表名:FUNDAMENT ALS_NAMR_AF_HISTORY_OUT 截取后的表名为:FUNDAMENTALS_NAMR_AF_HISRY_OUT
二 创建表结构
2.1. 导入bulkfile文件解析字段
根据bloomberg 下载的文件中 START-OF-FIELDS END-OF-FIELDS 之间的部分即为表的列名,将文件名按命名规则存储为表名。解析出来的表名和字段及字段顺序最终会存在BB_TABLES中的BB_table_name,bb_field_name,field_order中
CREATE TABLE BB_TABLES( TABLE_NAME varchar2(200), --表名(oracle) FIELD_NAME varchar2(200), --字段名(oracle) BB_field_Name varchar2(200), --bloomberg的字段名称 BB_table_name varchar2(200), --bloomberg的表名(对应名称的名称. .xxx替换为_xxx)
FIELD_ORDER number(4) --字段的排序(要与文件中的顺序相同) )
将解析出来的数据先临时导入到BB_TABLES 的bb_table_name及bb_field_name中
2.2 导入《Harvest Bulk File Field Layout.xlsx》中的字段信息
2.2.1 导入sheet:5115-part I
sheet 内容如下:
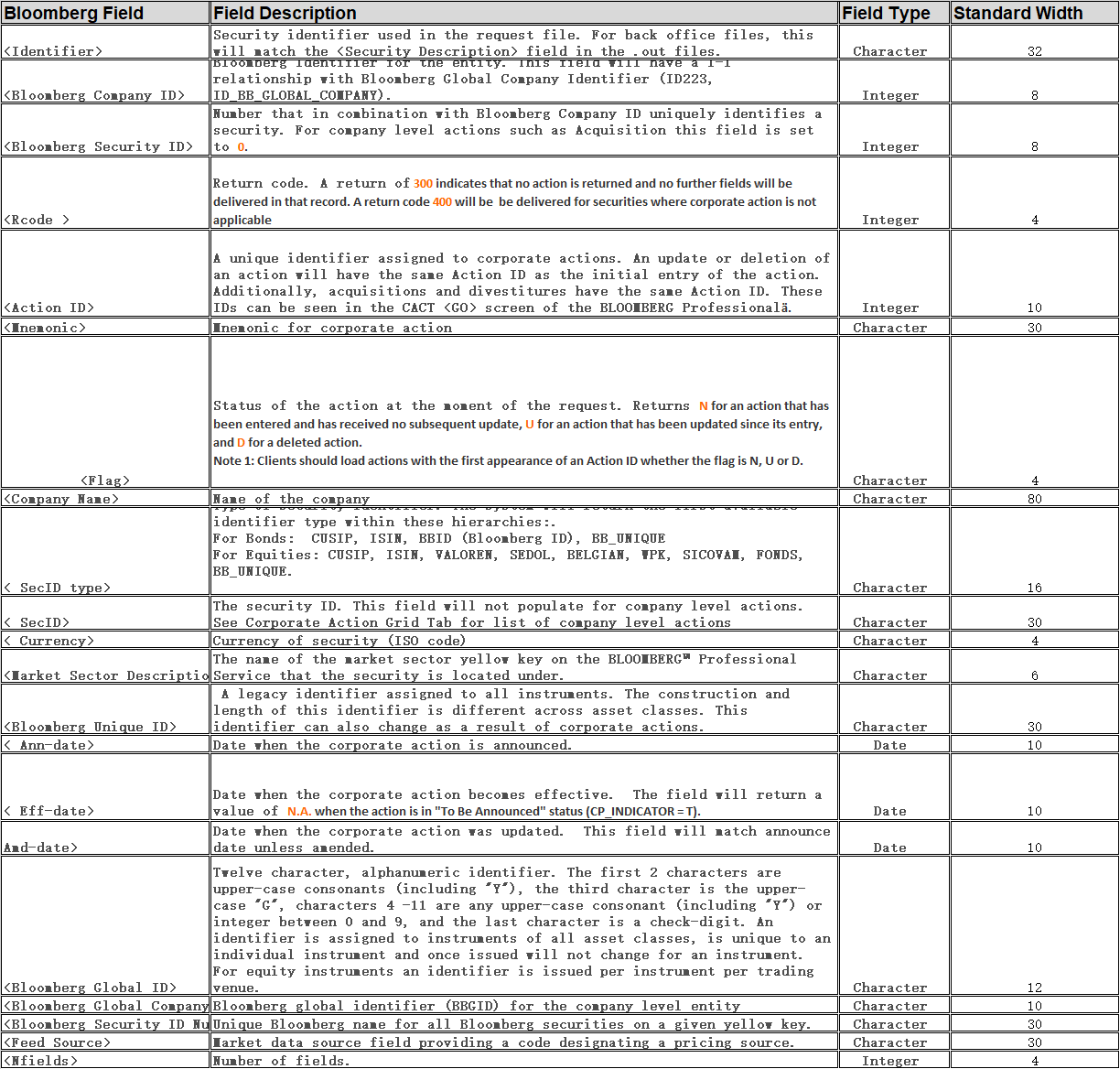
将所有的.cax文件对应的表名,与"Bloomberg Field"列的值做笛卡尔积,导入BB_TABLES 的bb_table_name、bb_field_name .字段的顺序导入到 field_order。
导入时将"Bloomberg Field"列空格替换为"_".去掉"<" 、 ">"
2.2.2 导入sheet:5115-part II
sheet 部分内容截图如下:

将所有的_CAX 结尾的表与”Action Mnemonic“和” FieldMnemonic“ 做笛卡尔积、拼接成新的表及field。
如表xxx_cax 与 ACQUIS 拼接成:
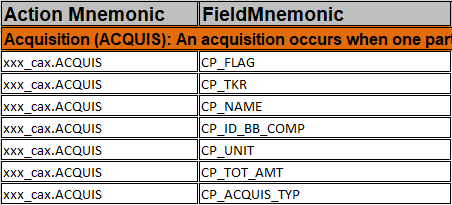
Action Mnemonic 做为bb_table_name,FieldMnemonic 做为bb_field_name .字段的顺序做为field_order 导入到BB_TABLES中。
2.2.根据bb_table_name、bb_field_name生成table_name、field_name
update bb_tables set table_name = BB_table_name; update bb_tables set table_name = replace(table_name,'%','') where instr(table_name,'%')>0; update bb_tables set table_name = replace(table_name,'/','') where instr(table_name,'/')>0; update bb_tables set table_name = replace(table_name,'&','') where instr(table_name,'&')>0; update bb_tables set table_name = replace(table_name,'-','__')where instr(table_name,'-')>0; update bb_tables set table_name = replace(table_name,'.','_') where instr(table_name,'.')>0; update bb_tables set table_name = replace(table_name,'__','_') where instr(table_name,'__')>0; --执行2次,多点没关系 update bb_tables set table_name = substr(table_name,2) where substr(table_name,1,1)='_'; --去掉开头的下划线 update bb_tables set table_name = substr(table_name,1,length(table_name)-1) where substr(table_name,-1)='_'; --去掉结尾的下划线 update bb_tables set table_name ='H_'||table_name where regexp_instr(table_name,'[0-9]')=1; --以数字开头的前面加上"H_" update bb_tables set table_name = substr(table_name,1,24)||substr(table_name,-6) where length(table_name)>30;select distinct table_name,bb_table_name from bb_tables where table_name<>bb_table_name; --检查一下是否修改正确update bb_tables set field_name = BB_field_name; update bb_tables set field_name = substr(field_name,1,length(field_name)-1)||'PRE' where substr(field_name,-1,1)='%'; --最后一个%用pre代替。
update bb_tables set field_name = 'PRE'||substr(field_name,2) where substr(field_name,1,1)='%'; --第一个%用pre代替。 update bb_tables set field_name = replace(field_name,'%','') where instr(field_name,'%')>0;
update bb_tables set field_name = replace(field_name,'#','') where instr(field_name,'#')>0;
update bb_tables set field_name = replace(field_name,'/','') where instr(field_name,'/')>0;
update bb_tables set field_name = replace(field_name,'&','') where instr(field_name,'&')>0;
update bb_tables set field_name = replace(field_name,'-','__')where instr(field_name,'-')>0;
update bb_tables set field_name = replace(field_name,'__','_') where instr(field_name,'__')>0; --执行2次,多点没关系
update bb_tables set field_name = substr(field_name,2) where substr(field_name,1,1)='_'; --去掉开头的下划线
update bb_tables set field_name = substr(field_name,1,length(field_name)-1) where substr(field_name,-1)='_'; --去掉结尾的下划线
update bb_tables set field_name ='H_'||field_name where regexp_instr(field_name,'[0-9]')=1; --以数字开头的前面加上"H_"
update bb_tables set field_name = substr(field_name,1,24)||substr(field_name,-6) where length(field_name)>30;
select distinct field_name,BB_field_name from bb_tables where field_name<>BB_field_name; --检查一下是否修改正确
2.3 手工修改一下会重复的表名
--检查重复的表名
select distinct bb_table_name,table_name from bb_tables where table_name in ( select table_name from bb_tables group by table_name
having count(distinct bb_table_name)>1 ) order by 2;
update bb_tables set table_name='FUNDAMENTALS_ASIA2_BSPIT_OUT' where bb_table_name='FUNDAMENTALS_ASIA2_BS_PIT_OUT'; update bb_tables set table_name='FUNDAMENTALS_ASIA2_SARD_OUT2' where bb_table_name='FUNDAMENTALS_ASIA2_SARD_CF_PIT_OUT'; update bb_tables set table_name='FUNDAMENTALS_ASIA2_SBP_OUT' where bb_table_name='FUNDAMENTALS_ASIA2_SARD_BS_PIT_OUT'; update bb_tables set table_name='FUNDAMENTALS_NAMR_SBHP_OUT' where bb_table_name='FUNDAMENTALS_NAMR_SARD_BS_HISTORY_PIT_OUT'; update bb_tables set table_name='FUNDAMENTALS_NAMR_SCHP_OUT' where bb_table_name='FUNDAMENTALS_NAMR_SARD_CF_HISTORY_PIT_OUT'; update bb_tables set table_name='FUNDAMENTALS_NAMR_SIHP_OUT' where bb_table_name='FUNDAMENTALS_NAMR_SARD_IS_HISTORY_PIT_OUT'; update bb_tables set table_name='EQUITYASIA1_CAX_EQYOFFER' where bb_table_name='EQUITYASIA1CORPORATEACTIONSV2_CAX.EQY_OFFER'; update bb_tables set table_name='EQUITYASIA2_CAX_EQYOFFER' where bb_table_name='EQUITYASIA2CORPORATEACTIONSV2_CAX.EQY_OFFER'; update bb_tables set table_name='EQUITYEURO2_CAX_EQYOFFER' where bb_table_name='EQUITYEUROCORPORATEACTIONSV2_CAX.EQY_OFFER'; update bb_tables set table_name='EQUITYLAMR2_CAX_EQYOFFER' where bb_table_name='EQUITYLAMRCORPORATEACTIONSV2_CAX.EQY_OFFER'; update bb_tables set table_name='EQUITYNAMR2_CAX_EQYOFFER' where bb_table_name='EQUITYNAMRCORPORATEACTIONSV2_CAX.EQY_OFFER';
update bb_tables set table_name='FUNDAMENTALS_ASIA1_SCP_OUT' where bb_table_name='FUNDAMENTALS_ASIA1_SARD_CF_PIT_OUT';
update bb_tables set table_name='FUNDAMENTALS_ASIA2_IHP_OUT' where bb_table_name='FUNDAMENTALS_ASIA2_IND1_HISTORY_PIT_OUT';
update bb_tables set table_name='FUNDAMENTALS_ASIA2_SBH_OUT' where bb_table_name='FUNDAMENTALS_ASIA2_SARD_BS_HISTORY_OUT';
update bb_tables set table_name='FUNDAMENTALS_ASIA2_SCH_OUT' where bb_table_name='FUNDAMENTALS_ASIA2_SARD_CF_HISTORY_OUT'; 三. 字段类型导入
3.1 将bloomberg提供的《fields.csv》中的内容导入到oracke中。
表名为bb_fields,额外增加三个列:
oracle_type varchar2(50), --对应到oracle中的类型 oracle_field_name varchar2(50), --对应到oracle的字段名称
bb_type_src varchar2(100) --这些字段的导入源
其中 bb_type_src='fields.csv'
3.2 将bloomberg提供的《Harvest Bulk File Field Layout.xlsx》中的内容导入到bb_fields中
仅需要导入 《5115-part I》《5115-part 2》两个sheet中的内容.导入后需要过滤一下同名的field
3.3 构建bb_types对应到oracle中的字段名称和字段类型
根据 bb_fields中的 filed_type、standard_width、standard_decimal_places 来构造出oracle_type.
update bb_fields set oracle_type='Real' where bb_type_src='fields.csv' and field_type='Real'; update bb_fields set oracle_type='number(30,6)' where bb_type_src='fields.csv' and field_type='Price'; update bb_fields set oracle_type='varchar2(20)' where bb_type_src='fields.csv' and field_type='Time'; update bb_fields set oracle_type='varchar2(30)' where bb_type_src='fields.csv' and field_type='Month/Year'; update bb_fields set oracle_type='CLOB' where bb_type_src='fields.csv' and field_type='Bulk Format'; update bb_fields set oracle_type='CLOB' where bb_type_src='fields.csv' and field_type='Long Character'; update bb_fields set oracle_type='number(4)' where bb_type_src='fields.csv' and field_type='Boolean'; update bb_fields set oracle_type='number(10)' where bb_type_src='fields.csv' and field_type='Integer'; update bb_fields set oracle_type='DATE' where bb_type_src='fields.csv' and field_type='Date'; update bb_fields set oracle_type=(case when CURRENT_MAXIMUM_WIDTH>2000 then 'CLOB' else 'VARCHAR2('||CURRENT_MAXIMUM_WIDTH||')' end) where bb_type_src='fields.csv' and field_type='Character'; update bb_fields set oracle_type='varchar2(30)' where bb_type_src='fields.csv' and field_type='Date or Time'; update bb_fields set oracle_type='rela' where bb_type_src='fields.csv' and field_type='Integer/Real';
然后再根据命名规则,生成oracle_field_name
update bb_fields set oracle_field_name = field_mnemonic update bb_fields set oracle_field_name = substr(oracle_field_name,1,length(oracle_field_name)-1)||'PRE' where substr(oracle_field_name,-1,1)='%'; --最后一个%用pre代替。 update bb_fields set oracle_field_name = replace(oracle_field_name,'%','') where instr(oracle_field_name,'%')>0; update bb_fields set oracle_field_name = replace(oracle_field_name,'/','') where instr(oracle_field_name,'/')>0; update bb_fields set oracle_field_name = replace(oracle_field_name,'&','') where instr(oracle_field_name,'&')>0; update bb_fields set oracle_field_name = replace(oracle_field_name,'-','_') where instr(oracle_field_name,'-')>0; update bb_fields set oracle_field_name = replace(oracle_field_name,'__','_') where instr(oracle_field_name,'__')>0; update bb_fields set oracle_field_name = substr(oracle_field_name,2) where substr(oracle_field_name,1,1)='_'; update bb_fields set oracle_field_name = substr(oracle_field_name,1,length(oracle_field_name)-1) where substr(oracle_field_name,-1)='_'; update bb_fields set oracle_field_name ='H_'||oracle_field_name where regexp_instr(oracle_field_name,'[0-9]')=1; --以数字开头的前面加上"H_" update bb_fields set oracle_field_name = substr(oracle_field_name,1,24)||substr(oracle_field_name,-6) where length(oracle_field_name)>30;select oracle_field_name,field_mnemonic from bb_fields where oracle_field_name<>field_mnemonic;
3.4 检查一下是否有字段无法找到对应的类型
select distinct bb_field_name,field_name from bb_tables t where not exists(select 1 from bb_fields s where t.bb_field_name=s.bb_field_name);
匹配不上反馈给bloomberg处理。我这里临时把匹配不上的统一改为类型varchar2(1999)
3.5 建表
-- Created on 2019/5/22 by YUBLdeclare-- Local variables herev_sql_cmd clob:='';v_current_tbname varchar2(30):='';v_pre_tbname varchar2(30):='';v_loopup_num number(10):=0;v_field_name varchar2(100);
cursor sp_cursor isselect a.table_name,a.field_name,b.oracle_typefrom bb_tables aleft join bb_fields b on a.field_name=b.field_mnemonicwhere not exists(select 1 from user_tables where table_name=a.table_name)order by 1,2;beginfor v_row in sp_cursor loopv_loopup_num :=v_loopup_num+1;v_current_tbname:=v_row.table_name; if v_loopup_num=1 thenv_sql_cmd:='create table '||v_current_tbname||'(';end if;v_field_name:=v_row.field_name; if regexp_instr(v_row.field_name,'[0-9]')=1 thenv_field_name:='C'||v_row.field_name;end if; if length(v_field_name)>30 thenv_field_name:=substr(v_field_name,1,24)||substr(v_field_name,-6);end if; if v_current_tbname<>v_pre_tbname then v_sql_cmd:=v_sql_cmd||'HCREATETIME DATE DEFAULT SYSDATE,HUPDATETIME DATE)'; BEGIN execute immediate v_sql_cmd;exceptionwhen OTHERS thendbms_output.put_line(v_sql_cmd);END;v_sql_cmd:='create table '||v_current_tbname||'('; end if;v_sql_cmd:= v_sql_cmd||' '||v_field_name||' '||nvl(v_row.oracle_type,'varchar2(1999)')||','; v_pre_tbname:=v_current_tbname;end loop; end;
如果output中有打印出建表语句,把这些复制出来检查为什么无法创建。
四 主键信息导入
4.1 新建表:bb_table_key_columns 用于存储每个表的主键信息
CREATE TABLE BB_TABLE_KEY_COLUMNS ( BB_TABLE_NAME VARCHAR2(100), BB_KEY_COLUMN VARCHAR2(100), TABLE_NAME VARCHAR2(100), KEY_COLUMN VARCHAR2(100) )
4.2 将《Harvest Bulk File List.xlsx》sheet:File List的内容导入,部分内容截图如下:
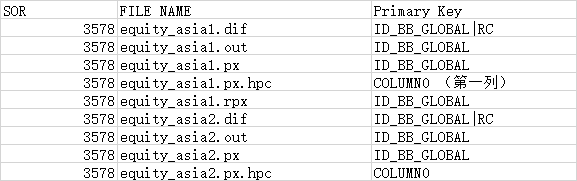
将file_name、primary key 分别导入到bb_table_name、bb_key_column中。parimary key 要按“|”分隔后导入。
注意:
文件中有些主键的信息是错误 的。比如:idbbcompany 要改成:ID_BB_COMPANY






